Hello @Aasawari sure let me provide that info:
my updated query is the following one:
pipeline = [
{
"$search": {
"index": "content_comparer",
"compound": {
"filter": [
{"equals": {"path": "room_id", "value": room}},
{"equals": {"path": "user_id", "value": user}},
{"range": {"path": "created_at", "gte": time_interval}},
],
"must": [{"phrase": {"query": message, "path": "message"}}],
},
"scoreDetails": True,
}
},
{"$limit": 5},
{
"$project": {
"message": 1,
"released": 1,
"score": {"$meta": "searchScore"},
"scoreDetails": {"$meta": "searchScoreDetails"},
}
},
]
text_matches = self.message_collection.aggregate(pipeline)
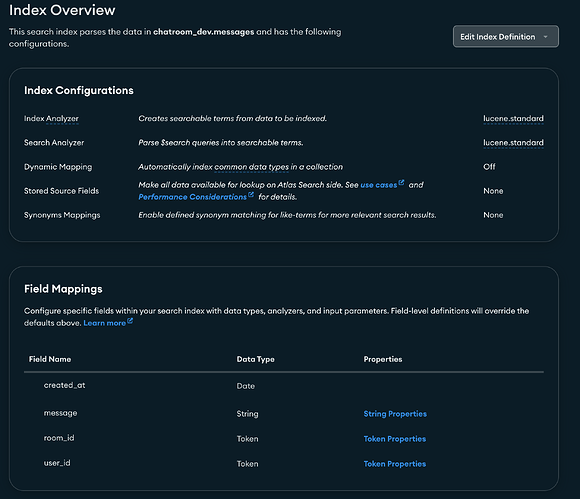
My index:
And some text examples:
If I first type “hello my friends” and then type the following sentences I get the following matches/scores:
hello → {'_id': ObjectId('6613b91bc002c76ff1cbfc2e'), 'message': 'hello my friends', 'score': 1.8647773265838623, 'scoreDetails': {'value': 1.8647773265838623, 'description': 'sum of:', 'details': [{'value': 0.0, 'description': 'match on required clause, product of:', 'details': [{'value': 0.0, 'description': '# clause', 'details': []}, {'value': 1.0, 'description': 'ConstantScore($type:token/room_id:chatroom_darwin)', 'details': []}]}, {'value': 0.0, 'description': 'match on required clause, product of:', 'details': [{'value': 0.0, 'description': '# clause', 'details': []}, {'value': 1.0, 'description': 'ConstantScore($type:token/user_id:12345)', 'details': []}]}, {'value': 0.0, 'description': 'match on required clause, product of:', 'details': [{'value': 0.0, 'description': '# clause', 'details': []}, {'value': 1.0, 'description': 'ScoreDetailsWrapped ($type:date/created_at:[1712568535187 TO 9223372036854775807]) ScoreDetailsWrapped ($type:dateMultiple/created_at:[1712568535187 TO 9223372036854775807])', 'details': []}]}, {'value': 1.8647773265838623, 'description': '$type:string/message:hello [BM25Similarity], result of:', 'details': [{'value': 1.8647773265838623, 'description': 'score(freq=1.0), computed as boost * idf * tf from:', 'details': [{'value': 4.6314873695373535, 'description': 'idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:', 'details': [{'value': 1.0, 'description': 'n, number of documents containing term', 'details': []}, {'value': 153.0, 'description': 'N, total number of documents with field', 'details': []}]}, {'value': 0.4026303291320801, 'description': 'tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:', 'details': [{'value': 1.0, 'description': 'freq, occurrences of term within document', 'details': []}, {'value': 1.2000000476837158, 'description': 'k1, term saturation parameter', 'details': []}, {'value': 0.75, 'description': 'b, length normalization parameter', 'details': []}, {'value': 3.0, 'description': 'dl, length of field', 'details': []}, {'value': 2.28104567527771, 'description': 'avgdl, average length of field', 'details': []}]}]}]}]}}
“my friends” → {'_id': ObjectId('6613b91bc002c76ff1cbfc2e'), 'message': 'hello my friends', 'score': 3.387709617614746, 'scoreDetails': {'value': 3.387709617614746, 'description': 'sum of:', 'details': [{'value': 0.0, 'description': 'match on required clause, product of:', 'details': [{'value': 0.0, 'description': '# clause', 'details': []}, {'value': 1.0, 'description': 'ConstantScore($type:token/room_id:chatroom_darwin)', 'details': []}]}, {'value': 0.0, 'description': 'match on required clause, product of:', 'details': [{'value': 0.0, 'description': '# clause', 'details': []}, {'value': 1.0, 'description': 'ConstantScore($type:token/user_id:12345)', 'details': []}]}, {'value': 0.0, 'description': 'match on required clause, product of:', 'details': [{'value': 0.0, 'description': '# clause', 'details': []}, {'value': 1.0, 'description': 'ScoreDetailsWrapped ($type:date/created_at:[1712568589841 TO 9223372036854775807]) ScoreDetailsWrapped ($type:dateMultiple/created_at:[1712568589841 TO 9223372036854775807])', 'details': []}]}, {'value': 3.387709617614746, 'description': '$type:string/message:"my friends" [BM25Similarity], result of:', 'details': [{'value': 3.387709617614746, 'description': 'score(freq=1.0), computed as boost * idf * tf from:', 'details': [{'value': 8.428622245788574, 'description': 'idf, sum of:', 'details': [{'value': 3.7906620502471924, 'description': 'idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:', 'details': [{'value': 3.0, 'description': 'n, number of documents containing term', 'details': []}, {'value': 154.0, 'description': 'N, total number of documents with field', 'details': []}]}, {'value': 4.637959957122803, 'description': 'idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:', 'details': [{'value': 1.0, 'description': 'n, number of documents containing term', 'details': []}, {'value': 154.0, 'description': 'N, total number of documents with field', 'details': []}]}]}, {'value': 0.40192925930023193, 'description': 'tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:', 'details': [{'value': 1.0, 'description': 'phraseFreq=1.0', 'details': []}, {'value': 1.2000000476837158, 'description': 'k1, term saturation parameter', 'details': []}, {'value': 0.75, 'description': 'b, length normalization parameter', 'details': []}, {'value': 3.0, 'description': 'dl, length of field', 'details': []}, {'value': 2.2727272510528564, 'description': 'avgdl, average length of field', 'details': []}]}]}]}]}}
“hello my friend” → no match given and I expected one
“hella my friend” → no match given and I expected one
Basically my objective was to just detect slighty variations in the text to check for spam messages in my product chatroom. I know that might be difficult to detect and I also made some experiments with text instead of phrase but the results were too much strict.
What do you think would help me improve this query? Oh and if I only have a partial match in the
query like “hello” compared with “hello my friends” I would need to ignore it because this would cause a lot of fake spam messages.