- $cmd
- A virtual collection that exposes MongoDB's database commands. To use database commands, see Issue Commands.
- _id
- A field required in every MongoDB document. The
_id field must have a unique value. You can
think of the
_idfield as the document's primary key. If you create a new document without an_idfield, MongoDB automatically creates the field and assigns a unique BSON ObjectId to the field. - absolute system CPU utilization
System CPU utilization relative to the full amount of CPU available to cloud instances that share CPU.
When a cloud provider throttles CPU utilization for a cloud instance, the instance's absolute system CPU utilization is equal to the baseline CPU utilization assigned to this instance.
When a cloud provider adds CPU above the baseline CPU, such as through a bursting mechanism, the sum of normalized kernel CPU utilization and user CPU utilization on an instance can exceed the instance's baseline CPU. In this case, the sum of the normalized kernel CPU utilization and user CPU utilization is still less than the full amount of CPU shared by cloud instances. See also relative system CPU utilization, baseline CPU utilization, and burstable instances.
- accumulator
- An expression in an aggregation pipeline that
maintains state between documents in the aggregation
pipeline. For a list of accumulator operations, see
$group. - action
- An operation the user can perform on a resource. Actions and resources combine to create privileges. See action.
- admin database
- A privileged database. Users
must have access to the
admindatabase to run certain administrative commands. For a list of administrative commands, see Administration Commands. - Advanced Persistent Threat
- In security, an attacker who gains and maintains long-term access to the network, disk and/or memory and remains undetected for an extended period.
- aggregation
- An operation that reduces and summarizes large sets of data. For more information, see Aggregation Operations.
- aggregation pipeline
- Consists of one or more stages that process documents. Aggregation pipelines offer rich syntax to express complex queries. For a list of stages, see Aggregation Stages.
- alert
Notification sent by Atlas when your database operations or server usage reach thresholds that affect cluster performance. To learn what conditions you can set to trigger alerts, see Review Alert Conditions.
- analytics node
- Specialized read-only node that can isolate queries which you do not want to affect your operational workload. Analytics nodes are useful for handling analytic data such as reporting queries executed by BI tools. You can host analytics nodes in dedicated geographic regions to optimize read performance and reduce latency.
- API
Communication protocol facilitating interaction between the client and MongoDB Atlas. You can use the Atlas Administration API to automate many of the tasks performed in the Atlas UI.
- Approximate Nearest Neighbor (ANN) search
Computational technique used to quickly find points in a dataset that are close to a given query point. MongoDB Vector Search uses ANN search to find vector embeddings in the data that are closest to the vector embeddings in the query without scanning every vector.
- arbiter
- A replica set member that exists just to vote in elections. Arbiters do not replicate data. An arbiter participates in elections for a primary but cannot become a primary. For more details, see Replica Set Arbiter.
- Atlas
- MongoDB Atlas is a cloud-hosted database-as-a-service.
- Atlas user
Account used to access the MongoDB Atlas application. You can grant MongoDB Atlas users access to MongoDB Atlas organizations, projects, or both, with certain permissions defined by user roles. A MongoDB Atlas user is different than a database user. MongoDB Atlas users do not provide access to any MongoDB databases.
- Atlas user role
Set of permissions granted to an Atlas user. You can grant permissions at the organization or project level.
- atomic operation
- An atomic operation is a write operation that either completes entirely or doesn't complete at all. For distributed transactions, which involve writes to multiple documents, all writes to each document must succeed for the transaction to succeed. Atomic operations cannot partially complete. See Atomicity and Transactions.
- authentication
- Verification of the user identity. See Authentication on Self-Managed Deployments.
- authorization
- Provisioning of access to databases and operations. See Role-Based Access Control in Self-Managed Deployments.
- auto-scaling
Configurable option to have your cluster automatically increase or decrease its cluster tier, storage capacity, or both in response to cluster usage.
- automatic encryption
- When using In-Use Encryption, automatically performing encryption and decryption based on your preconfigured encryption schema. The Automatic Encryption Shared Library translates MongoDB Query Language into the correct call, meaning you don't need to rewrite your application for specific encrypt and decrypt calls.
- B-tree
- A data structure commonly used by database management systems to store indexes. MongoDB uses B-tree indexes.
- backup
Copy of your data that encapsulates the state of your cluster at a given time. Backups provide a safety measure in the case of data loss events.
MongoDB Atlas provides fully-managed Cloud Backups.
- backup cursor
- A tailable cursor that points to a list of backup files. Backup cursors are for internal use only.
- balancer
- An internal MongoDB process that runs in the context of a sharded cluster and manages the migration of chunks. Administrators must disable the balancer for all maintenance operations on a sharded cluster. See Sharded Cluster Balancer.
- baseline CPU utilization
- Fraction of the full amount of CPU available to cloud instances that share CPU. A cloud provider assigns a certain amount of baseline CPU to each cloud instance, based on the instance's cluster tier. Typically, baseline CPU utilization falls between 20% and 50% of absolute system CPU utilization. See also relative system CPU utilization and burstable instances.
- big-endian
A byte order in which the most significant byte (big end) of a multibyte data value is stored at the lowest memory address.
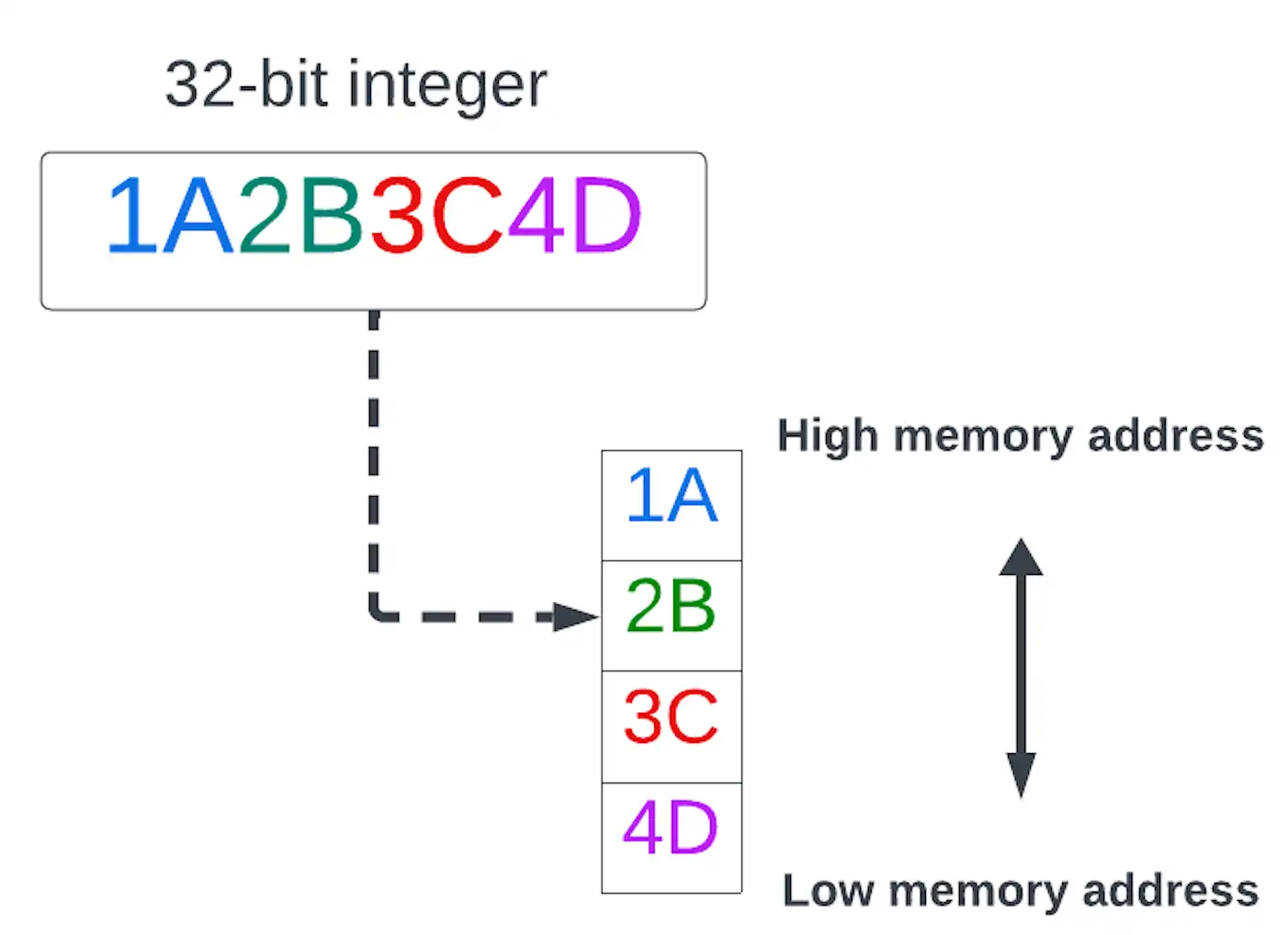 click to enlarge
click to enlarge- blocking sort
- A sort that must be performed in memory before the output is returned. In-memory sorts may impact performance for large data sets. Use an indexed sort to avoid an in-memory sort.
- bounded collection scan
- A plan used by the query optimizer that excludes documents with specific field value ranges. For example, if a range of date field values is outside of a specified date range, the documents in that range are excluded from the query plan. See Collection Scan.
- BSON
- A serialization format used to store documents and make remote procedure calls in MongoDB. "BSON" is a combination of the words "binary" and "JSON". Think of BSON as a binary representation of JSON (JavaScript Object Notation) documents. See BSON Types and MongoDB Extended JSON (v2).
- BSON types
- The set of types supported by the BSON serialization format. For a list of BSON types, see BSON Types.
- burstable instances
- Cloud instance types that share a common physical CPU that, for some cloud providers, use a "CPU credit" model. When you use burstable instances, portions of shared CPU may either become available to each of the virtual instances or may become unavailable, under different demands on the instance resources. To learn more, see AWS burstable instances, Azure disk bursting, and GCP CPU Bursting. See also baseline CPU utilization, absolute system CPU utilization, and relative system CPU utilization.
- CAP theorem
- Given three properties of computing systems, consistency, availability, and partition tolerance, a distributed computing system can provide any two of these features, but never all three.
- capped collection
- A fixed-sized collection that automatically overwrites its oldest entries when the collection reaches its maximum size. The MongoDB oplog that is used in replication is a capped collection. See Capped Collections.
- cardinality
- The measure of the number of elements within a set of values.
For example, the set
A = { 2, 4, 6 }contains 3 elements, and has a cardinality of 3. See Shard Key Cardinality. - cartesian product
- The result of combining two data sets where the combined set contains every possible combination of values.
- cfq
- Complete Fairness Queueing (cfq) is an I/O operation scheduler that allocates bandwidth for incoming request processes.
- checksum
- A calculated value used to ensure data integrity. The md5 algorithm is sometimes used as a checksum.
- chunk
- A contiguous range of shard key values within a shard. Chunk ranges are inclusive of the lower boundary and exclusive of the upper boundary. MongoDB splits chunks when data needs to be balanced inside the cluster. While the default chunk size is 128 megabytes, it is possible for chunks to grow larger than the default size without triggering an automatic split. Chunk splitting occurs as part of the balancing process to distribute data evenly across the cluster. For more details, see Data Partitioning with Chunks, Sharded Cluster Balancer, and Manage Sharded Cluster Balancer.
- client
The application layer that uses a database for data persistence and storage. Drivers provide the interface level between the application layer and the database server.
A client can also be a single thread or process.
- client affinity
- A consistent client connection to a specified data source.
- cloud backups
Localized cluster backup storage using the native snapshot functionality of the cluster's cloud service provider.
MongoDB Atlas supports Cloud Backups for clusters served on:
- cluster
Set of nodes comprising a MongoDB deployment. Clusters can be replica sets or sharded deployments.
- cluster class
Configurable for M40+ clusters hosted on AWS.
Storage class of your cluster. Your selected class affects cluster storage performance and cluster costs. You can choose one of the following classes:
Low CPU
General
Local NVMe SSD
- cluster tier
Dictates the memory, storage, vCPUs, and IOPS specification for each data-bearing server in the cluster. Cluster storage size and overall performance increase as the cluster tier increases.
- cluster-to-cluster sync
- Synchronizes data between sharded clusters. Also known as C2C sync.
- clustered collection
- A collection that stores documents ordered by a clustered index key. See Clustered Collections.
- CMK
- Abbreviation of Customer Master Key, see Customer Master Key.
- collection
- A grouping of MongoDB documents. A collection is the equivalent of an RDBMS table. A collection is in a single database. Collections do not enforce a schema. Documents in a collection can have different fields. Typically, documents in a collection have a similar or related purpose. See Naming Restrictions.
- collection scan
- Collection scans are a query execution strategy where MongoDB must inspect every document in a collection to see if it matches the query criteria. These queries are very inefficient and don't use indexes. See Query Optimization for details about query execution strategies.
- commit
- Saves data changes made after the start of the
startSessioncommand. Operations within a transaction are not permanent until they are committed with thecommitTransactioncommand. - commit quorum
- During an index build the commit quorum specifies how many secondaries must be ready to commit their local index build before the primary node performs the commit.
- compound index
- An index consisting of two or more keys. See Compound Indexes.
- concurrency control
- Concurrency control ensures that database operations can be executed concurrently without compromising correctness. Pessimistic concurrency control, such as that used in systems with locks, blocks any potentially conflicting operations even if they may not conflict. Optimistic concurrency control, the approach used by WiredTiger, delays checking until after a conflict may have occurred, ending and retrying one of the operations in any write conflict.
- config database
- An internal database with metadata for a sharded cluster.
Typically, you don't modify the
configdatabase. For more information about theconfigdatabase, see Config Database. - config server
- A
mongodinstance that stores all the metadata associated with a sharded cluster. See Config Servers. - config shard
- A
mongodinstance that stores all the metadata associated with a sharded cluster and can also store application data. See Config Shards. - connection pool
- A cache of database connections maintained by the driver. The cached connections are re-used when connections to the database are required, instead of opening new connections.
- connection storm
- A scenario where a driver attempts to open more connections to a deployment than that deployment can handle. When requests for new connections fail, the driver requests to establish even more connections in response to the deployment slowing down or failing to open new connections. These continuous requests can overload the deployment and lead to outages.
- container
- A collected set of software and its dependent libraries that are packaged together to make transferring between computing environments easier. Containers run as compartmentalized processes on your operating system, and can be given their own resource constraints. Common container technologies are Docker and Kubernetes.
- contention factor
- Multiple operations attempting to modify the same resource, such as a document field, cause conflicts that delay operations. The contention factor is a setting used with Queryable Encryption to internally partition encrypted field/value pairs and optimize operations. See contention.
- cosine similarity
- Metric that uses the angle between two vectors to determine the similarity between those vectors. Cosine similarity is sensitive to vector orientation. You can use cosine similarity function when indexing your vector embeddings for MongoDB Vector Search. If the vectors are normalized to unit length, use dotProduct similarity function instead.
- CPU steal
- The percentage by which the CPU usage exceeds the guaranteed baseline CPU credit accumulation rate. CPU steal is relevant for cloud providers that rely on the credit model in their bursting strategy. CPU credits are units of CPU utilization that you accumulate. The credits accumulate at a constant rate to provide a guaranteed level of performance. You can use these credits for additional CPU performance. When the credit balance is exhausted, MongoDB only provides the guaranteed baseline of CPU performance and displays the amount of excess as steal percent See also relative system CPU utilization, baseline CPU utilization, and burstable instances.
- CRUD
- An acronym for the fundamental operations of a database: Create, Read, Update, and Delete. See MongoDB CRUD Operations.
- CSV
- A text data format with comma-separated values.
CSV files can be used to exchange data between relational
databases because CSV files have tabular data. You can
import CSV files using
mongoimport. - cursor
- A pointer to the result set of a query. Clients can iterate through a cursor to retrieve results. By default, cursors not opened within a session automatically timeout after 10 minutes of inactivity. Cursors opened in a session close with the end or timeout of the session. See Cursors.
- custom role
Custom set of MongoDB privilege actions and MongoDB roles that you can save and assign to a database user. Create custom roles when MongoDB Atlas's built-in roles don't describe your desired set of privileges.
- Customer Master Key
- A key that encrypts your Data Encryption Key. The customer master key must be hosted in a remote key provider.
- daemon
- A background, non-interactive process.
- data directory
- The file system location where
mongodstores data files.dbPathspecifies the data directory. - Data Encryption Key
- A key you use to encrypt the fields in your MongoDB documents. The encrypted Data Encryption Key is stored in your Key Vault collection. The Data Encryption Key is encrypted by the Customer Master Key.
- Data Explorer
Tool within MongoDB Atlas to view and interact with cluster data. You can also use the Data Explorer to manage indexes and run aggregation pipelines to process your data.
- Data Federation
MongoDB's solution for querying data stored in low-cost S3 buckets, MongoDB Atlas clusters, and HTTP endpoints using the MongoDB Query Language. Analytics applications can use Atlas Data Federation to make use of archived data for their data processing needs.
- data files
- Store document data and indexes. The
dbPathoption specifies the file system location for the data files. - data ingestion pipeline
- Workflow for organizing and transforming data by using RAG and storing it in a vector database such as MongoDB Atlas.
- data partition
- A distributed system architecture that splits data into ranges. Sharding uses partitioning. See Data Partitioning with Chunks.
- data-center awareness
- A property that allows clients to address members in a system based on their locations. Replica sets implement data-center awareness using tagging. See Data Center Awareness.
- database
- A container for collections. Each database has a set of files in the file system. One MongoDB server typically has multiple databases.
- database command
- A MongoDB operation, other than an insert, update, remove, or query. For a list of database commands, see Database Commands. To use database commands, see Issue Commands.
- database exfiltration
- Database exfiltration refers to an authorized party taking data from a secured system and either sharing it with an unauthorized party or storing it on an unsecured system. This may be malicious or accidental.
- database profiler
- A tool that, when enabled, keeps a record on all long-running
operations in a database's
system.profilecollection. The profiler is most often used to diagnose slow queries. See Database Profiler. - database user
Credentials used to authenticate a client to access a MongoDB cluster. You can assign privileges to a database user to determine that user's access level to a cluster. Database users are different from Atlas users. Database users have access to MongoDB deployments, not the MongoDB Atlas application.
- dbpath
- The location of MongoDB's data file storage. See
dbPath. - DDL (Data Definition Language)
- DDL includes commands that create and modify collections and indexes.
- dead letter queue
- A dead letter queue is a collection within an MongoDB Atlas database that stores documents that throw errors during ingestion.
- dedicated cluster
Cluster category containing clusters of tier
M10and greater.TierRecommended environmentsM10andM20Development
Low-traffic production
M30and greaterProduction
- dedicated config server
- A
mongodinstance that only stores all the metadata associated with a sharded cluster. - DEK
- Data Encryption Key. For more details, see Data Encryption Key.
- delayed member
- A replica set member that cannot become primary and applies operations at a specified delay. The delay is useful for protecting data from human error (unintentionally deleted databases) or updates that have unforeseen effects on the production database. See Delayed Replica Set Members.
- dense vectors
- Numeric representation of data where most or all of the dimensions contain non-zero values. MongoDB Vector Search uses dense vectors, which are packed with more data, to capture more complex relationships.
- deployment
- A group of MongoDB servers containing your data. MongoDB Atlas-managed clusters are clusters (replica sets or sharded clusters).
- dimensions
- Number of components or elements that make up the features or
attributes of data in multi-dimensional space. MongoDB Vector Search supports up
to
4096dimensions at index-time and query-time. - document
- A record in a MongoDB collection and the basic unit of data in MongoDB. Documents are analogous to JSON objects but exist in the database in a more type-rich format known as BSON. See Documents.
- dot notation
- MongoDB uses the dot notation to access the elements of an array and to access the fields of an embedded document. See Dot Notation.
- dotProduct similarity
- Measures similarity between two vectors in multi-dimensional
space and returns a scalar value, which is positive when the
vectors point in roughly the same direction, negative when the
vectors point in opposite direction, and zero when the vectors
have no similarity. MongoDB Vector Search supports using
dotproductsimilarity function when searching for nearest neighbors. We recommend this similarity function instead of cosine similarity if the vectors are normalized to unit length. - draining
- The process of removing or "shedding" chunks from one shard to another. Administrators must drain shards before removing them from the cluster. See Remove Shards from a Sharded Cluster.
- driver
- A client library for interacting with MongoDB in a particular computer language. See driver.
- durable
- A write operation is durable when it persists after a shutdown (or
crash) and restart of one or more server processes. For a single
mongodserver, a write operation is considered durable when it has been written to the server's journal file. For a replica set, a write operation is considered durable after the write operation achieves durability on a majority of voting nodes and written to a majority of voting nodes' journals. - electable node
- Node which is eligible to become the primary member of your replica set. MongoDB Atlas prioritizes nodes in the highest priority region for primary eligibility during elections. To ensure reliable elections, the total number of electable nodes across an entire region must be 3, 5, or 7.
- election
- The process where members of a replica set select a primary on startup and in the event of a failure. See Replica Set Elections.
- embedding
- Representation of data such as text, images, audio, video,
and so on as an array of numbers, which can be interpreted as
coordinates in multi-dimensional space. MongoDB Atlas supports storing
embeddings in an MongoDB Atlas cluster and MongoDB Vector Search supports indexing
and querying vector embeddings of up to
4096dimensions. - encryption key
Random string of bits generated specifically to encrypt and decrypt data.
MongoDB Atlas
Project Ownerscan configure an additional layer of encryption on their data in addition to the default encryption at rest that MongoDB Atlas provides. Project owners can use their MongoDB Atlas-compatible customer key management provider with the MongoDB encrypted storage engine.MongoDB Atlas supports the following customer key management providers when configuring Encryption at Rest:
- encryption schema
- In Queryable Encryption, the encryptedFields document that defines which fields are queryable and which query types are permitted on those fields.
- endianness
- In computing, endianness refers to the order in which bytes are arranged. This ordering can refer to transmission over a communication medium or more commonly how the bytes are ordered in computer memory, based on their significance and position. For details, see big-endian and little-endian.
- envelope encryption
- An encryption procedure where data is encrypted using a Data Encryption Key and the data encryption key is encrypted by another key called the Customer Master Key. The encrypted keys are stored as BSON documents in a MongoDB collection called the KeyVault.
- euclidean similarity
- Formula to calculate the similarity by using the distance between
two vectors in multi-dimensional space. Euclidean distance is
sensitive to the magnitude of the vectors. MongoDB Vector Search supports using
euclideansimilarity function for indexing vectors and when searching for nearest neighbors. - eventual consistency
- A property of a distributed system that allows changes to the system to propagate gradually. In a database system, this means that readable members aren't required to have the latest updates.
- explicit encryption
- When using In-Use Encryption, explicitly specifying the encryption or decryption operation, keyID, and query type (for Queryable Encryption) or algorithm (for Client-Side Field Level Encryption) when working with encrypted data. Compare to automatic encryption.
- expression
A component of a query that resolves to a value. Expressions are stateless, meaning they return a value without mutating any of the values used to build the expression.
In the MongoDB Query Language, you can build expressions from the following components:
ComponentExampleConstants
3Operators
Field path expressions
"$<path.to.field>"For example,
{ $add: [ 3, "$inventory.total" ] }is an expression that consists of the$addoperator and two operands:The constant
3The field path expression
"$inventory.total"
The expression returns the result of adding 3 to the value at path
inventory.totalof the input document.- failover
- The process that allows a secondary member of a replica set to become primary in the event of a failure. See Automatic Failover.
- field
- A name-value pair in a document. A document has zero or more fields. Fields are analogous to columns in relational databases. See Document Structure.
- field path
- Path to a field in a document. To specify a field path, use a
string that prefixes the field name with a dollar sign (
$). - firewall
- A system level network filter that restricts access based on IP addresses and other parameters. Firewalls are part of a secure network. See Firewalls.
- free and flex cluster
Cluster category containing
Free(free tier) tier clusters. Free and Flex clusters are generally used for development and small production workloads.- free tier
Free-to-use cluster tier that provides a small-scale development environment to host your data. Free clusters never expire, and provide access to a subset of Atlas features and functionality. Free clusters might also be referred to by their instance size,
M0.- fsync
A system call that flushes all dirty, in-memory pages to storage. As applications write data, MongoDB records the data in the storage layer.
To provide durable data, WiredTiger uses checkpoints. For more details, see Journaling and the WiredTiger Storage Engine.
- geohash
- A geohash value is a binary representation of the location on a coordinate grid. See Geohash Values.
- GeoJSON
- A geospatial data interchange format based on JavaScript Object Notation (JSON). GeoJSON is used in geospatial queries. For supported GeoJSON objects, see Geospatial Data. For the GeoJSON format specification, see https://tools.ietf.org/html/rfc7946#section-3.1.
- geospatial
- Relating to geographical location. See Geospatial Queries.
- global cluster
Clusters with defined geographic zones to support location-aware read and write operations for globally distributed application instances and clients. You can enable global sharding on clusters of tier
M30and greater.- global write zone
Geographic zone representing a subset of your global cluster distribution. Each global cluster supports up to 9 distinct global write zones. Each zone consists of one highest priority region and one or more electable, read-only, or analytics regions.
The available geographic regions depend on the selected cloud service provider.
- GridFS
- A convention for storing large files in a MongoDB database. All of
the official MongoDB drivers support the GridFS convention, as does the
mongofilesprogram. See GridFS. - group
- See project.
- group ID
- See project ID.
- hashed shard key
- A type of shard key that uses a hash of the value in the shard key field to distribute documents among members of the sharded cluster. See Hashed Indexes.
- health manager
- A health manager runs health checks on a health manager facet at a specified intensity level. The health manager checks are run at specified time intervals. A health manager can be configured to move a failing mongos out of a cluster automatically.
- health manager facet
- A set of features that a health manager can be configured to run health checks for. For example, you can configure a health manager to monitor and manage DNS or LDAP cluster health issues automatically. See Health Manager Facets for details.
- hidden member
- A replica set member that cannot become primary and are invisible to client applications. See Hidden Replica Set Members.
- hierarchical navigable small worlds graphs
- Algorithm for performing efficient nearest neighbor search in multi-dimensional space. MongoDB Vector Search performs ANN search with Hierarchical Navigable Small Worlds.
- high availability
High availability indicates a system designed for durability, redundancy, and automatic failover. Applications supported by the system can operate without downtime for a long time period. MongoDB replica sets support high availability when deployed according to the best practices.
For guidance on replica set deployment architecture, see Replica Set Deployment Architectures.
- highest priority region
Region in a multi-region cluster which MongoDB Atlas prioritizes for primary eligibility during elections.
- hybrid search
- Method of combining different search methods, such as a full-text and a semantic search, to take advantage of their respective strengths. The results are combined by using a technique such as Reciprocal Rank Fusion (RRF).
- idempotent
- An operation produces the same result with the same input when run multiple times.
- impact
Estimated performance improvement of an index that Performance Advisor suggests.
- in-memory sort
A sort that must be performed in memory before the output is returned. In-memory sorts may impact performance for large data sets. Use an indexed sort to avoid an in-memory sort.
See Sort and Index Use for more information on indexed sort operations.
- In-Use Encryption
- Encryption that secures data when transmitted, stored, and processed, and enables supported queries on that encrypted data. MongoDB provides two approaches to In-Use Encryption: Queryable Encryption and Client-Side Field Level Encryption.
- index
- A data structure that optimizes queries. See Indexes.
- index bounds
- The range of index values that MongoDB searches when using an index to run a query. To learn more, see Multikey Index Bounds.
- index signature
- The combination of parameters that uniquely identify the index.
- indexed sort
- A sort where an index provides the sorted result. Sort operations that use an index often have better performance than an in-memory sort. See Use Indexed to Sort Query Results for more information.
- init script
- A shell script used by a Linux platform's init system to start, restart, or stop a daemon process. If you installed MongoDB using a package manager, an init script is provided for your system as part of the installation. See the respective Installation Guide for your operating system.
- init system
- The init system is the first process started on a Linux platform
after the kernel starts, and manages all other processes on the
system. The init system uses an init script to start,
restart, or stop a daemon process, such as
mongodormongos. Recent Linux versions typically use the systemd init system and thesystemctlcommand. Older Linux versions typically use the System V init system and theservicecommand. See the Installation Guide for your operating system. - initial sync
- The replica set operation that replicates data from an existing replica set member to a new replica set member. See Initial Sync.
- intent lock
- A lock on a resource that indicates the lock holder will read from (intent shared) or write to (intent exclusive) the resource using concurrency control at a finer granularity than that of the resource with the intent lock. Intent locks allow concurrent readers and writers of a resource. See What type of locking does MongoDB use?.
- interface endpoint
AWS VPC endpoint with a private IP address that sends traffic to the MongoDB Atlas private endpoint service over AWS PrivateLink.
- interrupt point
- A point in an operation when it can safely end. MongoDB only ends an operation at designated interrupt points. See Terminate Running Operations.
- IP access list
List of IP addresses and CIDR blocks with access to clusters within an MongoDB Atlas project. For client connections over the public Internet, MongoDB Atlas allows connections to a cluster only from entries in the corresponding project's IP access list. The access list may have up to 200 entries.
MongoDB Atlas also allows client connections over nonpublic networking, such network peering connections or private endpoints. These types of connections work irrespective of the IP access list. To learn more, see Set Up a Network Peering Connection and Learn About Private Endpoints in Atlas.
- IPv6
- A revision to the IP (Internet Protocol) standard with a large address space to support Internet hosts.
- ISODate
- The international date format used by
mongoshto display dates. The format isYYYY-MM-DD HH:MM.SS.millis. - JavaScript
- A scripting language. mongosh, the legacy
mongoshell, and certain server functions use a JavaScript interpreter. See Server-side JavaScript for more information. - journal
- A sequential, binary transaction log used to bring the database into a valid state in the event of a hard shutdown. Journaling writes data first to the journal and then to the core data files. Journal files are pre-allocated and exist as files in the data directory. See Journaling.
- JSON
- JavaScript Object Notation. A plain text format for expressing structured data with support in many programming languages. For more information, see http://www.json.org. Certain MongoDB tools render an approximation of MongoDB BSON documents in JSON format. See MongoDB Extended JSON (v2).
- JSON document
- A JSON document is a collection of fields and values in a structured format. For sample JSON documents, see http://json.org/example.html.
- JSON pointer
- A string prefixed with a
/character that specifies a particular field value in a JSON document. - JSONP
- JSON with padding. Refers to a method of injecting JSON into applications. Presents potential security concerns.
- jumbo chunk
- A chunk that grows beyond the specified chunk size and cannot split into smaller chunks. For more details, see Indivisible/Jumbo Chunks.
- K-nearest neighbor search
- Given a set of points P with a defined similarity function S, for a query point q, finds the set of k points in P with the best values of S*(*p, q). MongoDB Vector Search ENN search returns the exact top k points and ANN search returns k points that are similar to q, but not necessarily the k most similar to q.
- key material
- The random string of bits used by an encryption algorithm to encrypt and decrypt data.
- key vault collection
- A MongoDB collection that stores the encrypted Data Encryption Keys as BSON documents.
- kyber scheduler
- An I/O scheduler designed to improve performance in environments with high resource contention. It improves I/O interpolation and reduces the latency impact of noisy neighbors.
- LDAP
- Cross-platform protocol used to authenticate users and authorize them to access data on a cluster. You can use MongoDB Atlas to manage user authentication and authorization from all MongoDB clients using your own LDAP server over TLS. A single LDAPS configuration applies to all clusters in an MongoDB Atlas project.
- least privilege
- An authorization policy that grants a user only the access that is essential to that user's work.
- legacy coordinate pairs
- The format used for geospatial data before MongoDB
version 2.4. This format stores geospatial data as points on a
planar coordinate system (for example,
[ x, y ]). See Geospatial Queries. - LineString
- A LineString is an array of two or more positions. A closed LineString with four or more positions is called a LinearRing, as described in the GeoJSON LineString specification: https://tools.ietf.org/html/rfc7946#section-3.1.4. To use a LineString in MongoDB, see GeoJSON Objects.
- link-token
- String that contains the information necessary to connect from Cloud Manager or Ops Manager to MongoDB Atlas during a live migration from a Cloud Manager or Ops Manager deployment to a cluster in MongoDB Atlas.
- little-endian
A byte order in which the least significant byte (little end) of a multibyte data value is stored at the lowest memory address.
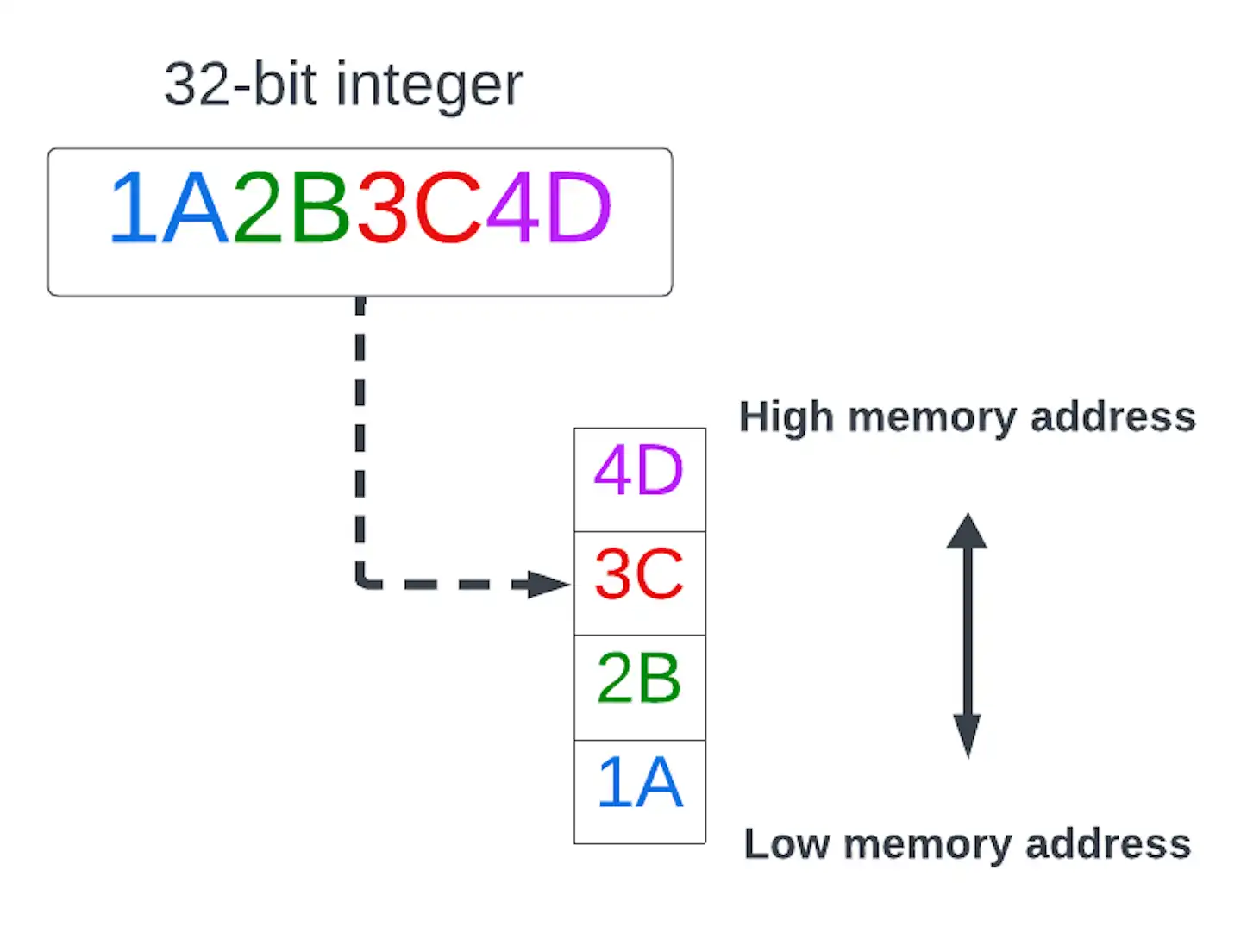 click to enlarge
click to enlarge- live migration
Process to seamlessly move an existing source replica set or sharded cluster to MongoDB Atlas. During the live migration process, MongoDB Atlas keeps the target cluster in sync with the remote source until you cut your applications over to the MongoDB Atlas cluster.
- lock
- MongoDB uses locks to ensure that concurrency does not affect correctness. MongoDB uses read locks, write locks and intent locks. For more information, see What type of locking does MongoDB use?.
- log files
- Contain server events, such as incoming connections, commands run, and issues encountered. For more details, see Log Messages.
- LVM
- Logical volume manager. LVM is a program that abstracts disk images from physical devices and provides a number of raw disk manipulation and snapshot capabilities useful for system management. For information on LVM and MongoDB, see Back Up and Restore Using LVM on Linux.
- maintenance window
Day and time of the week when MongoDB Atlas should start weekly maintenance on your cluster. You can set your maintenance window in your Project Settings.
Important
Maintenance Window Considerations
Urgent Maintenance Activities Urgent maintenance activities such as security patches cannot wait for your chosen window. MongoDB Atlas will start those maintenance activities when needed.
Ongoing Maintenance Operations Once maintenance is scheduled for your cluster, you cannot change your maintenance window until the current maintenance efforts have completed.
Maintenance Requires Replica Set Elections MongoDB Atlas performs maintenance the same way as the maintenance procedure described in the MongoDB Manual. This procedure requires at least one replica set election during the maintenance window per replica set.
Maintenance Starts As Close to the Hour As Possible Maintenance always begins as close to the scheduled hour as possible, but in-progress cluster updates or unexpected system issues could delay the start time.
- map-reduce
- An aggregation process that has a "map" phase that selects the data and a "reduce" phase that transforms the data. In MongoDB, you can run arbitrary aggregations over data using map-reduce. For the map-reduce implementation, see Map-Reduce. For all approaches to aggregation, see Aggregation Operations.
- mapping type
- A structure in programming languages that associate keys with values. Keys may contain embedded pairs of keys and values (for example, dictionaries, hashes, maps, and associative arrays). The properties of these structures depend on the language specification and implementation. Typically, the order of keys in mapping types is arbitrary and not guaranteed.
- md5
- A hashing algorithm that calculates a checksum for the supplied data. The algorithm returns a unique value to identify the data. MongoDB uses md5 to identify chunks of data for GridFS. See filemd5 (database command).
- mean
- Average of a set of numbers.
- median
- In a dataset, the median is the percentile value where 50% of the data falls at or below that value.
- member
- An individual mongod process. A replica set has multiple members. A member is also known as a node.
- metadata collection
- In Queryable Encryption, the internal collections MongoDB uses to enable querying on encrypted fields. See Metadata Collections.
- MIME
- Multipurpose Internet Mail Extensions. A standard set of type and
encoding definitions used to declare the encoding and type of data
in multiple data storage, transmission, and email contexts. The
mongofilestool provides an option to specify a MIME type to describe a file inserted into GridFS storage. - mode
- Number that occurs most frequently in a set of numbers.
- mongo
The legacy MongoDB shell. The
mongoprocess starts the legacy shell as a daemon connected to either amongodormongosinstance. The shell has a JavaScript interface.Starting in MongoDB v5.0,
mongois deprecated and mongosh replacesmongoas the client shell. See mongosh.- mongod
- The MongoDB database server. The
mongodprocess starts the MongoDB server as a daemon. The MongoDB server manages data requests and background operations. Seemongod. - MongoDB Charts
Visualization tool for your MongoDB Atlas data. You can launch MongoDB Charts from your MongoDB Atlas cluster and view your data with the Charts application to begin visualizing your data.
- MongoDB Search
Fine-grained text indexing enabling advanced text search on your data without any additional required management. MongoDB Search provides options for several kinds of text analyzers, score-based results ranking, and a rich query language.
- MongoDB Vector Search
- Feature that allows you to perform semantic search on vector embeddings by comparing query vectors with indexed vectors to find the closest match.
- mongos
- The MongoDB sharded cluster query router. The
mongosprocess starts the MongoDB router as a daemon. The MongoDB router acts as an interface between an application and a MongoDB sharded cluster and handles all routing and load balancing across the cluster. SeemongosInstances. - mongosh
MongoDB Shell. mongosh provides a shell interface to either a
mongodor amongosinstance.Starting in MongoDB v5.0, mongosh replaces
mongoas the preferred shell.- multi-region cluster
MongoDB Atlas cluster spanning multiple geographic regions. Multi-region clusters can increase availability and improve performance by routing application queries to the most appropriate geographic regions.
Multi-region clusters must contain electable nodes.
Multi-region clusters may contain read-only nodes and analytics nodes.
- namespace
- A namespace is a combination of the database name and
the name of the collection or index:
<database-name>.<collection-or-index-name>. All documents belong to a namespace. See Naming Restrictions. - Namespace Insights
MongoDB Atlas tool that monitors collection-level query latency. You can view query latency metrics and statistics for certain hosts and operation types. Manage pinned namespaces and choose up to five namespaces to show in the corresponding query latency charts.
- natural order
The order
recordIdsare created and stored in the WiredTiger index. The default sort order for a collection scan run on a single instance is natural order.In replica sets, natural order is not guaranteed to be consistent and can differ between members.
In sharded collections, natural order is not defined. However, using
$naturalstill forces each shard to perform a collection scan.For details, see Return in Natural Order.
- network partition
A network failure that separates a distributed system into partitions such that nodes in one partition cannot communicate with the nodes in the other partition.
Sometimes, partitions are partial or asymmetric. An example partial partition is the a division of the nodes of a network into three sets, where members of the first set cannot communicate with members of the second set, and the reverse, but all nodes can communicate with members of the third set.
In an asymmetric partition, communication may be possible only when it originates with certain nodes. For example, nodes on one side of the partition can communicate with the other side only if they originate the communications channel.
- network peering connection
Process by which two Internet networks connect and exchange traffic. You can directly peer your VPC with the MongoDB Atlas VPC created for your MongoDB clusters. Using network peering, your application servers can directly connect to MongoDB Atlas while remaining isolated from public networks.
- node
- An individual mongod process. A replica set has multiple nodes. A node is also known as a member.
- none scheduler
- The
nonescheduler option in the multi-queue block layer queueing mechanism (blk-mq) serves the same purpose as the legacy No Operation (noop) scheduler. It performs no request scheduling and passes I/O operations as received to the block device driver. - noop
- The No Operation (
noop) scheduler allocates I/O bandwidth for incoming processes based on a first in, first out (FIFO) queue. Starting in Linux kernel 5.3, this scheduler is replaced by the functionally equivalentnonescheduler. - normalized string
- The Unicode Normalized Form of a string applies Unicode code points in a standardized manner. Two strings may appear identical to a user, but have differences such as the order of combining marks. Normalizing the strings ensures they have the same binary representation.
- NVMe
- NVMe (Non-Volatile Memory Express) is a protocol for accessing high-speed storage media.
- NVMe storage
Available for M40+ clusters hosted on AWS
For applications hosted on AWS which require low-latency and high-throughput IO, you can use the NVMe cluster class. The NVMe cluster class leverages a unique data protocol to greatly improve data access speeds.
NVMe clusters use a hidden secondary node consisting of a provisioned volume with high throughput and IOPS to facilitate backup.
- object identifier
- See ObjectId.
- ObjectId
- A 12-byte BSON type that is unique within a collection. The ObjectId is generated using the timestamp, computer ID, process ID, and a local process incremental counter. MongoDB uses ObjectId values as the default values for _id fields.
- operation log
- See oplog.
- operation metadata
- Information about the execution of processes rather than their content, such as the number and time of insert, update, and delete operations.
- operation rejection filter
- A rejected query shape. For more details, see Block Slow Queries with Operation Rejection Filters.
- operation time
- See optime.
- operational node
- Any electable node or a read-only node in your MongoDB Atlas cluster.
- operator
- A keyword beginning with
$used to express MQL components such as query predicates, expressions, and aggregation stages. For example,$gtis the MQL "greater than" operator. For available operators, see MongoDB Query Language Reference. - oplog
- A capped collection that stores an ordered history of logical writes to a MongoDB database. The oplog is the basic mechanism enabling replication in MongoDB. See Replica Set Oplog.
- oplog buffer collection
A temporary collection created during resharding operations that stores oplog entries from a donor shard.
Oplog buffer collections ensure that recipient shards can access oplog entries when they get deleted from the donor shard. Oplog buffer collections are removed when resharding is complete.
- oplog hole
- A temporary gap in the oplog because the oplog writes aren't in sequence. Replica set primaries apply oplog entries in parallel as a batch operation. As a result, temporary gaps in the oplog can occur from entries that aren't yet written from a batch.
- oplog window
- oplog entries are time-stamped. The oplog window is the time
difference between the newest and the oldest timestamps in the
oplog. If a secondary node loses connection with the primary, it can only use replication to sync up again if the connection is restored within the oplog window. - optime
A reference to a position in the replication oplog. The optime value is a document that contains:
- ordered query plan
- A query plan that returns results in the order consistent with the
sort()order. See Query Plans. - organization
Logical grouping of MongoDB Atlas projects. You can leverage an organization to manage billing, users, and security settings for the projects it contains.
Billing happens at the organization level while preserving visibility into usage in each project.
You can view all projects within an organization.
You can use teams to bulk assign organization users to projects within the organization.
- organization ID
- Unique 24-digit hexadecimal string used to identify your MongoDB Atlas organization. The Return All Organizations endpoint returns the ID of all organizations that the authenticated user executing the API call can access.
- orphaned cursor
- A cursor that is not correctly closed or iterated over in your application code. Orphaned cursors can cause performance issues in your MongoDB deployment.
- orphaned document
In a sharded cluster, orphaned documents are those documents on a shard that also exist in chunks on other shards. This is caused by a failed migration or an incomplete migration cleanup because of an atypical shutdown.
Orphaned documents are cleaned up automatically after a chunk migration completes. You no longer need to run
cleanupOrphanedto delete orphaned documents.- passive member
- A member of a replica set that cannot become primary
because its
members[n].priorityis0. See Priority 0 Replica Set Members. - per-CPU cache
- A type of cache that locally stores memory for a specific CPU core. Per-CPU caches are used by the new version of TCMalloc, which is introduced in MongoDB 8.0.
- per-thread cache
- A type of cache that locally stores memory for each application thread. Per-thread caches are used by the legacy version of TCMalloc, which is used in MongoDB 7.0 and earlier.
- percentile
- In a dataset, a percentile is a value where that percentage of the data is at or below the specified value. For details, see Calculation Considerations.
- Performance Advisor
MongoDB Atlas tool that monitors slow queries executed on your cluster and suggests indexes to improve query performance. Each index that the Performance Advisor suggests include an impact score indicating the potential performance improvement that index would bring.
- PID
- A process identifier. UNIX-like systems assign a unique-integer
PID to each running process. You can use a PID to inspect a
running process and send signals to it. See
/procFile System. - pipe
- A communication channel in UNIX-like systems allowing independent processes to send and receive data. In the UNIX shell, piped operations allow users to direct the output of one command into the input of another.
- pipeline
- A series of operations in an aggregation. See Aggregation Pipeline.
- plan cache query shape
A combination of query predicate, sort, projection, and collation. The plan cache query shape allows MongoDB to identify equivalent queries and analyze their performance.
For the query predicate, only the predicate structure and field names are used. The values in the query predicate aren't used. For example, a query predicate
{ type: 'food' }is equivalent to{ type: 'drink' }.To identify slow queries with the same plan cache query shape, each plan cache query shape has a hexadecimal
planCacheShapeHashvalue. For more information, see planCacheShapeHash and planCacheKey.Starting in MongoDB 8.0, the existing
queryHashfield is duplicated in a new field namedplanCacheShapeHash. If you're using an earlier MongoDB version, you'll only see thequeryHashfield. Future MongoDB versions will remove the deprecatedqueryHashfield, and you'll need to use theplanCacheShapeHashfield instead.- point
- A single coordinate pair as described in the GeoJSON Point specification: https://tools.ietf.org/html/rfc7946#section-3.1.2. To use a Point in MongoDB, see GeoJSON Objects.
- polygon
An array of LinearRing coordinate arrays, as described in the GeoJSON Polygon specification: https://tools.ietf.org/html/rfc7946#section-3.1.6. For Polygons with multiple rings, the first must be the exterior ring and any others must be interior rings or holes.
MongoDB does not permit the exterior ring to self-intersect. Interior rings must be fully contained within the outer loop and cannot intersect or overlap with each other. See GeoJSON Objects.
- post-image document
- A document after it was inserted, replaced, or updated. See Change Streams with Document Pre- and Post-Images.
- powerOf2Sizes
- A setting for each collection that allocates space for each
document to maximize storage reuse and reduce
fragmentation.
powerOf2Sizesis the default for TTL Collections. To change collection settings, seecollMod. - pre-image document
- A document before it was replaced, updated, or deleted. See Change Streams with Document Pre- and Post-Images.
- pre-splitting
- An operation performed before inserting data that divides the range of possible shard key values into chunks to facilitate easy insertion and high write throughput. In some cases pre-splitting expedites the initial distribution of documents in sharded cluster by manually dividing the collection rather than waiting for the MongoDB balancer to do so. See Create Ranges in a Sharded Cluster.
- prefix compression
- Reduces memory and disk consumption by storing any identical index key prefixes only once, per page of memory. See: Compression for more about WiredTiger's compression behavior.
- primary
- In a replica set, the primary is the member that receives all write operations. See Primary.
- primary key
- A record's unique immutable identifier. In RDBMS software, the primary
key is typically an integer stored in each row's
idfield. In MongoDB, the _id field stores a document's primary key, which is typically a BSON ObjectId. - primary shard
- Each database in a sharded cluster has a primary shard. It is the default shard for all unsharded collections in the database. See Primary Shard.
- priority
- A configurable value that helps determine which members in
a replica set are most likely to become primary.
See
members[n].priority. - privilege
- A combination of specified resource and actions permitted on the resource. See privilege.
- project
Logical grouping of clusters. You can have multiple clusters within a single project and multiple projects within a single organization.
Note
Project is synonymous with group.
- project ID
Unique 24-digit hexadecimal string used to identify your MongoDB Atlas project. The Get All Projects API endpoint returns the ID of all projects that the authenticated user executing the API call can access.
Note
Project ID is synonymous with group ID.
- projection
- A document supplied to a query that specifies the fields MongoDB returns in the result set. For more information about projections, see Project Fields to Return from Query.
- quantization
- Method of compressing the value of individual dimensions in a vector into a smaller range to reduce resource consumption and improve speed. MongoDB Vector Search supports indexing and querying quantized vectors.
- query
- A read request. MongoDB uses a JSON form of query language
that includes query operators with
names that begin with a
$character. Inmongosh, you can run queries using thedb.collection.find()anddb.collection.findOne()methods. See Query Documents. - query framework
- A combination of the query optimizer and query execution engine that processes an operation.
- query operator
- A keyword beginning with
$in a query. For example,$gtis the "greater than" operator. For a list of query operators, see query operators. - query optimizer
- A process that generates query plans. For each query, the optimizer generates a plan that matches the query to the index that returns the results as efficiently as possible. The optimizer reuses the query plan each time the query runs. If a collection changes significantly, the optimizer creates a new query plan. See Query Plans.
- query plan
- Most efficient execution plan chosen by the query planner. For more details, see Query Plans.
- query predicate
An expression that returns a boolean indicating whether a document matches the specified query. For example,
{ name: { $eq: "Alice" } }, which returns documents that have a field"name"whose value is the string"Alice".Query predicates can contain child expressions and operators for more complex matching. To see available query operators, see Query Predicates.
- Query Profiler
- MongoDB Atlas tool that diagnoses and monitors performance issues in your cluster. The Query Profiler can expose long-running queries and their performance statistics. You can filter the data returned by the Query Profiler to hone in on specific namespaces and operation types.
- query shape
- A query shape is a set of specifications that group similar queries. For details, see Query Shapes.
- range
- A contiguous range of shard key values within a chunk. Data ranges include the lower boundary and exclude the upper boundary. MongoDB migrates data when a shard contains too much data of a collection relative to other shards. See Data Partitioning with Chunks and Sharded Cluster Balancer.
- RDBMS
- Relational Database Management System. A database management system based on the relational model, typically using SQL as the query language.
- read concern
- Specifies a level of isolation for read operations. For example, you can use read concern to only read data that has propagated to a majority of nodes in a replica set. See Read Concern.
- read lock
- A shared lock on a resource such as a collection or database that, while held, allows concurrent readers but no writers. See What type of locking does MongoDB use?.
- read preference
- A setting that determines how clients direct read operations. Read preference affects all replica sets, including shard replica sets. By default, MongoDB directs reads to primaries. However, you may also direct reads to secondaries for eventually consistent reads. See Read Preference.
- read-only node
- Replica set in a dedicated geographic region that supplements your electable node regions. You can use read-only nodes to localize data where it is most frequently read to improve performance.
- Real-Time Performance Panel
MongoDB Atlas monitoring service that displays current network traffic, database operations on your clusters, and hardware statistics about your host machines. Use the RTPP to visually evaluate query execution times, monitor network activity, and discover potential replication lag on secondary members of replica sets.
- recall
- Measures the fraction of true nearest neighbors that were returned by an ANN search. This measure reflects how close the algorithm approximates the results of ENN search. The notation Recall@k refers to the measurement of how many of the true nearest neighbors were present in the top k results returned by MongoDB Vector Search.
- recovering
- A replica set member status indicating that a member is not ready to begin activities of a secondary or primary. Recovering members are unavailable for reads.
- relative system CPU utilization
The CPU utilization relative to the amount of baseline CPU assigned to a cloud instance. You can calculate relative system CPU utilization by dividing the absolute system CPU utilization by the amount of baseline CPU assigned to a cloud instance.
MongoDB caps relative system CPU utilization at 100%. When a cloud provider throttles CPU utilization for a cloud instance, or bursts CPU utilization for an instance above the baseline amount of CPU available to that instance, the relative system CPU value is 100%.
See also absolute system CPU utilization, and burstable instances.
- replica set
- Group of MongoDB servers that maintain the same data set. Replica sets provide redundancy, high availability, and are the basis for all production deployments.
- replication
- A feature allowing multiple database servers to share the same data. Replication ensures data redundancy and enables load balancing. See Replication.
- replication lag
- The time period between the last operation in the primary's oplog and the last operation applied to a particular secondary. You typically want replication lag as short as possible. See Replication Lag.
- resident memory
- The subset of an application's memory currently stored in physical RAM. Resident memory is a subset of virtual memory, which includes memory mapped to physical RAM and to storage.
- resource
- A database, collection, set of collections, or cluster. A privilege permits actions on a specified resource. See resource.
- role
- A set of privileges that permit actions on specified resources. Roles assigned to a user determine the user's access to resources and operations. See Security.
- rollback
- A process that reverts write operations to ensure the consistency of all replica set members. See Rollbacks During Replica Set Failover.
- rolling restart
- Process that restarts all nodes in the cluster in sequence. To maintain cluster availability, MongoDB Atlas restarts one node at a time starting with a secondary node. MongoDB Atlas always maintains a primary node until the rolling restart completes.
- scalar quantization
- Scalar quantization involves selecting the minimum and maximum values across all indexed vectors within a segment for each dimension, and producing equally sized bins between them. The mappings for each of these dimensions to the bins yields the new quantized values. MongoDB Vector Search supports automatic scalar quantization for your float32 vectors, and ingestion and indexing of your scalar quantized vectors from embedding providers.
- secondary
- A replica set member that replicates the contents of the master database. Secondary members may run read requests, but only the primary members can run write operations. See Secondaries.
- secondary index
- A database index that improves query performance by minimizing the amount of work that the query engine must perform to run a query. See Indexes.
- secondary member
- See secondary. Also known as a secondary node.
- seed list
- A seed list is used by drivers and clients (like
mongosh) for initial discovery of the replica set configuration. Seed lists can be provided as a list ofhost:portpairs (see Standard Connection String Format or through DNS entries.) For more information, see SRV Connection Format. - self-managed
- A MongoDB instance that is set up and maintained by an individual or organization, and not an external management or third-party services (such as MongoDB Atlas).
- semantic search
- Search for values that have a similar meaning to query. Semantic search captures the natural relationship between words or phrases even when there is no lexical overlap. Semantic search and vector search are often used interchangeably. MongoDB Vector Search supports semantic search on vector data stored in MongoDB Atlas clusters.
- set name
- The arbitrary name given to a replica set. All members of a
replica set must have the same name specified with the
replSetNamesetting or the--replSetoption. - shard
- A single
mongodinstance or replica set that stores part of a sharded cluster's total data set. Typically, in a production deployment, ensure all shards are part of replica sets. See Shards. - shard key
- The field MongoDB uses to distribute documents among members of a sharded cluster. See Shard Keys.
- sharded cluster
- The set of nodes comprising a sharded MongoDB
deployment. A sharded cluster consists of config servers,
shards, and one or more
mongosrouting processes. See Sharded Cluster Components. - sharding
- A database architecture that partitions data by key ranges and distributes the data among two or more database instances. Sharding enables horizontal scaling. See Sharding.
- shell helper
- A method in
mongoshthat has a concise syntax for a database command. Shell helpers improve the interactive experience. SeemongoshMethods. - similarity function
- Measures the similarity between two vectors. MongoDB Vector Search supports
euclidean,cosine, anddotProductsimilarity functions. - single-master replication
- A replication topology where only a single database instance accepts writes. Single-master replication ensures consistency and is the replication topology used by MongoDB. See Replica Set Primary.
- snappy
- A compression/decompression library to balance efficient computation requirements with reasonable compression rates. Snappy is the default compression library for MongoDB's use of WiredTiger. See Snappy and the WiredTiger compression documentation for more information.
- snapshot
- A snapshot is a copy of the data in a
mongodinstance at a specific point in time. You can retrieve snapshot metadata for the whole cluster or replica set, or for a single config server in a cluster. - softIRQ
- The CPU utilization metric that reflects a portion of CPU that a cloud instance currently uses to process software interrupt requests. On some cloud providers, this metric is useful for tracking CPU utilization on burstable instances.
- sort key
- The value compared against when sorting fields. To learn how MongoDB determines the sort key for non-numeric fields, see Comparison/Sort Order.
- split
- The division between chunks in a sharded cluster. See Data Partitioning with Chunks.
- SQL
- Structured Query Language (SQL) is used for interaction with relational databases.
- SSD
- Solid State Disk. High-performance storage that uses solid state electronics for persistence instead of rotating platters and movable read/write heads used by mechanical hard drives.
- stale read
- A stale read refers to when a transaction reads old (stale) data that has been modified by another transaction but not yet committed to the database.
- standalone
An instance of
mongodthat runs as a single server and not as part of a replica set. To convert a standalone instance to a replica set, see Convert a Standalone Self-Managed mongod to a Replica Set.Note
A standalone instance is not a replica set with only one member.
- stash collection
A temporary collection created on the recipient shard for each donor shard during resharding operations.
Stash collections temporarily hold documents that cannot be immediately inserted due to operation conflicts. For example, if a document's shard key has been updated, it now belongs to a different shard, and the order of operations applied to this document can be ambiguous. The recipient stores these documents in a stash collection until it can apply operations in the correct order.
- step down
The primary member of the replica set removes itself as primary and becomes a secondary member.
If a replica set loses contact with the primary, the secondaries elect a new primary. When the old primary learns of the election, it steps down and rejoins the replica set as a secondary.
If the user runs the
replSetStepDowncommand, the primary steps down, forcing the replica set to elect a new primary.
- storage engine
- The part of a database that is responsible for managing how data is stored and accessed, both in memory and on disk. Different storage engines perform better for specific workloads. See Storage Engines for Self-Managed Deployments for specific details on the built-in storage engines in MongoDB.
- storage order
- See natural order.
- strict consistency
- A property of a distributed system requiring that all members contain the latest changes to the system. In a database system, this means that any system that can provide data must contain the latest writes.
- Subject Alternative Name
- Subject Alternative Name (SAN) is an extension of the X.509 certificate which allows an array of values such as IP addresses and domain names that specify the resources a single security certificate may secure.
- sync
- The replica set operation where members replicate data from the primary. Sync first occurs when MongoDB creates or restores a member, which is called initial sync. Sync then occurs continually to keep the member updated with changes to the replica set's data. See Replica Set Data Synchronization.
- syslog
- On UNIX-like systems, a logging process that provides a uniform
standard for servers and processes to submit logging information.
MongoDB provides an option to send output to the host's syslog
system. See
syslogFacility. - tag
A label applied to a replica set member and used by clients to issue data-center-aware operations. For more information on using tags with replica sets, see Read Preference Tag Set Lists.
- tag set
- A document containing zero or more tags.
- tailable cursor
- For a capped collection, a tailable cursor is a cursor that remains open after the client exhausts the results in the initial cursor. As clients insert new documents into the capped collection, the tailable cursor continues to retrieve documents.
- team
- Group of Atlas users in the same organization. You can use teams to grant access to the same group of Atlas users across multiple projects. All users in the team share the same project access.
- term
- For the members of a replica set, a monotonically increasing number that corresponds to an election attempt.
- time series collection
- A collection that efficiently stores sequences of measurements over a period of time. See Time Series.
- topology
The state of a deployment of MongoDB instances. Includes:
Type of deployment (standalone, replica set, or sharded cluster).
Availability of servers.
Role of each server (primary, secondary, config server, or
mongos).
- transaction
- Group of read or write operations. For details, see Transactions.
- transaction coordinator
- A component of MongoDB that manages transactions in a replica set or a sharded cluster. It coordinates the execution and completion of multi-document transactions across nodes and allows a complex operation to be treated as an atomic operation.
- TSV
- A text-based data format consisting of tab-separated values.
This format is commonly used to exchange data between relational
databases because the format is suited to tabular data. You can
import TSV files using
mongoimport. - TTL
- Time-to-live (TTL) is an expiration time or period for a given piece of information to remain in a cache or other temporary storage before the system deletes it or ages it out. MongoDB has a TTL collection feature. See Expire Data from Collections by Setting TTL.
- unbounded array
- An array that consistently grows larger over time. If a document field value is an unbounded array, the array may negatively impact performance. In general, design your schema to avoid unbounded arrays.
- unique index
- An index that enforces uniqueness for a particular field in a single collection. See Unique Indexes.
- unix epoch
- January 1st, 1970 at 00:00:00 UTC. Commonly used in expressing time, where the number of seconds or milliseconds since this point is counted.
- unordered query plan
- A query plan that returns results in an order inconsistent with the
sort()order. See Query Plans. - upgrade
- The process of changing a cluster from one version of MongoDB to a newer version.
- upsert
An option for update operations. For example:
db.collection.updateOne(),db.collection.findAndModify(). If upsert istrue, the update operation either:updates the document(s) matched by the query.
or if no documents match, inserts a new document. The new document has the field values specified in the update operation.
For more information about upserts, see Insert a New Document if No Match Exists (
Upsert).- vector database
- System that stores vector embeddings and associated metadata, and enables nearest neighbor search on the stored vector embeddings. You can use MongoDB Atlas as your vector database and MongoDB Vector Search to perform vector search on the stored vector embeddings. You can use vector database to implement RAG.
- vector index
- Data structure that efficiently processes nearest neighbor search
queries. MongoDB Vector Search supports creating indexes of type
vectorto index fields for running$vectorSearchqueries. - vector search
- Method of performing k nearest neighbor search over a set of vectors stored in a vector index. MongoDB Vector Search supports ANN and ENN search for k nearest neighbors.
- virtual memory
- An application's working memory, typically residing on both disk and in physical RAM.
- wall clock time
- The time that elapses between the start and completion of a computer program or calculation.
- WGS84
- The default reference system and geodetic datum that MongoDB uses to calculate geometry over an Earth-like sphere for geospatial queries on GeoJSON objects. See the "EPSG:4326: WGS 84" specification: http://spatialreference.org/ref/epsg/4326/.
- window operator
- Returns values from a span of documents from a collection. See window operators.
- working set
- The data that MongoDB uses most often.
- write concern
- Specifies whether a write operation has succeeded. Write concern
allows your application to detect insertion errors or unavailable
mongodinstances. For replica sets, you can configure write concern to confirm replication to a specified number of members. See Write Concern. - write conflict
- A situation where two concurrent operations, at least one of which is a write, try to use a resource that violates the constraints for a storage engine that uses optimistic concurrency control. MongoDB automatically ends and retries one of the conflicting write operations.
- write lock
- An exclusive lock on a resource such as a collection or database. When a process writes to a resource, it takes an exclusive write lock to prevent other processes from writing to or reading from that resource. For more information on locks, see FAQ: Concurrency.
- zlib
- A data compression library that provides higher compression rates at the cost of more CPU, compared to MongoDB's use of snappy. You can configure WiredTiger to use zlib as its compression library. See http://www.zlib.net and the WiredTiger compression documentation for more information.
- zone
- A grouping of documents based on ranges of shard key values for a given sharded collection. Each shard in the sharded cluster can be in one or more zones. In a balanced cluster, MongoDB directs reads and writes for a zone only to those shards inside that zone. See the Zones manual page for more information.
- zstd
- A data compression library that provides higher compression rates and lower CPU usage when compared to zlib.