

I’ve been looking for some best practices for using connection pools. Specifically, I have a MongoDB database per customer.
Each tier of MongoDB (m10, m40, etc.) allows a limited number of connections. All the information I’m seeing for connection pooling talks about right-sizing the connection pool for a single database. In our case, we have hundreds of databases and a horizontally scaled nodejs application.
You can think of the architecture like this:
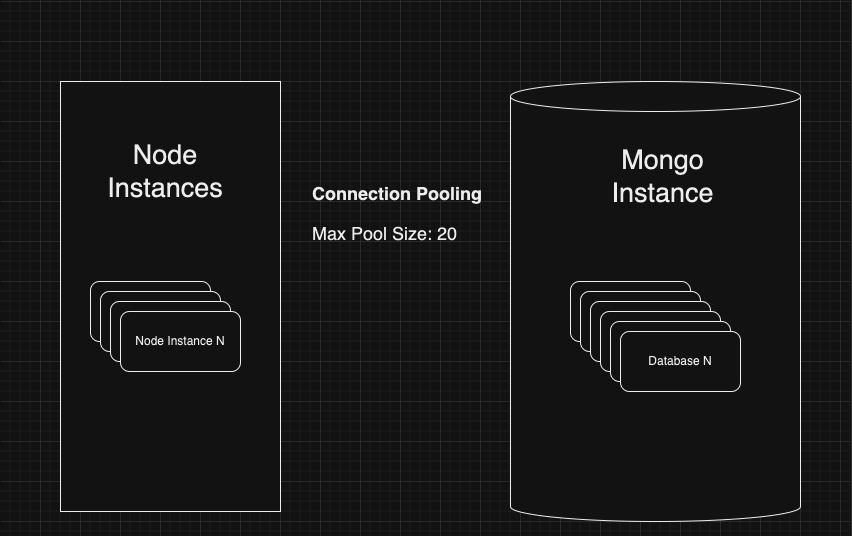
The users are load-balanced across the node instances. Each user should only be able to access data from their database. To accomplish this, we create a connection per database. Let’s do the math:
- min and max pool size is 20
- The number of node instances is 1
- The number of single-tenant databases is 1.
In this scenario, the numbers are straight forward. The maximum number of connections created by the connection pool should be 20. If you look at the MongoDB metrics you’ll see 20 connections + whatever connections MongoDB uses for monitoring.
Here is where it starts to get problematic.
- min and max pool size is 20
- The number of node instances is 1
- The number of single-tenant databases is 5.
Since we create a connection pool for each single-tenant database, we’ll create 100 connections to MongoDB. 20 connections per single-tenant database, and we have 5 databases.
That would still be fairly straightforward to account for. If we disregard the activity needs of each client and assume a consistent usage, we could take the total allowed connections (6000 on M40 tier) divide that by number of clients and adjust as needed.
Then blamo, bigger issues.
- min and max pool size is 20
- Number of node instances is 5 ← problem
- The number of single-tenant databases is 5.
We need more node instances to account for the traffic of each client. By increasing node instances from 1 to 5 we’ve taken our connection count from: 100 connections (20 connections X 5 databases X 1 node instance) to: 500 connections (20 connections X 5 databases X 5 node instances).
Then, every time we add a database, we incur the connection increase of 100 (20 connections per database).
So very quickly we run into a problem with outrageous possible connection counts, or having to restrict the connection count to something silly like “2” per database. This can cause performance issues.
If I have 20 node instances and 400 databases I might create thousands of connections in the pools. It becomes very difficult to manage connection pooling effectively.
I’ve considered smashing all of the data into a single database keyed by client id. That is quite the lift and likely to be unfeasible at this time.
Since it might come up, I’m using mongoose as the ORM. If anyone has had experience with this or can point me in the right direction that would be lovely. I’d rather not solve the problem with increased MongoDB cluster tier but that might be where we end up.