Vince
(Vince)
1
Hey folks,
I store entities for countries all over the world, with around 15 popular countries amongst them. I have recently attempted to shard this collection as it grew larger. I index my entities with a unique hashed value which produces the shard key in combination with the corresponding country code.
I have performed sharding on this existing collection (not in a global cluster) with 3 shards, one being the config server. I used the sh.shardCollection command with a compound index { countryCode, entityId } . I only run the necessary commands in the process (create index, enable sharding).
After a few days, the balancing completed. My shards look the following:
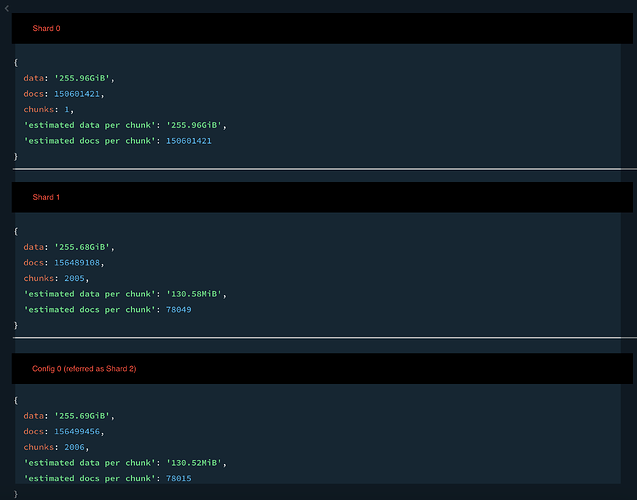
shard0 (primary shard): 1 chunk from the sharded collection + rest of the unsharded collections, 500 GB
shard1: 2000 chunks from the sharded collection, 250 GB
shard2 (config): 2000 chunks from the sharded collection, 250 GB
shard0 is the primary. Based on data volume, it seems to hold around the same (250GB) of data for the sharded collection - but all in one chunk! The chunk is not a jumbo chunk, and there is no apparent pattern in the shard keys. shard1 and shard2 seem to contain entities from country A to SX. However, the entities from the rest SY - Z countries all go into shard0’s one chunk.
The balancer is enabled, and all settings are on default. There are daily data updates coming in which read and write the database (creating or updating entities for various countries including for countries between SY-Z).
I have also tried to split the chunk manually according to this page: https://www.mongodb.com/docs/manual/tutorial/split-chunks-in-sharded-cluster/
What I experienced is that the chunk is split after I run the command - however, after around 60 minutes shard0 goes back to having 1 chunk only.
Has anyone experienced a similar issue?
Vince
(Vince)
2
I found out that this might be a feature of mongodb v6+:
Chunks are not subject to auto-splitting. Instead, chunks are split only when moved across shards.
Does anyone know if there is any downsides to a chunk growing too large? And does anyone have an explanation for why chunk splits by sh.splitFind are not persisted?
Here is a screenshot from the output of getShardDistribution . This shows that the data is distributed equally by disk usage, but the number of chunks are highly unbalanced.
Hi Vince
You are correct — starting with MongoDB 6.0, we introduced a new sharding balancer policy based on data size rather than number of chunks. This means that chunks will only be split when they need to be moved. As a result, it’s completely expected to see only one chunk on a specific shard in certain cases.
Additionally, in MongoDB 7.0, we introduced the automerge feature, which is enabled by default. With automerge, the server can automatically merge adjacent chunks on the same shard, provided they meet the mergeability requirements. This explains why your previously split chunks may seem to “disappear” — they’re being merged automatically.
To summarize:
- With the balancer enabled, it utilizes the data size policy to split and move chunks as needed to ensure even data distribution.
- Once split chunks are moved and become eligible for merging, the server can automatically combine adjacent chunks on the same shard.
If you have any further questions or need additional clarification on this topic, feel free to ask—I’d be happy to help!
bigbit
(bigbit)
4
Hi everyone,
I’d like to continue this discussion, as I have a similar situation to what Vince described earlier.
I currently have 6 shards, each holding a single chunk of approximately 260 GB. The shard key is a hashed GUID.
Now, I want to add 3 new shards and rebalance the existing data evenly across all 9 shards.
I ran the following command:
db.adminCommand({
moveChunk: “db.coll”,
find: { HashedGUID: “-3074457345618258602” },
to: “mongodb-load-mongodb-sharded-shard-6”
})
This successfully moved the entire chunk to the new shard — but it was not split. So the whole 260 GB chunk ends up on one shard.
What is the correct way to rebalance data across new shards in MongoDB 8, given that each chunk is so large? I want the existing data to be redistributed evenly across all 9 shards (including the new ones).
Thanks a lot.
Output of getShardDistribution()
{
data: “259.54GiB”,
docs: 116906238,
chunks: 1,
“estimated data per chunk”: “259.54GiB”,
“estimated docs per chunk”: 116906238
}
Totals Across All Shards
{
data: “1557.11GiB”,
docs: 701375773,
chunks: 6,
“Shard mongodb-load-mongodb-sharded-shard-0”: [
“16.66 % data”,
“16.66 % docs in cluster”,
“2KiB avg obj size on shard”
],
“Shard mongodb-load-mongodb-sharded-shard-1”: […],
“Shard mongodb-load-mongodb-sharded-shard-2”: […],
“Shard mongodb-load-mongodb-sharded-shard-3”: […],
“Shard mongodb-load-mongodb-sharded-shard-4”: […],
“Shard mongodb-load-mongodb-sharded-shard-5”: […]
}
(All shards have identical load, ~16.66% each, with 1 chunk per shard.)