Vector embeddings are mathematical representations of text created by translating words or sentences into numbers — a language that computers can understand. They bridge the rich, nuanced world of human language (text, images, speeches, videos etc.) and the precise environment of machine learning models (numbers) by representing data points.
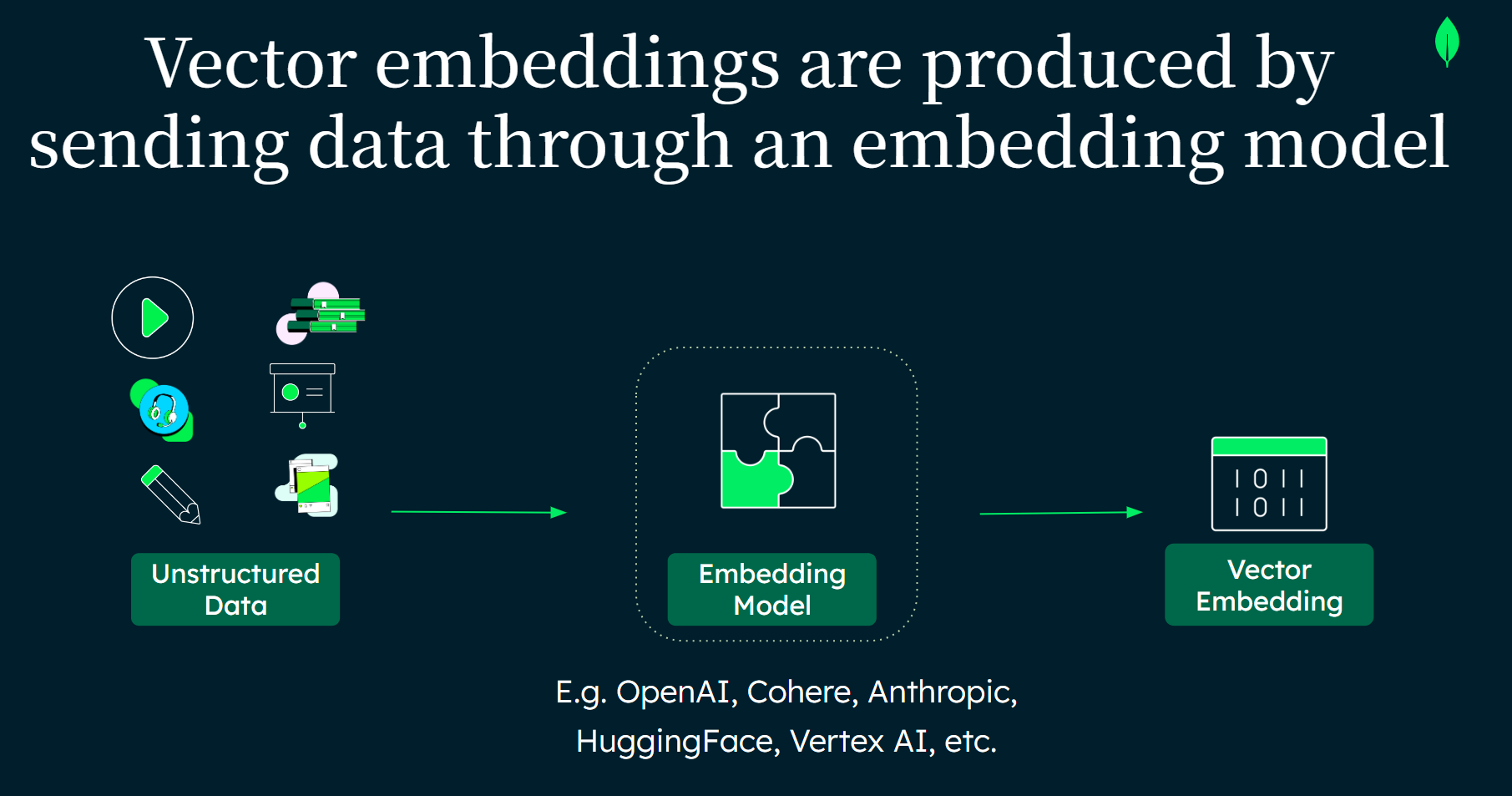
Most often used in natural language processing (NLP), vector embeddings allow machine learning algorithms to analyze information much like humans but at a scale and speed far beyond our capabilities. Although they also work with images, audio processing, bioinformatics, and recommendation systems, this article will focus on word vector embeddings in natural language processing using a machine learning model.
Table of contents
- What is natural language processing?
- Types of vector embeddings in NLP
- What is a vector?
- Vector embeddings in multidimensional spaces
- Dimensionality in vector embeddings
- Advantages of vector embeddings in real-world scenarios
- Challenges and limitations
- Using vector embeddings in other applications
- Why use MongoDB Atlas Vector Search for vector similarity search?
- Conclusion
- FAQs
What is natural language processing?
NLP is a type of artificial intelligence that uses vector embeddings in conjunction with machine learning algorithms to evaluate, understand, and interpret human language. This combination achieves comprehension and interaction that mirrors human ability but at a scale and speed far beyond our capabilities. NLP excels in tasks such as interpreting text from social media, translating languages, and powering conversational agents.
Types of vector embeddings in NLP
Below are a few examples of the diverse vector embedding techniques instrumental in advancing NLP, each bringing its strengths to various language understanding challenges.
Word2Vec: Developed by Google, Word2Vec captures the context of words within documents. It’s beneficial for tasks that require understanding word associations and meanings based on their usage in sentences.
GloVe (global vectors for word representation): GloVe is unique in its approach as it analyzes word co-occurrences over the whole corpus for training, enabling it to capture global statistics of words. It’s particularly useful for tasks that involve semantic similarity between words.
BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, BERT represents a breakthrough in contextually aware embeddings. It looks at the context from both sides of a word in a sentence, making it highly effective for sophisticated tasks like sentiment analysis and question answering.
What is a vector?
To truly appreciate what vector embeddings are and how they work, it's essential first to understand what a vector is in this setting. Think of a vector as a point in space with direction and magnitude. It's like a dot on a map with specific coordinates. These data points aren't just random numbers; they represent different characteristics or features of the data types that the vector represents.
Vector embeddings in multidimensional spaces
Now that the basics of vectors and data points have been introduced, it's important to note that in the context of vector representations for text, more than one vector embedding or one dimension is used. When text — words, phrases, or entire documents — are converted into vectors, each piece of text plots as a point in a vast, multidimensional space. This space isn't like a typical three-dimensional space we're familiar with; it has many more dimensions, each representing a different aspect of the text's meaning or usage.
Imagine a map where words with similar meanings or usages are mapped closer together, making it easier to see their relationships or similar data points.
Turning text into vector embeddings is a game-changer for machine learning algorithms. These algorithms are great at dealing with numbers — they can spot patterns, make comparisons, and draw conclusions from numerical data.
Dimensionality in vector embeddings
Let's dig a little deeper into the concept of dimensionality, which we introduced above. Think of dimensionality in vector embeddings like the resolution of a photo. High-resolution photos are more detailed and precise, but they take up more space on your phone and require more processing power. Similarly, in vector embeddings, more dimensions mean that the representation of words or phrases can capture more details and nuances of language.
High-dimensional embeddings
High-dimensional embeddings are like high-resolution photos. They have hundreds or even thousands of dimensions, allowing them to capture much information about a word or phrase. Each dimension can represent a different aspect of a word's meaning or use. This detailed representation is excellent for complex tasks in natural language processing, where understanding subtle differences in language is crucial.
However, like high-resolution photos, these embeddings require more computer memory and processing power. Also, there's a risk of "overfitting" — think of it like a camera that focuses on capturing every tiny detail and fails to recognize common, everyday objects. In machine learning, the model might get too tailored to its training data and perform poorly on new, unseen data.
Low-dimensional embeddings
On the other hand, low-dimensional embeddings are like lower-resolution photos. They have fewer dimensions, so they use less computer memory and process more quickly, which is excellent for applications that need to run fast or have limited resources. But just like lower-resolution photos can miss finer details, these embeddings might not capture all the subtle nuances of language. Depending on the task, they provide a more general picture, which can sometimes be enough.
Choosing the proper dimensionality for creating vector embeddings is a balance. It's about weighing the need for detail against the need for efficiency and the ability of the model to perform well on new, unseen data. Finding the right balance often involves trial and error and depends on the specific task and the data. It's a crucial part of developing effective NLP solutions, requiring a thoughtful approach to meet both the linguistic needs of the task and the practical limitations of technology.
Advantages of vector embeddings in real-world scenarios
Vector embeddings have opened up a world of possibilities in how machines interact with human language. They make technology more intuitive and natural, enriching interactions across digital platforms and tools. Below are a few applications highlighting how vector embeddings are used today.
Sentiment analysis
Sentiment analysis is like a digital mood ring. Businesses use it to understand how people feel about their products or services by analyzing the tone of customer reviews and social media posts. Vector embeddings help computers catch subtle emotional cues in text, distinguishing genuine praise from sarcasm, even when the words are similar.
Machine translation
Vector embeddings are the backbone of translation apps. They help computers grasp the complexities and nuances of different languages. When a sentence is translated from one language to another, it's not just about swapping words; it's about conveying the same meaning, tone, and context. Vector embeddings are crucial in achieving this.
Chatbots and virtual assistants
Are you curious how virtual assistants like Siri or Alexa understand and respond to your queries so well? This functionality is primarily due to vector embeddings. They enable artificial intelligence (AI) systems to process what you're saying, figure out what you mean, and respond in a way that makes sense.
Information retrieval
This category covers everything from search engines to recommendation systems. Vector embeddings help these systems understand what is being searched, not just by matching keywords but by grasping the context of the query. This way, the information or recommendations will more likely be relevant.
Text classification
Text classification can filter emails, categorize news articles, and even tag social media posts. Vector embeddings assist in sorting text into different categories by understanding the underlying themes and topics, making it easier for algorithms to decide, for example, if an email is spam.
Speech recognition
Regarding converting spoken words into written text, vector embeddings play a crucial role. They help capture the spoken words accurately, considering how the same word can be pronounced or used in different contexts, leading to more accurate transcriptions.
Challenges and limitations
While vector embeddings are a powerful tool in NLP, they are not without their challenges. Addressing these issues is crucial for ensuring that these technologies are effective, fair, and up-to-date, requiring continuous effort and innovation in the field. Let's explore these challenges and limitations, especially in how vector embeddings interact with and process human language.
Handling out-of-vocabulary words
One of the trickiest issues with vector embeddings is dealing with words that the system has never seen before, often called "out-of-vocabulary" words. It's like encountering a word in a foreign language you've never learned. For a computer, these new words can be a fundamental stumbling block. The system might struggle to understand and place them correctly in the context of what it already knows.
Bias in embeddings
Like humans, computers can be biased, especially when they learn from data reflecting human prejudices. When vector embeddings train on text data from the internet or other human-generated sources, they can inadvertently pick up and even amplify these biases. This possibility is significant because it can lead to unfair or stereotypical representations in various applications, like search engines or AI assistants.
Complexity of maintaining and updating models
Keeping vector embedding models up-to-date and relevant is no small task. Language is constantly evolving — new words pop up, old words fade away, and meanings change. Ensuring these models stay current is like updating a constantly evolving dictionary. It requires ongoing work and resources, making it a complex and challenging aspect of working with vector embeddings.
Contextual ambiguity
While vector embeddings are good at capturing meaning, they sometimes struggle with words with multiple meanings based on context. For instance, the word "bat" can refer to an animal or sports equipment, and without sufficient context, the model might not accurately capture the intended use.
Resource intensity
Training sophisticated vector embedding models requires significant computational resources, which can be a barrier, especially for smaller organizations or individual researchers who might not have access to the necessary computing power.
Data quality and availability
The effectiveness of vector embeddings heavily depends on the quality and quantity of the training data. The embeddings might not be as accurate or helpful in languages or domains where data is scarce or of poor quality.
Transferability across languages
Vector embeddings trained in one language may not transfer well to another, especially for structurally different languages. These structural differences challenge multilingual applications or languages with limited resources.
Model interpretability
Understanding why a vector embedding model behaves a certain way or makes specific decisions can be challenging. This lack of interpretability can be a significant issue, especially in applications where understanding the model's reasoning is crucial.
Scalability
As the amount of data and the complexity of tasks increase, scaling vector embedding models while maintaining performance and efficiency can be challenging.
Dependency on training data
Vector embeddings can only be as good as their training data. If the training data is limited or biased, the embeddings will inherently reflect those limitations or biases.
Using vector embeddings in other applications
While vector embeddings are most prominently used in NLP, they are also used in other ways. Here are a few other areas where vector embeddings are employed.
Computer vision
In image processing and computer vision, embeddings represent images or parts of images. Similar to how they capture the essence of words in NLP, embeddings in computer vision capture essential features of images, enabling tasks like image recognition, classification, and similarity detection.
Recommendation systems
Vector embeddings also show up in recommendation systems, such as those on e-commerce or streaming platforms. They help understand user preferences and item characteristics by representing users and items in a vector space, enabling the system to make personalized recommendations based on similarity.
Bioinformatics
In bioinformatics, embeddings can represent biological data, such as gene sequences or protein structures. These embeddings help in various predictive tasks, like understanding gene function or protein-protein interactions.
Graph analysis
In network and graph analysis, embeddings represent nodes and edges of a graph, which is helpful in social network analysis, link prediction, and understanding the structure and dynamics of complex systems.
Time series analysis
Vector embeddings work in analyzing time series data, such as financial market trends or sensor data, by capturing temporal patterns and dependencies in a vector space.
These diverse applications show that the concept of embeddings is a versatile tool in the broader field of machine learning and data science, not limited to just text and language processing.
Why use MongoDB Atlas Vector Search for vector similarity search?
Overview
MongoDB Atlas Vector Search is an advanced tool designed to handle complex vector similarity searches. It leverages the strengths of MongoDB's flexible data model and robust indexing capabilities, making it a powerful solution for various search and generative AI applications requiring vector search.
Key benefits
Seamless integration with MongoDB: Atlas Vector Search is built into MongoDB, allowing you to use the same database for both structured and unstructured data. This integration simplifies your architecture and data management processes.
Scalability: MongoDB Atlas provides a highly scalable environment that can handle large volumes of data, making it ideal for applications requiring extensive vector searches.
Flexible indexing: MongoDB's indexing capabilities enable efficient storage and retrieval of vector data, ensuring fast and accurate search results.
Multi-cloud availability: Atlas Vector Search is available across major cloud providers, ensuring flexibility and reliability.
Security: Benefit from MongoDB's advanced security features, including encryption at rest and in transit, role-based access control, and comprehensive auditing.
Similarity algorithms supported
Cosine similarity: This measures the cosine of the angle between two vectors. It is particularly useful for comparing documents in text analysis, as it considers the orientation rather than the magnitude of the vectors.
Euclidean distance: This calculates the straight-line distance between two points in a multidimensional space. It is a simple and intuitive measure of similarity, often used in clustering and classification tasks.
Dot product: This computes the sum of the products of the corresponding entries of two sequences of numbers. It is used in various applications, including machine learning and recommendation systems, to measure the similarity between two vectors.
Conclusion
Vector embeddings represent a significant leap in how machines process and understand human language and other complex data types. From enhancing the capabilities of NLP in understanding text to their applications in fields like computer vision and bioinformatics, vector embeddings have proven to be invaluable tools. As technology evolves, so will the sophistication and utility of vector embeddings.
By storing vector embeddings in documents alongside metadata and contextual app data in a single, unified, fully managed, secure platform, developers can enjoy a seamless, flexible, and simplified experience. MongoDB’s robust integrations with all major AI services and cloud providers allow developers to use the embedding model of their choice and then perform indexing and searching, building apps efficiently and securely all in one place. This streamlined approach empowers developers to avoid the complexity of dealing with multiple platforms and focus more on building effective search and generative AI applications for their organizations. See how MongoDB Vector Search works, and visit the Atlas Vector Search Quick Start guide to create your first index in minutes.
FAQs
What is semantic search?
Semantic search refers to a search technique that goes beyond keyword matching to understand the intent and contextual meaning of the search query. Instead of just looking for exact word matches, semantic search considers factors like the context of words in the query, the relationship between words, synonyms, and the overall meaning behind the query. This approach allows for more accurate and relevant search results, as it aligns more closely with how humans understand and use language.
Does a reverse image search involve vector embeddings?
Yes, in a reverse image search, images are transformed into vector embeddings, which are used to compare and find similar images in a database, making the search process efficient and accurate.
What is anomaly detection?
Anomaly detection is a technique used in data analysis and various applications to identify patterns that do not conform to expected behavior. These nonconforming patterns are often referred to as anomalies, outliers, or exceptions.