With the volume of data produced every day and its importance in our day-to-day lives, it’s certainly understandable that global data creation is booming. In fact, by 2025, our global data creation will triple, and it's anticipated that there will be exponential data growth beyond that point.

Source: Statista, 2020.
Given this level of data creation and usage, it's common for many of us to hear terms such as “structured data” and “unstructured data” used on a regular basis. However, these terms can often be misunderstood and misused, resulting in everything from poor business decisions to consumers misunderstanding how their personal data is stored, secured, and used.
Read on to learn more about structured and unstructured data, including the differences between these two data types, how each type of data is stored, the best uses for each type of data, and anticipated future trends relating to structured and unstructured data.
Understanding structured and unstructured data
The key to understanding structured vs unstructured data is to grasp the differences in each type of data's characteristics, storage, and usage. It's also helpful to understand the specialized tools used to work with each type of data and how they can be leveraged.
What is structured data?
Structured data is usually composed of alphanumeric characters translated from native format into a predefined format before being fed into a predetermined data model. This data model stores the structured data in cells, rows, and columns. A good way to visualize structured data is to think about how an Excel data sheet looks with its cells, rows, and columns. Examples of structured data include financial data, addresses, latitude and longitude, and dates.
Key characteristics of structured data
Some of the key characteristics of structured data include:
Quantitative data: Structured data is often referred to as quantitative data because it contains measurable numeric or text values that can be counted or analyzed (e.g., numbers, dates).
Relational databases: Structured data is stored in relational databases, meaning that the data is stored in data tables which are composed of rows and columns. Each column holds a certain kind of data (sometimes called an attribute), and each cell in the column holds the actual value. Each row (sometimes called a tuple) contains data pertaining to an individual entity.
In the example below, the table Customer Information contains the columns (or attributes) CustomerID, FirstName, LastName, and Address. Each row is made up of cells which contain information about each specific customer.

Source: PhoenixNAP Global IT Services, June 2021.
This data table illustrates how predefined relationships are created by the predefined model the structured data is housed within (e.g., the attributes of FirstName, LastName, Address assigned to CustomerID). Further, additional relationships can be created between tables using the unique identifier found in each row, called a primary key.
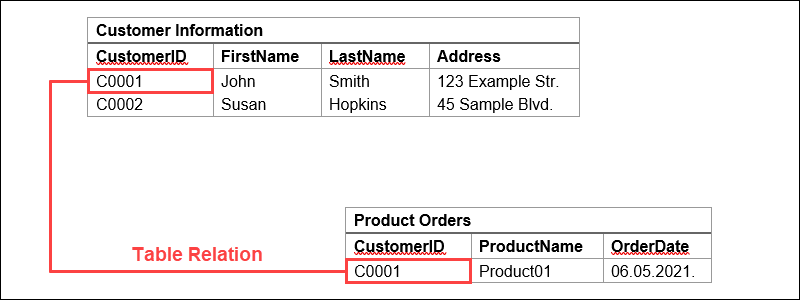
Source: PhoenixNAP Global IT Services, June 2021.
- RDBMS (relational database management systems): RDBMS are programs used to build and manage relational databases. The RDBMS is responsible for applying the logic to ensure ingested structured data is in the correct format as it is ingested into the database and is placed in the correct table(s), columns, and rows. SQL (structured query language) programming language is the primary language used by RDBMSs. Common types of RDBMS include:
- Microsoft SQL Server
- Oracle DB
- Amazon Aurora
- MySQL (opensource)
- PostgreSQL (opensource)
- SQLite (opensource)
- Data warehouses: Businesses frequently need to pull structured data from a variety of relational databases to perform data analysis. However, pulling from a variety of databases can be time consuming, so companies often build data warehouses which are central repositories of structured data from a variety of sources. The structured data stored in data warehouses is then accessed via specialized tools called OLAPs (Online Analytical Processing). OLAP tools help analysts conduct complex analytics on large quantities of data rapidly.
Structured data usage
The nature of structured data lends itself to a variety of industries. Examples of structured data usage include:
Accounting: Accounting firms and CPAs use structured data stored in data warehouses to record financial transactions, create financial statements, and complete tax returns.
Customer relationship management (CRM): Structured data in relational databases with its predefined format lends itself to CRM activities. This includes everything from administering loyalty programs for consumers (e.g., airlines, grocery stores) to businesses managing B2B customer relationships through CRM software such as Salesforce.
Search engine optimization (SEO): The use of structured data is critical in helping websites achieve higher rankings within search engine results pages (SERPs), gaining them more traffic and customers. Specifically, using structured data vs unstructured ensures search engines (like Google) are able to easily determine what a website is about as well as the quality of the content contained in the site by reading the site's schema markup code.
Data analytics/data mining: Business intelligence (BI) analysts and data scientists use structured data to complete complex analytics — such as descriptive, diagnostic, predictive, and prescriptive analysis — across a variety of industries. Data mining, where patterns are discovered in large data sets rather than applying specific queries to the data, is also a common use of structured data.
Machine Learning (ML): Machine learning algorithms, written by data scientists, are used to perform predefined analysis tasks on large data sets quickly — completing hundreds of analyses in seconds rather than the days it would take a human being running them individually.
What is unstructured data?
Unstructured data is data that cannot be analyzed or counted through traditional analytical methods. Further, unstructured data is stored in its native format, so it cannot be stored in a relational database which requires a predefined data model. Examples of unstructured data include satellite imagery, audio files, video files, or even emails.
Learn more about unstructured data.
Key characteristics of unstructured data
Some of the key characteristics of unstructured data include:
Qualitative data: Unstructured data is often referred to as qualitative data because it is nonnumeric, can contain images, and can be text-heavy in nature. In addition, this data is very difficult to analyze as unstructured data is stored in its native format and doesn't lend itself to the use of traditional analytics tools.
NoSQL databases: Unstructured data is highly variable in format. As a result, it requires a storage vehicle that is optimized for the data format being housed, as well as the scaling requirements needed to efficiently access that data (e.g., text files, videos, scanned documents). NoSQL databases, named such because they don't employ the SQL programming language, are non-tabular, and store data differently than relational tables.

Source: Edureka!, May 2020.
Some examples of NoSQL databases include:
- Document databases, which store data in documents similar to JSON (JavaScript Object Notation) objects. Each document contains pairs of fields and values. The values can be a variety of types, including strings, numbers, booleans, arrays, and objects.
- Key-value databases, which are a simpler type of database where each item contains keys and values.
- Wide-column stores, which store data in tables, rows, and dynamic columns.
- Graph databases, which store data in nodes and edges. Nodes typically store information about people, places, and things, while edges store information about the relationships between the nodes.
Data lakes: Since unstructured data is stored in its native format rather than a predefined data model, an alternative to traditional data warehouses is needed — that alternative is data lakes. Data lakes are centralized repositories where unstructured and structured data can be stored at any scale, and data models are created at the time of analysis (e.g., schema-on-read). This flexibility in both scale and data models allows users to work with various types of data, such as audio and video files, social media content, sensor data (e.g., time series data), and defined data as well.

Unstructured data usage
Unstructured data, or nonrelational data, makes up a significant portion of the enterprise data that exists today. Examples of unstructured data used every day include:
Social media: Social media has a component of semi-structured data (e.g., data that does not conform to a data model but has some structure) but the content of each social media message itself is unstructured.
Email: While we sometimes consider this semi-structured, email message fields are text fields that are not easily analyzed. Email content may include video, audio, or photo content as well, making them unstructured.
Text files: Almost all traditional business files — including word processing documents (e.g., Google Docs or Microsoft Word), presentations (e.g., Microsoft PowerPoint), notes, and PDFs — are classified as unstructured data.
Survey responses: When open-ended feedback is gathered via survey (e.g., text box) or through respondents selecting "liked" photos, unstructured data is being gathered.
Scientific data: Scientific data can include field surveys, space exploration, seismic imagery, atmospheric data, topographic data, weather data, and medical data. While these types of data may have a base structure for collection, the data itself is often unstructured and may not lend itself to traditional analysis tools and dashboards.
Machine and sensor data: Billions of small files from IoT (Internet of Things) devices, such as mobile phones and iPads, generate significant amounts of unstructured data. In addition, business systems’ log files, which are not consistent in structure, also create vast amounts of unstructured data.
Comparing structured vs. unstructured data
Both structured and unstructured data have value. The key to unlocking the value stored in data is to understand the differences between these two types of data and how to effectively leverage these data types.
Table: Differences between structured data and unstructured data

Source: Lawtomated, Structured vs. Unstructured Data: What are they and why care?, April 2019.
Extracting data value
Structured data
The linear, controlled nature of structured data, or quantitative data, is excellent for statistical, big data analytics which uses similarly structured query language (SQL). This consistency of data format enables more simplified data management and faster search and analyze tasks via machine learning or data analysts. In addition, this format consistency also lends itself to the use of a data warehouse — a preferred data storage option for structured data given its dashboard functionality and structured data management efficiency.
Unstructured data
Unstructured data, using a NoSQL database such as MongoDB Atlas, can also provide advanced insights from qualitative data such as customer survey or social media data. It can also provide enough structure so that non-text assets can be queried, enabling facial recognition analysis from photographs or A/B testing of marketing video content.
Is the future of data structured or unstructured?
Analysts predict the global data sphere will grow to 163 zettabytes by 2025 (nRoad, 2022), which isn't surprising given how much data each individual generates every day, in addition to corporations and other organizations. Around 80% to 90% of data generated and collected by organizations is unstructured, and this is quickly growing. Due to this growth, mastering unstructured data management and data storage is critical.
For example, regulated industries such as financial services and personal banking have traditionally focused on quantitative, transactional data (e.g., structured data) but have come to realize that unstructured data is key to future fintech products and services.
In an interview at Fintech2030, industry expert Bob Legters commented that financial institutions should start thinking about what types of unstructured data will be useful for their organization and where they can source that unstructured data. Mr. Legters also noted that most global financial institutions are using third-party providers to source the additional data sets, rather than trying to create their own versions of unstructured data. This trend is anticipated to increase over the next 18 to 24 months.
With that said, many financial institutions may already be generating the types of unstructured data they seek but just don't know how to collect, store, and access it. In fact, it's estimated that two-thirds of financial data is hidden in content sources that are not readily transparent or structured. This is where partnerships with companies who are experts in unstructured data collection, storage, management, and analysis become a point of differentiation and innovation.
By gathering the low-hanging fruit of existing unstructured data and extracting value, fintech organizations can reap unstructured data benefits without paying for that data from a third party. In addition, by applying unstructured data storage and management as a backing service in their cloud environment, fintech companies can still remain in control of their environment and compliance without sacrificing their need for evolution in their data strategy. And, while the example discussed here is the fintech industry, this strategy applies across all industries as the future of data management and analysis is clearly unstructured.
Discover how to unlock the hidden value of unstructured data for yourself with the free tier of MongoDB Atlas.