When planning a new project or application, the discussion of database requirements will often come up. What type of database should be used? What’s the difference between relational and non-relational databases?
This article aims to address those questions by explaining what they are and how they differ, and to help you make an informed decision.
Data of the digital age can be categorized into operational and analytical data.
Operational data is used for day-to-day transactions and needs to be fresh—for example, product inventory and bank balance. Such data is captured in real-time using Online Transaction Processing (OLTP) systems.
Analytical data is used by businesses to find insights about customer behavior, product performance, and forecasting. It includes data collected over a period of time and is usually stored in OLAP (Online Analytical Processing) systems, warehouses, or data lakes.
Databases are the most efficient way to permanently store and fetch operational and analytical data digitally.
Based on their project requirements, companies need to choose a database that can:
- Store all types of data.
- Access required data quickly.
- Get instant insights to make strategic business decisions.
Most companies need both OLTP (operational) and OLAP (analytical) systems to store their data and can use a relational database, non-relational database, or both to serve their business purposes.
What is a relational database?
A relational database, or relational database management system (RDMS), stores information in tables. Often, these tables have shared information between them, causing a relationship to form between tables. This is where a relational database gets its name from.
A table uses columns to define the information being stored and rows for the actual data. Each table will have a column that must have unique values—known as the primary key. This column can then be used in other tables, if relationships are to be defined between them. When one table’s primary key is used in another table, this column in the second table is known as the foreign key.
The most common way of interacting with relational database systems is using SQL (Structured Query Language). Developers can write SQL queries to perform CRUD (Create, Read, Update, Delete) operations. A simple example of a query is:
SELECT PRODUCT_NAME, PRICE FROM PRODUCT WHERE PRODUCT _ID = 23;Imagine you run an online business. You have a variety of information that you store, like customer information, order information, and products. In a relational database, this would be stored in different tables with a key to join the tables when needed.
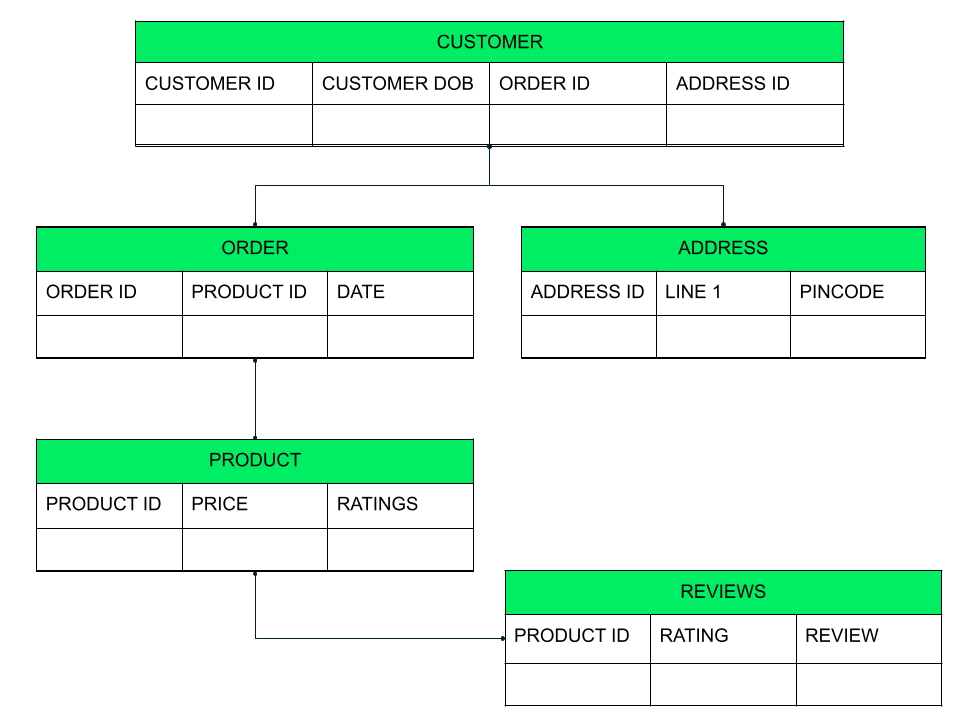
Data is stored as tables with rows and columns in a relational database
Here, the customer table stores the basic customer information, order id and address id. If someone needs more information on the order or address, they can query the matching order and address tables using an INNER JOIN operator with the id field. The order table in turn has product ids of the product items in the order. The details of the product are in a separate product table. This makes information organized and more structured.
Advantages of relational databases
ACID compliance
Atomicity, Consistency, Isolation, and Durability (ACID) is a standard that guarantees the reliability of database transactions. The general principle is if one change fails, the whole transaction will fail, and the database will remain in the state it was in before the transaction was attempted.
This is important because some transactions will have real consequences if not completed fully—for example, banking. For more information, see our documentation explaining ACID.
Data accuracy
Using primary and foreign keys allows you to ensure there is no duplicate information. This helps enforce data accuracy because there will never be repeated information
Normalization
The process of normalization involves ensuring the data is organized in such a way that data anomalies are reduced or eliminated. This, in turn, reduces storage costs.
Simplicity
RDMS, or SQL databases, have been around for so long that a wide variety of tools and resources have been developed to help get started and interact with relational databases. The English-like syntax of SQL also makes it possible for non-developers to generate reports and queries from the data.
Disadvantages of relational databases
Scalability
RDMSs are historically intended to be run on a single machine. This means that if the requirements of the machine are insufficient, due to data size or an increase in the frequency of access, you will have to improve the hardware in the machine, also known as vertical scaling.
This can be incredibly expensive and has a ceiling, as eventually the costs outweigh the benefits. Plus, there will potentially come a stage where you simply cannot get hardware capable of hosting the database. The only solution would be to buy a machine that supports better hardware, but none of that is cheap.
Flexibility
In relational databases, the schema is rigid. You define the columns and data types for those columns, including any restraints such as format or length. Common examples of constraints would include phone number length or minimum/maximum length for a name column.
Although this means you can interpret the data more easily and identify the relationships between tables, it means that making changes to the structure of the data is very complex. You have to decide at the start what the data will look like, which isn’t always possible. If you want to make changes later, you have to change all the data, which involves the database being offline temporarily.
Performance
The performance of the database is tightly linked to the complexity of the tables—the number of them, as well as the amount of data in each table. As this increases, the time taken to perform queries increases too.
What is a non-relational database?
A non-relational database, sometimes called NoSQL (Not Only SQL), is any kind of database that doesn’t use the tables, fields, and columns structured data concept from relational databases. Non-relational databases have been designed with the cloud in mind, making them great at horizontal scaling.
There are a few different groups of database types that store the data in different ways:
Document databases
Document databases store data in documents, which are usually JSON-like structures that support a variety of data types. These types include strings; numbers like int, float, and long; dates; objects; arrays; and even nested documents. The data is stored in pairs, similar to key/value pairs.
Consider the same customer example as above. In this case, however, we are able to view all the data of one customer in a single place as a single document.

How data is stored in a document non-relational database
Below is the query to get the product name and price of the given productid using the Mongo Query API (similar to SQL in the previous section). In this query, the first argument (_id) represents the filter to use on the collection, and the second one—the projection—fields that should be returned by the query.
db.product.find({"_id": 23}, {productName: 1, price: 1})Due to documents being JSON-like, they are much easier to read and understand for a user. The data is organized, and also easy to view. There is no need to reference multiple documents or collections to view data of a single customer. The documents map nicely to objects in code in object-oriented programming languages, making it much easier to work with.
There is also no schema, meaning you can have flexibility should documents of different shapes be inserted. However, some document database systems allow schema validation to be applied, should you want the other advantages of document databases but with a defined shape to the data.
Documents are considered individual units, which means they can be distributed across multiple servers. Plus, the databases are self-healing which means high availability.
Document databases are also highly scalable. Unlike relational databases, where traditionally, you can only scale vertically (CPU, hard drive space, etc.), non-relational databases, including document databases, can be scaled horizontally. This means having the databases duplicated across multiple servers, while still being kept in sync.
Key-value database
This is the most basic type of database, where information is stored in two parts: key and value.
The key is then used to retrieve the information from the database.
The simplicity of a key-value database is also an advantage. Because everything is stored as a unique key and a value that is either the data or a location for the data, reading and writing will always be fast.
However, this simplicity restricts the type of use cases it can be used for. More complex data requirements can’t be supported.
Graph databases
Graph databases are the most specialized of the non-relational database types. They use a structure of elements called nodes that store data, and edges between them contain attributes about the relationship.
Relationships are defined in the edges, which makes searches related to these relationships naturally fast. Plus, they are flexible because new nodes and edges can be added easily. They also don’t have to have a defined schema like a traditional relational database.
However, they are not very good for querying the whole database, where relationships aren’t as well—or at all—defined. They also don’t have a standard language for querying, which means moving between different graph database types comes with a learning requirement.
Wide-column databases
Wide-column databases, similar to relational databases, store data in tables, columns, and rows. However, the names and formatting of the columns don’t have to match in each row. The columns can even be stored across multiple servers. They are considered two-dimensional key-value stores because they use multi-dimensional mapping to reference data by row and column.
Like two-column key-value databases, wide-column databases have the benefit of being flexible, so queries are fast. They are good at handling “big data” and unstructured data because of this flexibility.
However, compared to relational databases, wide-column databases are much slower when handling transactions. Columns group together similar attributes rather than using rows and store these in separate files, which means transactions have to be carried out across multiple files.
When to use a relational database
If you’re creating a project where the data is predictable, in terms of structure, size, and frequency of access, relational databases are still the best choice.
Normalization can help reduce the size of the data on disk by limiting duplicate data and anomalies, decreasing the risk of requiring vertical scaling in future.
Relational databases are also the best choice if relationships between entities are important.
Non-relational databases can store documents within the documents, which helps keep data that will be accessed together in the same place. But if this isn’t right for your needs, a relational database is still the answer. For example, if you have a large dataset with complex structure and relationships, embedding might not create clear enough relationships.
The amount of time that RDMSs have been around also means there is wide support available, from tools to integration with data from other systems.
When to use a non-relational database
As discussed, there are many types of non-relational databases, each having their own advantages and disadvantages.
However, non-relational databases still maintain some consistent advantages. If the data you are storing needs to be flexible in terms of shape or size, or if it needs to be open to change in future, then a non-relational database is the answer.
Modern NoSQL databases have been designed for the cloud, making them naturally good for horizontal scaling where a lot of smaller servers can be spun up to handle increased load.
Learn how you can transition your project from relational to document-based non-relational databases.
Why might you prefer a non-relational database over a relational database?
There are many reasons why you’d want to use a non-relational database over a relational database:
- Non-relational databases are suitable for both operational and transactional data.
- They are more suitable for unstructured big data.
- Non-relational databases offer higher performance and availability.
- Flexible schema help non-relational databases store more data of varied types that can be changed without major schema changes.
Summary
In this article, you have learned about relational vs non-relational databases and how they differ from each other. You’ve also learned the advantages and disadvantages of both types of databases and which database type is most suitable for various projects.
| Features | Non-Relational | Relational |
|---|---|---|
| Availability | High | High |
| Horizontal Scaling | High | Low |
| Vertical Scaling | High | High |
| Data Storage | Optimized for huge data volumes | Medium to large data |
| Performance | High | Low To Medium |
| Reliability | Medium | High (Acid) |
| Complexity | Low | Medium (Joins) |
| Flexibility | High | Low (Strict-Schema) |
| Suitability | Suitable For OLAP and OLTP | Suitable For OLTP |
MongoDB is a non-relational database that offers scalability, high performance, reliability, and flexibility. MongoDB has grown into a wider data platform with MongoDB Atlas, MongoDB’s cloud-based database, which makes data available at all times.
FAQ
Are all databases relational?
No. Relational, or SQL databases, store data in tables with common columns between them (known as primary and foreign keys), forming relationships between tables. The data is always structured with a defined schema that cannot easily be changed.
But there are other database types, under the non-relational/NoSQL database title, that hold unstructured, semi-structured, or structured data. These allow for flexibility and high availability. Some examples are MongoDB, Cassandra, and CouchDB.
Is MongoDB a non-relational database?
Yes. MongoDB is a document database, which is a type of non-relational database. Data is stored in collections as BSON documents, which are JSON-like in structure. The data is considered unstructured because a collection can contain documents with different fields and data types. This allows for high flexibility.
What are some use cases for non-relational databases?
Due to the flexibility and scalability (both horizontally and vertically) of non-relational databases, they are great for a wide range of use cases.
For example, for storing settings in an app, a key-value database would be a great fit as each setting will have only one value. For an e-commerce site, a document database would be ideal as you can store a document for each client which will have their details and order history stored together as they are private and unique to each client.
For something like fraud detection, where the relationship between data is vital but the types of data will often be unpredictable, a graph database is a great solution.
For more information on when a non-relational database might not be the best fit, there is a white paper discussing this.
What is the difference between relational and non-relational databases?
When would you use a non-relational database?
What is an example of a non-relational database?
When would you choose a relational or non=relational database?
Relational databases are more suitable for data that’s not likely to change frequently. You can use relational databases for medium to large datasets.
For real-time data and faster query results, non-relational databases can be used. Also, non-relational databases can easily store huge amounts of unstructured data because of their flexible schema.
What is an example of a relational database?
Some popular examples of relational databases are MySQL, SQLServer, and Oracle.