Munna_Ram
(Munna Ram)
1
I want to send a request for multiple (let n=5), query vectors to find top 100 matching documents.
I am sending requests for all of them one by one.
Is there any method by using that I can get the result in a single request by searching with ANN in parallel for each query.
Shane
(Shane Harvey)
2
Would it be possible to run $facet with multiple $vectorSearch stages?
Something like:
pipeline = [{'$facet':
{
'query1': [{'$vectorSearch': {...}],
'query2': [{'$vectorSearch': {...}],
...
}
}]
docs = list(coll.aggregate(pipeline))
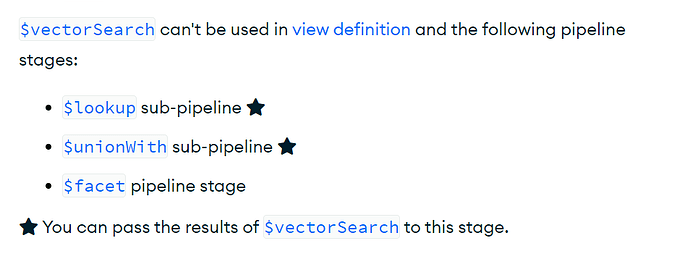
@Shane unfortunately $vectorSearch cannot be run as a pipeline within $facet so this wouldn’t work. I just tested this and you get:
pymongo.errors.OperationFailure: $vectorSearch is not allowed to be used within a $facet stage, full error: {'ok': 0.0, 'errmsg': '$vectorSearch is not allowed to be used within a $facet stage', 'code': 40600, 'codeName': 'Location40600', '$clusterTime': {'clusterTime': Timestamp(1721312815, 1), 'signature': {'hash': b'zl\xbd\x87\xb9\xb1\x00\xcf\xf8QS\x99Z;\xe8\xcb\xbe\x91\xd4\xe1', 'keyId': 7359286720640057346}}, 'operationTime': Timestamp(1721312815, 1)}
@Munna_Ram can you share more details about the different types of query vectors and what they represent and what indexed fields you’d like to compare them to?
Munna_Ram
(Munna Ram)
4
@Henry_Weller
In my database I have documents with “DocEmbedding” as vector field with 768 dimensions, and some other fields like id, text, etc.
I want to query top 10 similar documents for the input query.
I have 10 different queries and I want to get results for them.
As they are independent then I want to perform this task in parallel for all 10 queries instead of sending requests in a loop to improve the performance of my application. I can do it by sending requests with different threads to get results in parallel but creating threads is a costly task.
So is it possible to execute $VectorSearch pipeline for each query independently and then return results for all queries in a list?
Munna_Ram
(Munna Ram)
5