Day 9: SEO and HTML, Optimizing Your Webpage for Search Engines
HTML SEO tags are snippets of code that help communicate information about content to search engines. They allow us to emphasize key sections of text, describe images, and provide guidance to search engine bots.
These tags also play a crucial role in shaping how webpages are displayed in search results. By using specific tags, we can improve the likelihood of transforming standard search snippets into rich or even featured snippets. As these snippets become more detailed, HTML SEO tags can enhance a page’s SERP rankings and drive more traffic.
Here, we will discuss the most important tags that can enhance your SEO strategy:
Title tag:
Search engines use title tags to identify the topic of a page and show it in the SERP. In HTML, a title tag appears as follows:
In case you have a famous brand, it is a keen to use it in the title. When users skim the results page, they will be more likely to choose something they recognize.
Meta Description Tag:
A meta description is a brief text summary that describes your page in search results. In HTML, it is written as follows:
While the meta description is not a direct ranking factor, it can still contribute to your search success. A relevant and appealing meta description can encourage more users to click on your snippet, which may lead Google to improve your ranking position over time.
3. Headings (H1-H6):
Headings (H1-H6) are used to divide your page into sections or chapters, serving as sub-titles within the content. In HTML, a heading is written like this:
Your heading goes here
Source: SEO PowerSuite
With the introduction of passage indexing in 2021, Google can treat specific sections of your page as individual search results. So, if your headings are optimized for search, each of them is eligible to become a separate search result. It’s basically like having pages within pages.
The next time you are working for a client, keep those tips in mind to optimize your website for Google’s search engine. Happy Coding!
Imagine this: You launch an exciting marketing campaign, but as traffic starts flowing to your website, you’re left wondering—which platform sent them? Was it your newsletter, Facebook ad, or that new affiliate link? Without proper tracking, it’s like trying to solve a puzzle with missing pieces. That’s where UTM parameters and hidden inputs step in as your behind-the-scenes heroes.
What is an HTML Hidden Input?
Web developers often need to send information through forms that users don’t need to see or modify. Enter the HTML hidden input: a sneaky yet powerful tool that allows data to travel invisibly under the hood. Here’s a quick example:
<inputtype="hidden">
But what makes this little line of code so indispensable? It’s particularly useful when working with UTM parameters—tiny tags that unlock big insights for marketing campaigns.
What Are UTM Parameters?
Let’s break it down: UTM parameters are tags you add to your URLs to track the performance of your campaigns. They act like digital breadcrumbs, showing you where your traffic is coming from, what’s working, and what’s not.
When a user interacts with your form or website via a marketing campaign, UTM parameters capture the details and often store them in a hidden input field. This allows the server to connect form submissions directly to the campaign that drove them, giving you a crystal-clear view of your marketing efforts.
But what makes this little line of code so indispensable? It’s particularly useful when working with UTM parameters—tiny tags that unlock big insights for marketing campaigns.
The UTM Parameter Breakdown
Here are the five core UTM parameters and how they work:
utm_source Identifies where the traffic comes from.
This link tells you everything—it’s part of a Google ad campaign for a spring sale, targeting keywords like “running shoes,” and specifically tracking clicks on a text link.
Companies leverage UTM parameters for two major reasons:
Generate Unique Links Tools like Google’s Campaign URL Builder make it easy to create customized UTM links for each campaign, affiliate, or creator.
Track with Analytics
Set up goals in tools like Google Analytics to monitor conversions.
Filter reports by parameters like utm_source or utm_campaign to measure success.
By effectively tracking these metrics, companies can identify high-performing strategies and pay creators accordingly. It’s a win-win—data for businesses and fair compensation for creators.
Today in my 100daysofcode challenge, I explored a fascinating concept in web development—Blobs. If you’ve ever downloaded a file from a website, chances are you’ve interacted with blobs without realizing it. In the world of JavaScript, blobs are a powerful way to handle binary data, making them essential for creating downloadable content dynamically.
A Blob (Binary Large Object) is a data type in JavaScript that represents raw binary data. It’s often used to store and manipulate large files like images, videos, or even text. The best part? You can create blobs on the fly and let users download files directly from your web app without needing a server.
Creating and Downloading a Blob
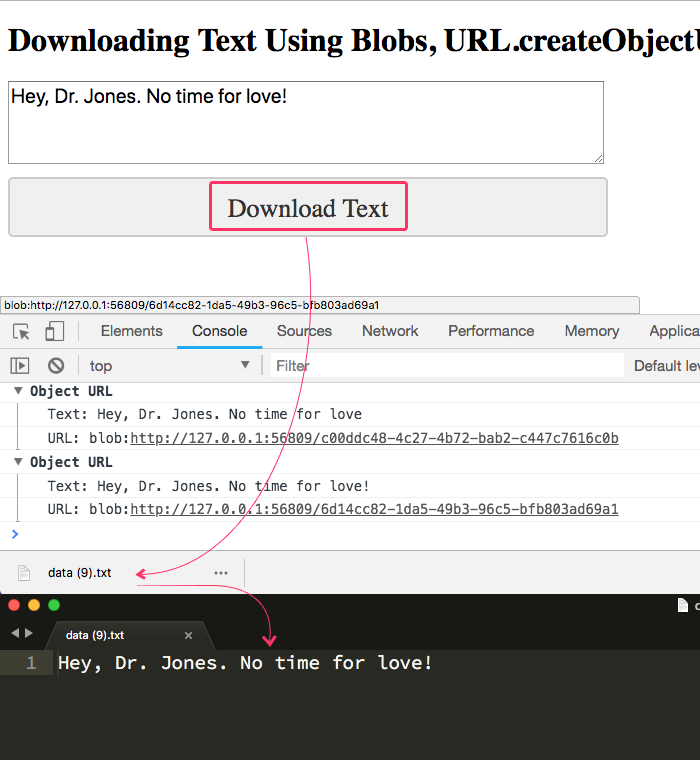
Here’s a simple example of how to use blobs to generate and download a file:
Step 1: Create a Blob
Start by creating a blob object. This could be plain text, JSON, or even a CSV file:
const data = "Hello, World! This is a Blob file.";
const blob = new Blob([data], { type: "text/plain" });
Step 2: Create a Download Link
To make the file downloadable, create a link dynamically and attach the blob to it:
javascript
CopyEdit
const link = document.createElement("a");
link.href = URL.createObjectURL(blob);
link.download = "example.txt"; // The name of the downloaded file
link.click();
This will prompt the user to download a file named example.txt containing your blob data.
Real-World Use Cases
Exporting Data
Blobs can be used to let users export their data as a CSV or JSON file.
Generating PDFs or Images
Combine blobs with libraries like jspdf or html2canvas to dynamically generate PDFs or screenshots.
File Upload Previews
Use blobs to preview uploaded images or videos before sending them to the server.
Day 12: Javascript for People Who Think They’re Bad at It
If JavaScript has ever made you feel like you’re bad at coding, you’re not alone. It’s a weird language—quirky, unpredictable, and honestly a little dramatic. But the thing is, it’s not you. JavaScript just takes time to get used to.
Take == vs. ===, for example. Why does "5" == 5 work, but "5" === 5 doesn’t? The first one just checks if the values are kind of the same (ignoring types), while the second one checks everything, including type. So, always stick to === unless you want surprises.
Or how about this? It changes depending on how a function is called, which is why something like this breaks:
const person = {
name: "Sara",
greet: function () {
console.log(this.name);
},
};
const greet = person.greet;
greet(); // undefined
When you call greet() on its own, it has no clue what this should point to. Annoying, right?
And don’t even get me started on async code. If you’re still writing something like:
And wondering why it doesn’t work, remember: JavaScript doesn’t wait for fetch() to finish. You need to use await (and maybe try...catch so it doesn’t explode on errors).
Here’s the thing: JavaScript isn’t something you “master” overnight. It’s more like an unpredictable roommate—you learn to live with it, quirks and all.
One of the common mistakes novice developers make when developing apps or websites is storing images directly in their databases. While this might seem like an easy option, it can quickly lead to performance issues as your app grows. Storing large files like images in a database bloats the system, slows down queries, and makes backups more cumbersome. The best approach is to offload image storage to a cloud provider like AWS, Google Cloud, or Azure and store only the image URLs in your database.
Here’s why it’s a better solution: cloud storage services are designed for high performance, scalability, and durability. They offer fast access to your files without bogging down your database. For example, AWS S3 (Simple Storage Service) is one of the top choices, providing reliable, scalable, and secure storage for images. Plus, you only pay for what you use, which is much more cost-effective than increasing your database size.
How to use AWS S3 for storing images:
Create an AWS Account: First, you’ll need an AWS account. Go to the AWS website and sign up if you don’t have an account already.
Create an S3 Bucket: Once you’re logged in, navigate to the S3 service and create a new bucket. A bucket is just a container for your files. You can choose your region and configure permissions (be sure to set it to public or private depending on your needs).
Upload Your Image: After your bucket is created, you can upload images either through the AWS console or programmatically via the AWS SDK (for example, using Python or Node.js). Once uploaded, each image will have a URL that can be used to reference it.
Store the URL in Your Database: Now, instead of storing the image itself, store the URL in your database. For example, if you uploaded an image called “product1.jpg,” AWS will provide a URL like https://your-bucket-name.s3.amazonaws.com/product1.jpg. You can then reference this URL in your database as part of the image’s metadata.
Access the Image from Your App or Website: With the URL stored, your app or website can easily retrieve and display the image whenever needed by linking directly to the URL. This keeps your database size small and your app running smoothly.
By using cloud storage like AWS S3, you’re ensuring that your app is scalable, cost-effective, and that your database remains focused on what it’s designed to do—store structured data efficiently.
Authorization and authentication are two distinct processes often used interchangeably, but they serve different purposes. Authentication verifies a user’s identity, while authorization ensures that the authenticated user has access to the requested resources. In this article, we focus on how authorization is implemented and compare the traditional session-based approach with modern JWT-based methods.
What is Authorization?
Authorization is the process of confirming that the user making a request to the server is the same user who successfully logged in during the authentication phase. It ensures that the user has the necessary permissions to access specific resources or perform actions.
How it Used to Be Done: Session-Based Authorization
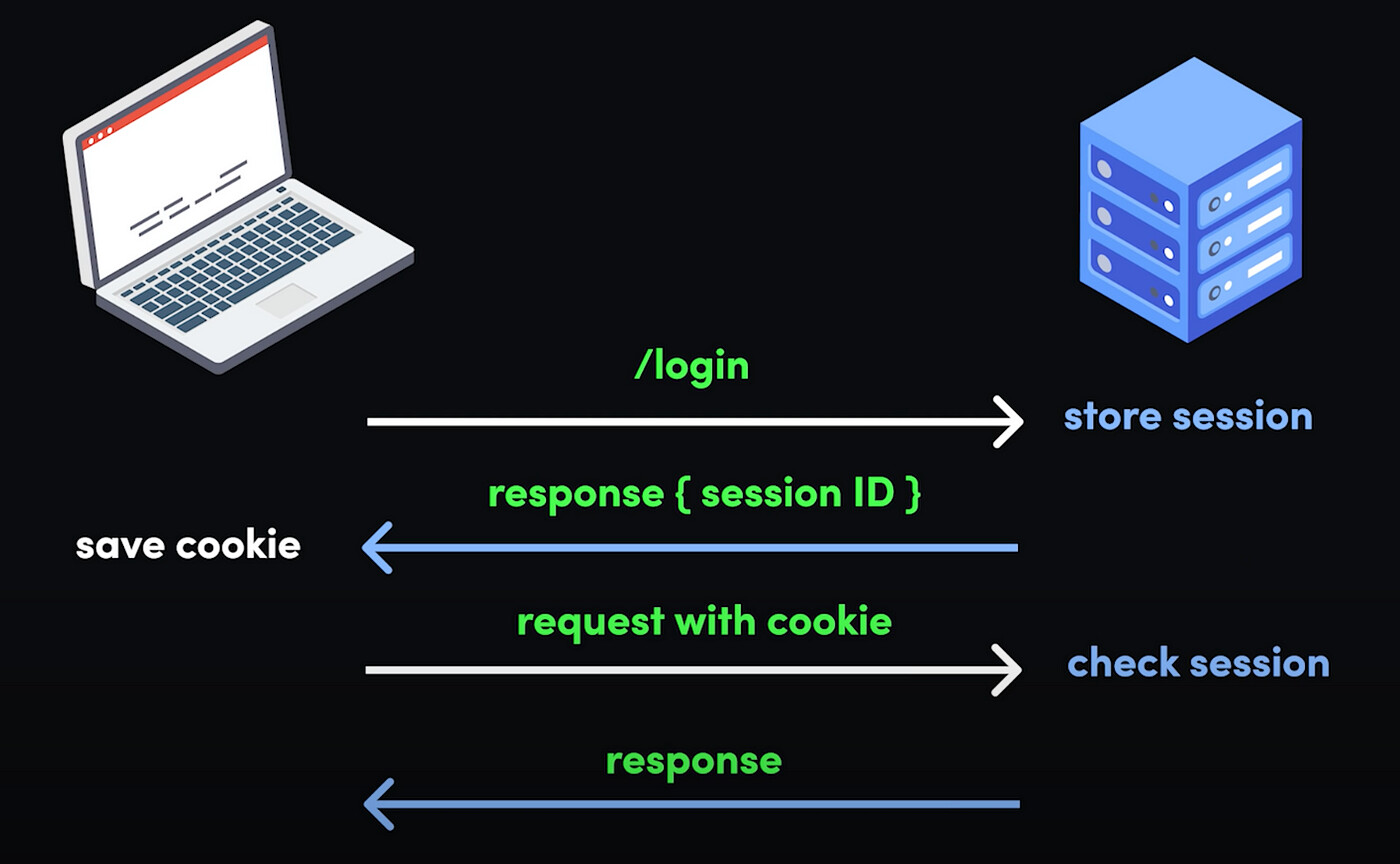
In traditional web applications, authorization relied on server-side sessions. Here’s how it worked:
When a user logged in, the server created a session and generated a session ID.
The session ID was stored on the server and sent to the user’s browser via cookies.
For every subsequent request, the client sent the session ID back to the server.
The server looked up the session ID in its memory, retrieved the associated user information, and verified the user’s access rights.
This approach required the server to manage and store session data, which could become resource-intensive as the number of users grew.
This approach required the server to manage and store session data, which could become resource-intensive as the number of users grew. While effective, it had limitations, especially when scaling applications or supporting stateless architectures.
But what if there was a way to eliminate the need for the server to store session data? A method that could make the system more efficient and scalable?
I’ll leave you at a cliffhanger to learn tomorrow about JWT and how it revolutionizes authorization in modern applications.
A user makes a POST request with their credentials, which is sent to the server, just like session-based authentication. Instead of storing information on the server inside session memory, the server creates a JSON Web Token (JWT), which it encodes, serializes, and signs with its own secret key. A JWT consists of three parts: the header, the payload, and the signature
Header: This contains metadata about the token, such as the algorithm used for signing (e.g., HS256) and the type of token (e.g., JWT).
{"alg":"HS256","typ":"JWT"}
Payload: This contains the claims, which are pieces of information about the user or token, like the user ID, role, and token expiration time.
The server can later verify the token’s integrity by recalculating the signature using the header, payload, and its secret key, ensuring no tampering occurred.
So, in the session-based method the server had to do a lookup operation to find the user based on their session ID. In contrast, the JWT already stores the user information which means it’s stored on the client-side and won’t run into problems where one server has session info and others don’t.
When it comes to building modern web applications, developers often rely on frameworks to streamline development and enhance functionality. Three of the most popular frameworks today are React, Angular, and Vue.js, each offering distinct advantages depending on the needs of the project.
React, developed by Facebook, is a highly flexible JavaScript library for creating interactive user interfaces. React’s component-based structure allows developers to break down a web app into reusable components, making code more maintainable and scalable. It uses a virtual DOM to optimize updates to the user interface, improving performance and speeding up rendering. The React ecosystem also provides various additional tools and libraries, such as React Router for navigation and Redux for state management, making it suitable for large-scale applications that require dynamic content.
Angular, created by Google, is a full-fledged framework that provides a comprehensive solution for building complex, data-driven web applications. Unlike React, Angular is an all-in-one framework that handles everything from UI rendering to data management and routing. Its two-way data binding feature keeps the model and view synchronized in real time, which is particularly useful for applications with complex user interactions. Angular is often the framework of choice for enterprise-level applications due to its robustness, modularity, and strong community support.
Vue.js, designed by Evan You, is known for being lightweight and easy to integrate into projects. Vue provides a balance between the flexibility of React and the comprehensive features of Angular. It uses a component-based structure and a virtual DOM similar to React but includes additional built-in functionalities, such as its own routing system and state management library, Vuex. Vue is especially appealing to developers who want a simple yet powerful framework that can be easily integrated into existing projects without a steep learning curve.
Each of these frameworks excels in different scenarios, making them suitable for various types of web applications. React is best for projects that require a lot of interactivity and flexibility, Angular is ideal for enterprise applications with complex needs, and Vue.js strikes a perfect balance for developers looking for simplicity and ease of integration.
A few years ago, a friend of mine was building a startup. He was excited about using the latest tech stack—everything was serverless, NoSQL, and designed to scale. But six months in, his team realized they had a problem: retrieving data was a nightmare. Querying across collections in MongoDB required writing complex aggregation pipelines, and enforcing data integrity meant adding application-level checks. Eventually, they switched back to a relational database—SQL saved them.
This story isn’t unique. As NoSQL databases like MongoDB and Firebase gain popularity, many developers assume that SQL is outdated. But despite the hype, SQL databases remain a crucial tool in modern development. Here’s why they still matter.
The Reliability of Structured Data
Imagine you’re running a financial application where every transaction must be recorded accurately. Would you trust a database that prioritizes speed over consistency? SQL databases enforce ACID compliance (Atomicity, Consistency, Isolation, Durability), ensuring that transactions are reliable and secure. NoSQL databases, on the other hand, often trade consistency for scalability, making them less suitable for industries like finance, healthcare, and legal compliance.
A Universal Query Language
SQL isn’t just a database; it’s a language that has stood the test of time. Whether you’re working with MySQL, PostgreSQL, or Microsoft SQL Server, you’re using the same structured query language. This universality makes it easier to switch between systems and hire skilled professionals. In contrast, NoSQL databases use different query mechanisms—MongoDB has its own syntax, Firebase relies on document-based retrieval, and Cassandra uses CQL. Learning each of these can be time-consuming and frustrating.
Scalability: The NoSQL Myth
One of the biggest reasons people switch to NoSQL is scalability. Facebook, Google, and Amazon all use NoSQL, so it must be better, right? Not necessarily. Modern SQL databases have evolved to include horizontal scaling, sharding, and partitioning, allowing them to handle massive workloads. Cloud-based SQL solutions like Amazon RDS and Google Cloud SQL make scaling as easy as clicking a button. Unless you’re operating at the scale of Netflix, SQL can handle your needs just fine.
The Power of Relationships
Ever wondered why e-commerce platforms, banking systems, and enterprise applications stick with SQL? It’s because of data integrity and relationships. SQL databases use foreign keys and constraints to ensure that related data stays accurate. NoSQL databases, which often store denormalized data, require developers to enforce relationships at the application level, leading to more complexity and potential errors.
Analytics and Reporting
Businesses run on data, and data-driven decisions require powerful analytics. SQL databases are optimized for reporting, supporting complex queries, OLAP (Online Analytical Processing), and integration with tools like Power BI and Tableau. NoSQL databases, designed for fast reads and writes, struggle with deep analytical queries without additional processing layers.
Regulatory and Security Advantages
If you’re working in industries with strict regulatory requirements—such as GDPR, HIPAA, or SOX—SQL databases are often the better choice. They offer robust security features like role-based access control, encryption, and audit logs, ensuring compliance with legal frameworks.
The Best of Both Worlds
This isn’t to say NoSQL is useless. For applications requiring flexibility, high-speed reads, and distributed storage, NoSQL databases shine. But for structured, transactional, and analytical applications, SQL remains king. In fact, many modern systems adopt a hybrid approach, using SQL for core business logic and NoSQL for caching or real-time features.
Conclusion: SQL Isn’t Going Anywhere
While NoSQL databases have revolutionized how we store and manage data, SQL isn’t fading into obscurity. Instead, it’s evolving. If your application demands data integrity, strong relationships, powerful querying, and compliance, SQL is still the best tool for the job. The database world isn’t about choosing one over the other—it’s about understanding when to use the right tool for the right job.
So next time you’re tempted to ditch SQL for the latest trend.
Day 18: Understanding the Role of NoSQL in the IoT Revolution
The rapid expansion of the Internet of Things (IoT) has generated an immense volume of data, produced by millions of interconnected devices. This data, characterized by its variety, velocity, and volume, presents unique challenges for traditional relational databases, which were designed for structured and predictable datasets.
Take, for example, a smart agriculture system that initially tracks soil moisture and temperature but later integrates sensors for pH levels and nutrient content. With a traditional SQL database, the addition of new data points can easily disrupt existing workflows or require a major overhaul of the database structure.
This adaptability is essential for IoT systems, where innovation and change are constants. As IoT continues to evolve, the need for more agile, scalable, and efficient data management solutions has become crucial. So, NoSQL databases, which offer unparalleled flexibility and scalability, have emerged as an effective alternative for handling the dynamic and ever-growing nature of IoT data.
NoSQL databases such as MongoDB and Cassandra, on the other hand, offer schema flexibility, allowing new data fields to be added dynamically without requiring modifications to the existing structure. This flexibility makes NoSQL solutions a perfect fit for managing IoT data, as it can continuously evolve alongside new sensor types, data formats, and use cases. For example, a smart building’s HVAC system generates constant data streams, such as temperature, humidity, airflow, and occupancy levels, transmitted every few milliseconds. In such cases, the rigid and predefined schemas of relational databases are impractical for accommodating the unpredictable and dynamic nature of IoT data.
Another defining characteristic of IoT data is its high ingestion rate. Millions of devices generate massive data streams simultaneously, creating a need for a database architecture capable of handling such workloads without performance degradation. NoSQL databases, particularly those built with distributed architectures, excel in this area because of their horizontal scaling. This means that as the volume of data increases, additional servers can be added to maintain performance levels.
Rather than viewing SQL and NoSQL as competing technologies, it is essential to recognize that they are tools designed for different applications. Both can coexist within a modern data architecture, each optimized for its specific use case. The decision between SQL and NoSQL should ultimately be driven by the nature of the data, the requirements of the application, and the scalability needed.
A friend of mine, returning from vacation, noticed an unexpected pattern in his Whoop data—despite consistently logging the recommended 7-8 hours of sleep a night, his Whoop recovery scores remained below 75%. However, after catching up on rest during his trip, his metrics improved significantly, revealing a deeper level of sleep deprivation than he had realized. This was a relief to me, for I felt like 8 hours weren’t enough for me either.
Rather than accepting advice at face value, let’s see what Whoop has to say. At the heart of Whoop’s functionality is its ability to process large volumes of unstructured sensor data in real time. The device integrates multiple sensors, capturing continuous streams of physiological signals. Whoop isn’t just a fitness tracker—it’s a data-driven system that transforms those raw biometric signals into meaningful insights. By continuously capturing physiological data like heart rate variability (HRV), motion, and breathing patterns, it doesn’t just monitor sleep but understands it.
The real power lies in how machine learning algorithms make sense of these patterns, uncovering trends that would be impossible to detect manually. Instead of using rigid cutoffs to classify sleep stages, models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks analyze sequential data to predict transitions between sleep phases. Meanwhile, gradient boosting algorithms refine recovery scores by learning from historical patterns, optimizing training loads based on individual responses. But the true potential extends beyond a single user—through transfer learning, insights gained from one population can be adapted to another, refining models across diverse datasets. Isn’t that amazing?
For computer scientists, this presents an exciting frontier: how do we scale these insights beyond individuals to uncover population-level trends? Analyzing vast datasets enables researchers to explore how sleep, recovery, and exertion vary across demographics, lifestyles, and even geographic regions. With cloud-based analytics and reinforcement learning, systems like Whoop continuously evolve, learning from user behavior to refine recommendations.
But this isn’t just about personal optimization—it’s about decoding human performance at scale, using machine learning to reveal patterns we never knew existed. For those in the field, the challenge lies in designing models that not only predict but also adapt, ensuring insights remain meaningful across diverse populations.
I’ve always loved stories. But as a computer scientist, I get to write the code that tells them in ways we’ve never seen before.
Oh, and by the way, I now sleep 9.5 hours guilt-free—Whoop says it’s okay.
Day 20: 4 Small Node.js API Projects to Kickstart Your Learning
If you’re diving into APIs with Node.js, building small projects is the best way to solidify your understanding. Here are four beginner-friendly projects that cover different aspects of API development, from handling requests to working with external libraries.
1. URL Shortener
What You’ll Learn: Express routing, database integration, and URL handling.
Create an API that shortens long URLs and redirects users when they access the short version. Use a database like MongoDB or a simple JSON file to store mappings between short and long URLs. This project helps you understand CRUD operations and URL handling in APIs.
2. Rate Limiter (Protection Against Cyber Attacks)
What You’ll Learn: Middleware, security, and request limiting.
Implement a rate limiter API that prevents excessive requests from a single IP address within a certain timeframe. Use libraries like express-rate-limit to control access and protect against brute-force attacks. This project introduces you to API security and middleware usage.
3. PDF Merger
What You’ll Learn: File handling, working with external libraries, and HTTP uploads.
Build an API that accepts multiple PDF files and merges them into one. Use libraries like pdf-lib or pdf-merger-js to combine files. This project teaches you how to handle file uploads and process documents on the backend.
4. YouTube Downloader
What You’ll Learn: Working with third-party APIs, streaming, and file downloads.
Develop an API that downloads YouTube videos as MP4 or MP3 files using ytdl-core . Users can provide a YouTube URL, and the API will return a downloadable file. This project gives you experience with external APIs, response streaming, and file handling.
Final Thoughts
Each of these projects introduces key API development concepts while keeping things manageable for beginners. Once you complete them, try adding authentication, caching, or deploying them online to gain more real-world experience. Happy coding!
Day 21: Unlocking the Power of Clustering Algorithms in E-Commerce
In the fast-paced world of e-commerce, understanding customer behavior is crucial for success. One powerful tool that helps businesses make sense of vast amounts of data is clustering algorithms—a type of machine learning that groups similar data points together. But how exactly does this work, and why is it important for online stores?
What Is a Clustering Algorithm?
Clustering is an unsupervised learning technique that automatically detects patterns in data by grouping similar items together. Popular clustering algorithms include K-Means, DBSCAN, and Hierarchical Clustering, each with unique strengths in handling different types of data.
How Clustering Improves E-Commerce
Customer Segmentation: By analyzing purchasing behavior, clustering can categorize customers into distinct groups—such as budget shoppers, luxury buyers, or frequent purchasers—allowing for personalized marketing strategies.
Product Recommendations: Clustering helps identify items often bought together, enhancing recommendation engines to suggest relevant products, increasing cross-selling and upselling opportunities.
Dynamic Pricing: By grouping customers based on purchasing power, stores can implement targeted pricing strategies to maximize sales and customer retention.
Fraud Detection: Clustering algorithms can detect unusual spending patterns, flagging potential fraudulent transactions for further review.
Inventory Management: Retailers can group products based on demand trends, ensuring optimal stock levels and reducing waste.
The Future of Clustering in E-Commerce
As artificial intelligence advances, clustering algorithms will become even more refined, enabling hyper-personalized shopping experiences and smarter business strategies. For e-commerce stores, leveraging clustering isn’t just an advantage—it’s a necessity in the age of data-driven retail.
Would you like a deeper dive into any of these applications?
Day 22: # Unlocking the Secrets of Node.js: How the Event Loop and Asynchronous Magic Power Modern Apps
Node.js, the JavaScript runtime that powers everything from startups to tech giants like Netflix and LinkedIn, is built on a foundation of asynchronous programming. But what makes it so fast and efficient? The answer lies in two key concepts: the Event Loop and Advanced Asynchronous Patterns. Let’s break down the science behind these powerful mechanisms.
1. The Event Loop: The Brain of Node.js
At the core of Node.js is the Event Loop, a single-threaded, non-blocking mechanism that allows it to handle thousands of simultaneous connections with ease. Here’s how it works:
The Phases of the Event Loop
The Event Loop operates in a series of phases, each responsible for specific tasks:
Timers: Executes callbacks scheduled by setTimeout and setInterval.
Pending Callbacks: Handles I/O callbacks deferred to the next loop iteration.
Poll: Retrieves new I/O events and executes their callbacks.
Check: Executes setImmediate callbacks.
Close Callbacks: Handles cleanup tasks, like closing sockets.
This cyclical process ensures that Node.js can juggle multiple tasks efficiently without getting bogged down.
Microtasks vs. Macrotasks
The Event Loop also distinguishes between microtasks (e.g., Promise callbacks) and macrotasks (e.g., setTimeout). Microtasks are executed immediately after the current operation, while macrotasks wait for the next cycle. This prioritization ensures that critical tasks are handled promptly.
The Danger of Blocking the Loop
While the Event Loop is powerful, it’s not invincible. Long-running synchronous code can block the loop, causing delays. To avoid this, developers use techniques like offloading tasks to worker threads or leveraging asynchronous APIs.
Node.js has evolved far beyond simple callback functions. Today, developers use advanced patterns to write cleaner, more efficient code. Here are some of the most powerful techniques:
Promises and Async/Await
Promises and async/await have revolutionized asynchronous programming in Node.js. Promises allow you to chain operations and handle errors gracefully, while async/await makes asynchronous code look and behave like synchronous code. For example:
This approach simplifies complex workflows and improves readability.
Event Emitters: The Power of Events
Node.js’s EventEmitter class enables event-driven programming, where actions trigger specific events. This pattern is ideal for building real-time applications like chat systems or live notifications. For example:
Streams are a cornerstone of Node.js, allowing you to process large datasets piece by piece without loading everything into memory. Whether you’re reading a file or processing real-time data, streams ensure optimal performance. For example:
javascript
Copy
const fs = require(‘fs’); const readStream = fs.createReadStream(‘largefile.txt’); readStream.on(‘data’, (chunk) => { console.log(Received ${chunk.length} bytes of data.); }); readStream.on(‘end’, () => { console.log(‘No more data to read.’); });
Why This Matters
Understanding the Event Loop and advanced asynchronous patterns isn’t just for experts—it’s essential for anyone building modern applications. These concepts enable Node.js to handle massive workloads, deliver real-time experiences, and scale effortlessly.
As the demand for faster, more responsive apps grows, mastering these techniques will be key to staying ahead in the world of software development.
What’s Next?
The world of Node.js is vast, and there’s always more to explore. From worker threads for parallel processing to N-API for building native addons, the possibilities are endless. Stay tuned for more insights into the science of Node.js!
This version is concise, engaging, and written in a style similar to Science Daily. Let me know if you’d like to tweak it further!v
Day 23: The Power of Small Projects: How Building a To-Do List Can Solidify Your Understanding of a New Tech Stack
When learning a new framework or technology stack, it’s tempting to dive headfirst into ambitious, large-scale projects. After all, isn’t that the best way to prove your skills? While big projects can be rewarding, they often come with a steep learning curve and can leave beginners overwhelmed. This is where small, focused projects—like building a to-do list application—come into play. Not only do they provide a manageable way to practice, but they also help solidify your understanding of how different components of a framework tie together. For those learning the MERN stack (MongoDB, Express.js, React, and Node.js), a to-do list is the perfect starting point.
Why Small Projects Matter
Small projects act as building blocks for your knowledge. They allow you to focus on specific concepts without the distraction of unnecessary complexity. For example, a to-do list app might seem simple, but it encapsulates many of the core concepts required to build larger applications. By working on such a project, you can break down the MERN stack into digestible pieces and understand how each part—routes, controllers, models, and front-end components—interacts with the others.
Breaking Down the MERN Stack with a To-Do List
Let’s take a closer look at how building a to-do list app can help you understand the MERN stack:
1. MongoDB: Understanding Data Models
In a to-do list app, you’ll need to store tasks, which might include fields like title, description, dueDate, and completed. This is a great opportunity to learn how to design a simple schema in MongoDB.
By working with MongoDB, you’ll understand how data is structured, how to perform CRUD (Create, Read, Update, Delete) operations, and how to connect your database to your backend using Mongoose (a popular MongoDB ODM for Node.js).
2. Express.js: Routing and Controllers
Express.js is the backbone of the backend in the MERN stack. A to-do list app requires basic routes like:
GET /tasks to fetch all tasks.
POST /tasks to create a new task.
PUT /tasks/:id to update a task.
DELETE /tasks/:id to delete a task.
By implementing these routes, you’ll learn how to structure your backend, handle HTTP requests, and connect routes to controllers. Controllers act as the middle layer between your routes and your database, helping you understand the separation of concerns in backend development.
3. React: Front-End Components and State Management
On the front end, React allows you to build a dynamic user interface. For a to-do list, you’ll create components like TaskList, TaskItem, and AddTaskForm.
You’ll also learn how to manage state using React’s useState or useReducer hooks. For example, when a user adds a new task, you’ll update the state to reflect the change and re-render the component.
This hands-on experience with React will help you understand how to structure components, pass props, and manage user interactions.
4. Node.js: Bringing It All Together
Node.js serves as the runtime environment for your backend. By building a to-do list app, you’ll learn how to set up a Node.js server, handle API requests, and connect your backend to your front end.
You’ll also gain experience with essential tools like npm or yarn for package management and nodemon for automatic server restarts during development.
How It All Ties Together
One of the most challenging aspects of learning a full-stack framework is understanding how the front end, backend, and database interact. A to-do list app provides a clear example of this interaction:
Front End (React): The user interacts with the app by adding, editing, or deleting tasks. These actions trigger API calls to the backend.
Back End (Express.js and Node.js): The backend receives the API requests, processes them (e.g., validating data), and interacts with the database to perform the necessary operations.
Database (MongoDB): The database stores the tasks and sends the requested data back to the backend, which then returns it to the front end.
By building this flow in a small project, you’ll see how data moves through the stack and how each layer depends on the others. This foundational knowledge is crucial before tackling more complex projects.
Conclusion
Before diving into large-scale projects, take the time to build small, focused applications like a to-do list. These projects serve as a practical way to solidify your understanding of the MERN stack and how its components—routes, controllers, models, and front-end logic—work together. By mastering the basics, you’ll be better equipped to tackle more ambitious projects in the future. Remember, every big project is just a collection of small, well-understood pieces working in harmony. Start small, build your knowledge, and watch your skills grow!
Day 24: Framing Your Software Engineering Portfolio as a Solution to Problems
In the competitive field of software engineering, standing out requires more than just showcasing technical skills. Reframing your portfolio as a collection of solutions to real-world problems can make a powerful impression. Employers and clients increasingly value engineers who understand and address user or business pain points, not just those who write code.
Why the Problem-Solution Approach Works
Presenting your projects as solutions shifts the focus from what you built to why it matters. For example, instead of saying, “I built a task management app,” say, “I created a task management app to help remote teams streamline collaboration and reduce missed deadlines.” This approach demonstrates your ability to solve problems and deliver impact.
How to Reframe Your Portfolio
Define the Problem
Clearly state the issue each project addresses. Was it inefficiency, poor user experience, or a lack of tools?
Highlight the Solution
Explain how your project solved the problem. Focus on outcomes, such as improved productivity or user satisfaction.
Showcase Results
Use metrics, testimonials, or visuals to demonstrate the impact of your work.
By framing your portfolio around problems and solutions, you position yourself as a problem-solver, not just a coder—making you a more compelling candidate for jobs, freelance gigs, or entrepreneurial ventures.
Day 26: Why MongoDB is the Future of Scalable Databases
As digital applications grow in complexity and scale, traditional relational databases struggle to keep up. Enter MongoDB—an innovative NoSQL database designed for flexibility, performance, and horizontal scalability.
The Power of Horizontal Scaling
Unlike traditional SQL databases that require vertical scaling (upgrading a single server), MongoDB distributes data across multiple machines through sharding. This means businesses can handle massive workloads by simply adding more servers—an approach used by tech giants like Netflix and eBay to maintain seamless performance.
Schema Flexibility for Modern Applications
MongoDB stores data in BSON (Binary JSON) format, allowing for a dynamic schema. This is particularly useful for AI-driven platforms, IoT, and real-time analytics, where data structures frequently change.
Performance Meets Reliability
With built-in replication and automatic failover, MongoDB ensures data redundancy and high availability. Even if one server fails, data remains accessible—making it a top choice for businesses that require 24/7 uptime.
How Much Does MongoDB Cost?
MongoDB is open-source, but hosting and scaling influence costs. Self-hosted setups require server investments (~$3,000–$5,000 upfront + maintenance). MongoDB Atlas (Cloud) starts free but scales with usage—small applications cost ~$50–$200/month, while enterprise solutions range from $5,000 to $50,000/month, depending on traffic and storage needs.
The Future of Data Management
From startups to enterprises, MongoDB’s ability to scale seamlessly while maintaining speed and reliability makes it a game-changer in database management. As businesses demand more flexibility and performance, MongoDB continues to lead the way.
Day 27: The Future of Web Development: How AI is Reshaping the Digital Landscape
Web development has always been a field defined by rapid evolution, but the rise of artificial intelligence (AI) is accelerating this transformation like never before. From automating repetitive tasks to enabling entirely new ways of building and interacting with websites, AI is poised to redefine how developers work and how users experience the web.
AI-Powered Development Tools
One of the most immediate impacts of AI on web development is the emergence of intelligent tools that streamline the coding process. Platforms like GitHub Copilot and ChatGPT are already helping developers write code faster by generating snippets, debugging errors, and even suggesting entire functions. These tools don’t replace developers—they empower them to focus on creativity and problem-solving rather than boilerplate code.
AI is also making web development more accessible. No-code and low-code platforms, powered by AI, allow non-developers to create functional websites and applications. Tools like Wix ADI and Framer AI use machine learning to design layouts, optimize user experiences, and even generate content, democratizing web development for a broader audience.
Smarter, More Personalized User Experiences
AI is revolutionizing the way users interact with websites. Chatbots and virtual assistants, powered by natural language processing (NLP), are becoming more sophisticated, offering real-time support and personalized recommendations. Meanwhile, AI-driven analytics tools are helping developers understand user behavior in unprecedented detail, enabling hyper-personalized experiences that adapt to individual preferences.
For example, e-commerce sites are leveraging AI to recommend products, optimize search results, and even predict trends. Streaming platforms use AI to curate content, while news websites tailor articles to readers’ interests. This level of personalization is setting a new standard for user engagement.
The Rise of AI-Generated Content
Content creation is another area where AI is making waves. Tools like OpenAI’s GPT-4 and Jasper AI are capable of generating high-quality text, from blog posts to product descriptions. For web developers, this means faster content updates and the ability to scale dynamic websites with ease. However, it also raises questions about authenticity and the role of human creativity in the digital space.
Challenges and Ethical Considerations
While the potential of AI in web development is immense, it’s not without challenges. Concerns about data privacy, algorithmic bias, and the ethical use of AI-generated content are growing. Developers must navigate these issues carefully, ensuring that AI is used responsibly and transparently.
Moreover, as AI tools become more prevalent, the role of web developers may shift. Rather than focusing solely on coding, developers will need to become adept at integrating AI systems, interpreting data, and designing ethical AI-driven experiences.
Where is Web Development Headed?
The integration of AI into web development is still in its early stages, but the trajectory is clear: the future of the web will be smarter, faster, and more personalized. Developers who embrace AI as a tool—rather than a threat—will be at the forefront of this transformation, shaping the next generation of digital experiences.
As AI continues to evolve, one thing is certain: the web will never be the same. Whether you’re a seasoned developer or just starting out, now is the time to explore how AI can enhance your work and redefine what’s possible on the web.
Day 25: ### My Journey from Overthinking to Confident Coding
Introduction
When I first started coding, I wasn’t just writing logic—I was overanalyzing every decision. Was I choosing the right variable name? Was my approach optimal? Would someone judge my code if they saw it? This cycle of overthinking slowed me down and made me feel like I wasn’t good enough.
But over time, I learned to break free from this pattern and code with confidence. In this post, I’ll share what held me back, how I overcame it, and practical steps you can take if you’re struggling with the same thing.
The Problem: Overthinking Everything
As a fresh graduate, I found myself stuck in these thought loops:
“Is my code clean enough?” Instead of focusing on functionality first, I obsessed over writing “perfect” code.
“What if this isn’t the most efficient solution?” I hesitated to move forward, fearing I wasn’t using the best approach.
“What will others think of my code?” Code reviews made me anxious, as I worried about being judged.
The result? I spent too much time second-guessing myself instead of actually coding and learning.
What Helped Me Gain Confidence
1. Writing First, Optimizing Later
I learned that getting a working solution first is more important than making it perfect from the start. Now, I follow this approach:
Write a basic version of the solution.
Test it and make sure it works.
Refactor and improve the code.
This shift helped me stop getting stuck in my own head and start making progress.
2. Accepting That Code is Iterative
I used to think great developers wrote perfect code on their first attempt. That’s a myth. Even the best engineers write, refactor, and improve over time. Once I embraced this, I stopped stressing over every line.
3. Learning to Take Feedback Positively
At first, I saw code reviews as a judgment of my abilities. But I realized that feedback is normal, even for senior developers. Instead of fearing it, I started seeing it as a way to grow.
4. Setting a Time Limit on Decisions
To stop myself from overanalyzing, I started setting small deadlines. For example:
“I’ll spend 30 minutes researching this approach, then I’ll implement the best option I find.”
This forced me to take action instead of endlessly overthinking.
5. Practicing More, Thinking Less
I found that the more I coded, the less I overthought. The best way to gain confidence was simply to build more projects, make mistakes, and learn from them.
Final Thoughts
Breaking free from overthinking didn’t happen overnight, but by focusing on progress over perfection, I became a more confident developer. If you struggle with the same thing, remember: Write first, optimize later. Code is meant to be improved over time. Feedback is your friend. Set time limits to avoid analysis paralysis. The more you code, the more confident you’ll become.
Have you ever struggled with overthinking in coding? Let’s talk in the comments!
Day 28: Unlocking the Digital World: A Closer Look at APIs
In today’s interconnected digital landscape, applications rarely operate in isolation. They communicate, exchange data, and enable seamless interactions—often without users even realizing it. At the heart of this connectivity lies a powerful yet often overlooked component: the API (Application Programming Interface).
APIs serve as digital bridges, allowing different software systems to interact. Whether it’s a mobile app fetching weather updates, an online store processing payments, or a social media platform sharing content, APIs make it all possible. These interfaces define the rules and protocols for communication, ensuring that systems can request and exchange data efficiently and reliably.
There are different types of APIs, each serving specific purposes. RESTful APIs, which rely on HTTP requests, are widely used for web applications, providing lightweight and scalable solutions. SOAP (Simple Object Access Protocol) APIs offer a more rigid, XML-based framework, often employed in enterprise environments requiring strict security. GraphQL, a relatively newer approach, enables clients to request only the data they need, optimizing performance and reducing unnecessary data transfer.
Beyond just connecting systems, APIs are catalysts for innovation. Businesses leverage APIs to integrate third-party services, enhance functionality, and create new digital experiences. Open APIs allow developers worldwide to build on existing platforms, fostering collaboration and technological growth. Companies like Google, Amazon, and Stripe have built entire ecosystems around APIs, empowering developers to create cutting-edge applications without reinventing the wheel.
However, API security remains a critical challenge. As these interfaces handle sensitive data, improper implementation can expose vulnerabilities. Encryption, authentication mechanisms, and rate limiting are essential safeguards against cyber threats. The rise of API security tools and best practices is helping organizations mitigate risks and ensure safe data exchanges.
From cloud computing to IoT devices and artificial intelligence integrations, APIs underpin modern technology. As businesses and developers continue to harness their potential, APIs will remain fundamental in shaping the digital future. As we move toward an increasingly interconnected world, APIs will be at the forefront, enabling smarter, faster, and more efficient digital interactions.