Hi @Jason_Tran thanks for sharing the tips + the other post. I’m in contact with Vercel community/support as well to solve the problem.
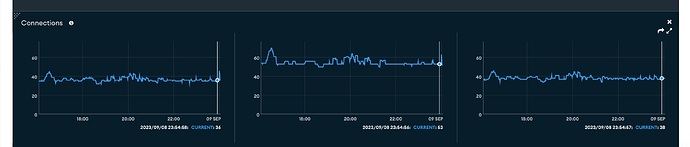
I did check the logs for my cluster however, and I see this:
Automation Agent v13.4.2.8420 (git: <id>)"}}}}
{"t":{"$date":"2023-09-28T16:25:39.414+00:00"},"s":"I", "c":"ACCESS", "id":20250, "ctx":"conn115096","msg":"Authentication succeeded","attr":{"mechanism":"SCRAM-SHA-256","speculative":true,"principalName":"__system","authenticationDatabase":"local","remote":"192.168.254.146:43258","extraInfo":{}}}
{"t":{"$date":"2023-09-28T16:25:39.415+00:00"},"s":"I", "c":"-", "id":20883, "ctx":"conn115094","msg":"Interrupted operation as its client disconnected","attr":{"opId":31692522}}
{"t":{"$date":"2023-09-28T16:25:39.415+00:00"},"s":"I", "c":"NETWORK", "id":22944, "ctx":"conn115095","msg":"Connection ended","attr":{"remote":"192.168.254.146:43252","uuid":"ea3b6fab-f503-49f9-8af1-b71110d04158","connectionId":115095,"connectionCount":40}}
Basically, it looks the authentication succeeded, then client disconnect immediately after, then it logged a “Connection ended” message.
I don’t think this is expected behavior, that is, for a client to disconnect immediately after authenticated. Please confirm, and in the mean time, I’m debugging the problem on Vercel’s end.