Hi
From time to time, like once per day typically, one of my M10 cluster complains: "
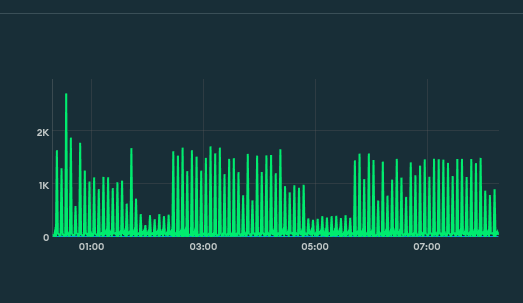
Query Targeting: Scanned Objects / Returned has gone above 1000".
This alert does not tell any specific query or anything. It just gives a link to query profiler and there is nothing interesting there. Also, this alert before I notice it is always closed 10 minutes later.
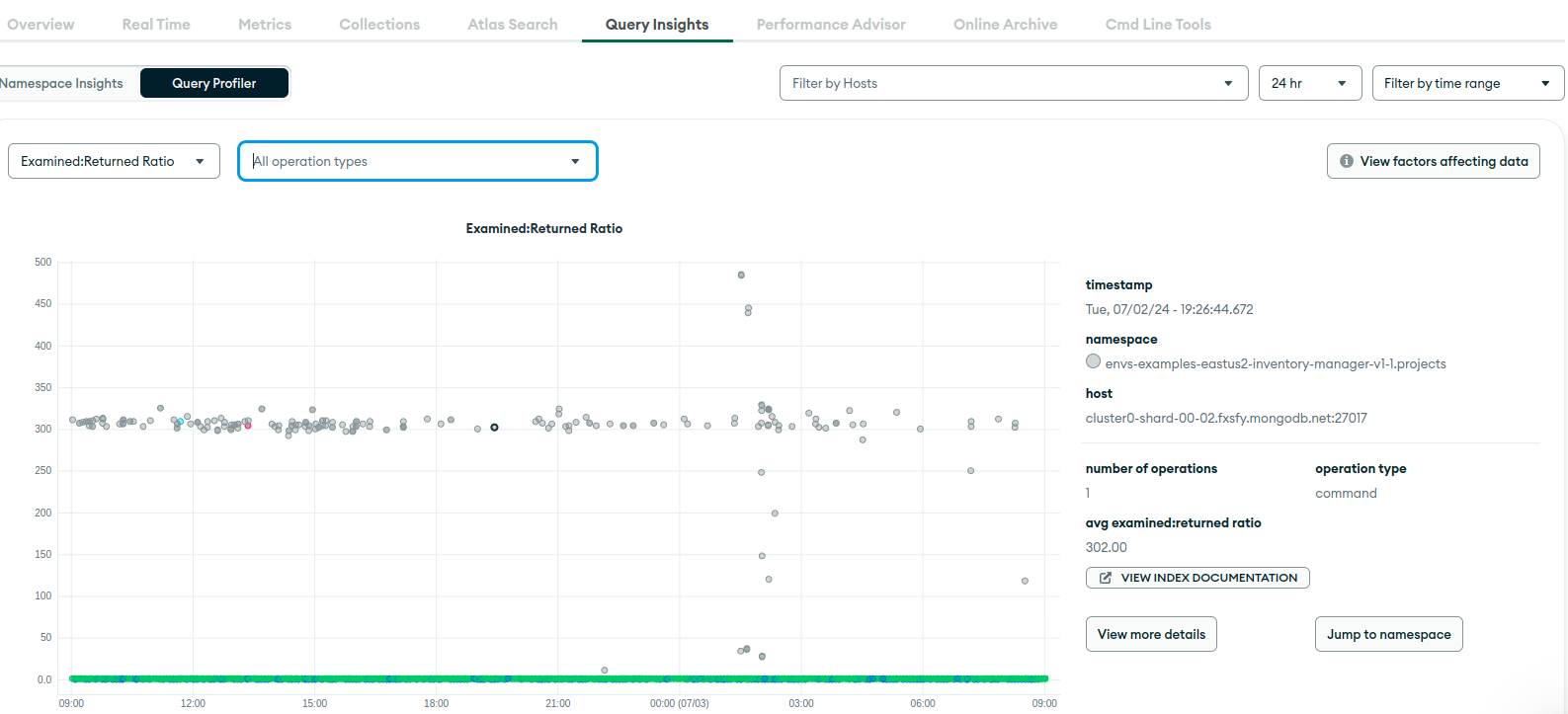
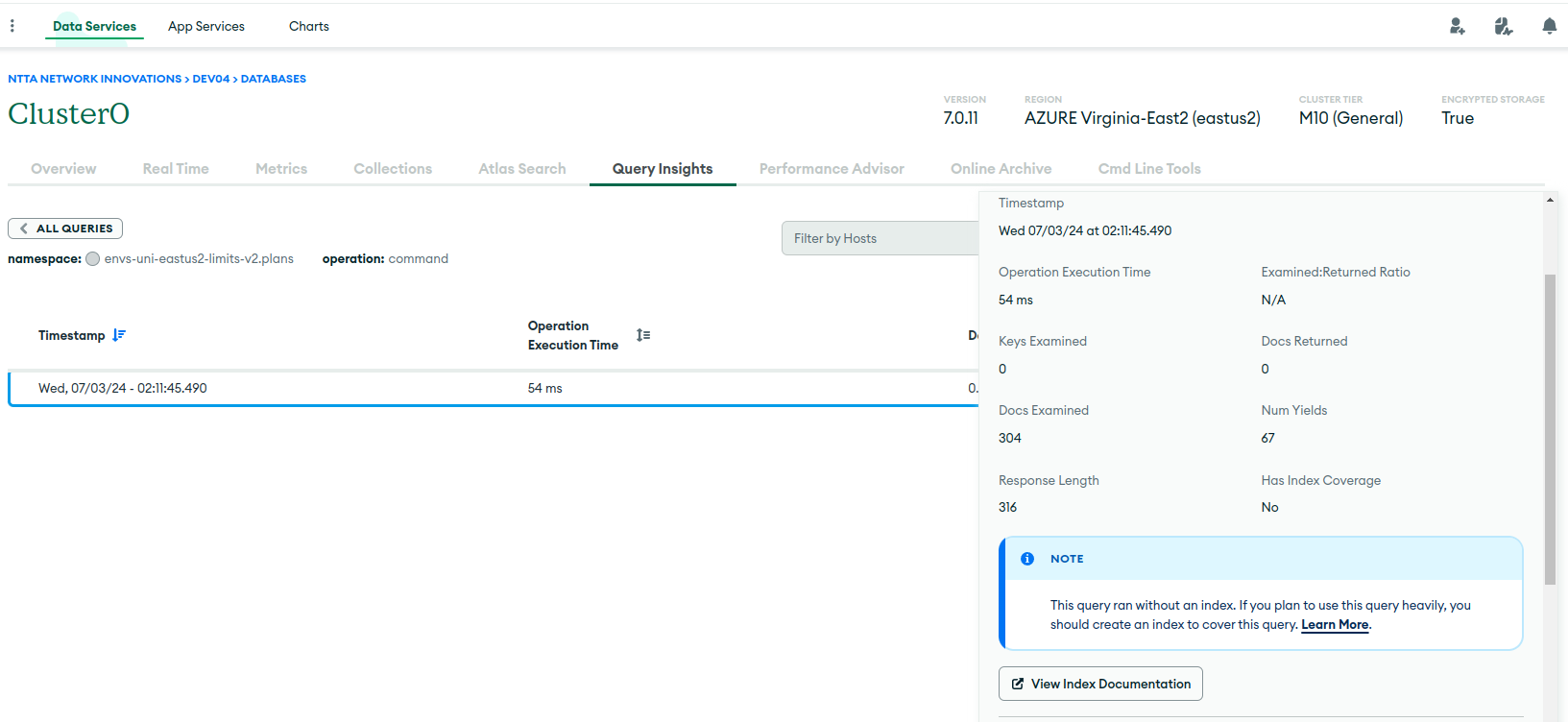
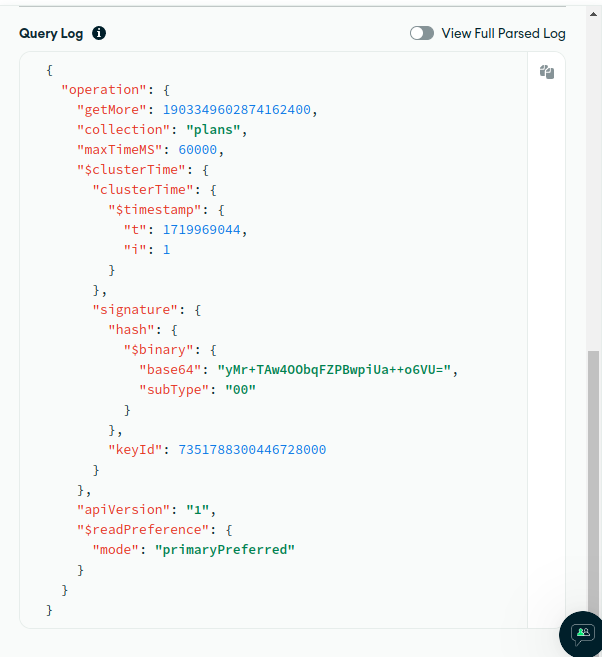
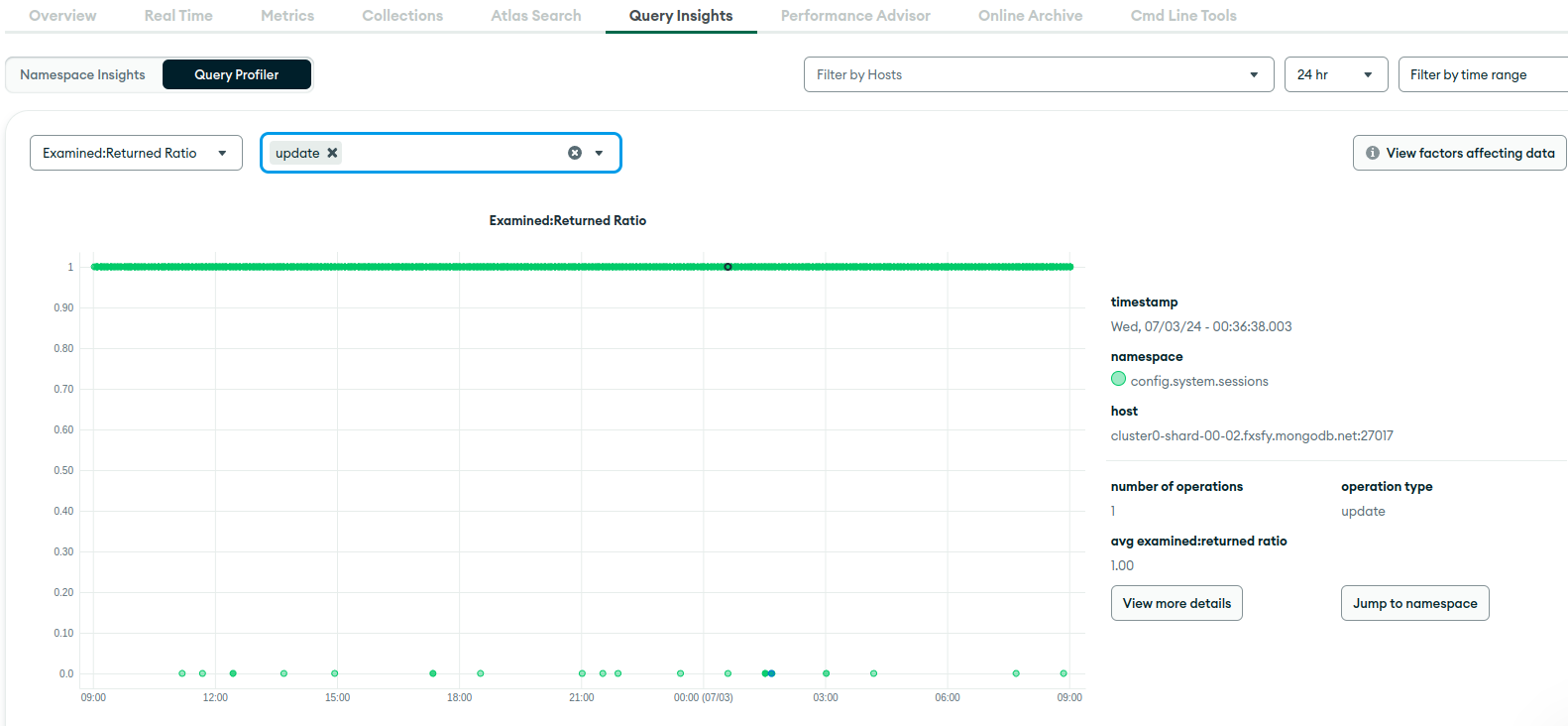
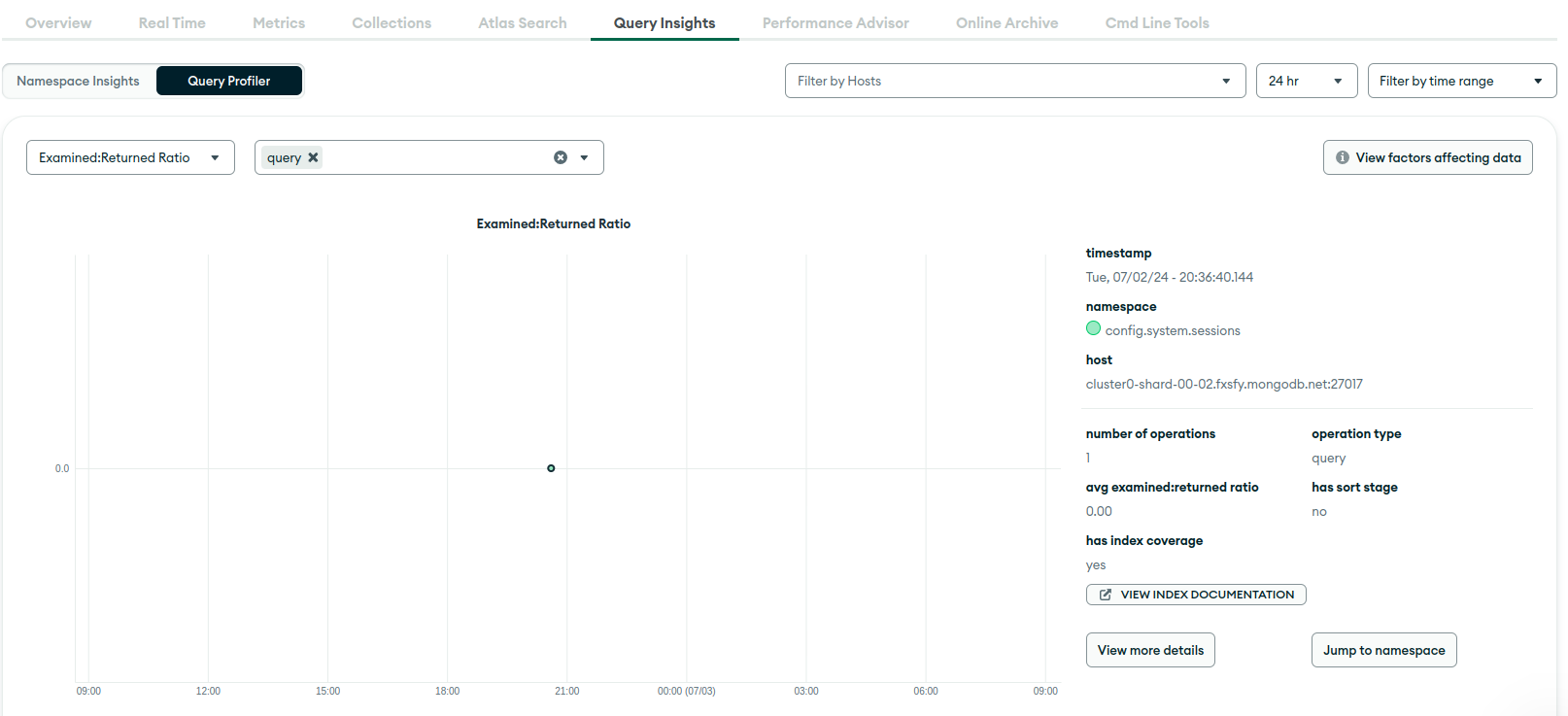
This M10 cluster is development and its really calm. It has only set of active watcher instances, that execute getMore (via Watch interface) on each collection. In Query Profiler, I see that all the queries are getMore, getMore, and just more of getMore, because TryNext is always called in the loop. I saw it uses getMore under the hood. From interesting things, is that, when I examine any getMore via profiler, I see documents scanned are almost always around 300, and amount returned is 0 (which is expected from dev env, which barely gets any updates). This is even when getMore is executed on collection with 20 documents in total. Is it because it somewhat divides by 0 and sees over 1000? And why is this query profiler suggesting some indices if oplog cannot have any?
Or maybe this Golang driver somehow does not update cluster time for each TryNext and it gets somewhat behind?
Apart from getMore, I have just plenty of config sessions updates (I guess some internal, so it cant be the issue?)
Performance advisor does not have any recommendations apart from dropping unused indexes.
Am I missing something? Thanks