Speed. It's everything in today's complex data environments; a critical factor in ensuring seamless user experiences and efficient business operations, in-memory databases play a crucial role in your tech stack.
In-memory databases offer unparalleled speed by storing data entirely in random access memory (RAM) instead of traditional disk-based storage. With their ability to reduce latency and deliver real-time data access, in-memory databases have become indispensable in applications where rapid data retrieval is crucial.
But what exactly is an in-memory database, and how does it differ from traditional databases? Is speed alone enough to justify adopting this technology, or are there other factors to consider? These questions are essential for developers, system architects, and business leaders looking to optimize their data management strategies while balancing performance, cost, and reliability.
In-memory databases have become a pivotal technology in modern applications requiring real-time data processing and low latency responses. Unlike traditional databases, an in-memory database system stores data entirely in a computer’s main memory (RAM) instead of on disk-based databases. This architecture allows faster access to frequently accessed data and ensures low latency for applications where speed is critical.
Table of contents
What is an in-memory database?
An in-memory database is a data storage software that holds all of its data in the memory of the host. The main difference between a traditional database and an in-memory database relies upon where the data is stored. Even when compared with solid-state drives (SSD), RAM is orders of magnitude faster than disk access. Because an in-memory database uses the latter for storage, access to the data is much faster than with a traditional database using disk operations.
In-memory databases provide quick access to their content. On the downside, they are at high risk of losing data in case of a server failure, since the data is not persisted anywhere. If a server failure or shutdown should occur, everything currently in the memory of that computer would be lost due to the volatile nature of RAM. It is also worth noting that the cost of memory is much higher than the cost of hard disks. This is why there is typically much more hard disk space than memory on modern computers. This factor makes in-memory databases much more expensive. They are also more at risk of running out of space to store data.
Your decision to use an in-memory database would depend on your use case. In-memory databases are great for high-volume data access where a data loss would be acceptable. Think of a large e-commerce website. The information about the products is crucial and should be kept on a persisted storage, but the information in the shopping cart could potentially be kept in an in-memory database for quicker access.
How does an in-memory database work?
An in-memory database works in a very similar way as any other database, but the data is kept in RAM rather than on a traditional disk. Replacing the disk access with memory operations highly reduces the latency required to access data.
Using RAM as a storage medium comes with a price. If a server failure occurs, all data will be lost.
As a way to prevent this, replica sets can be created in modern databases such as MongoDB with a mix of in-memory engines and traditional on-disk storage. This replica set ensures that at least another member of the cluster has another copy of the data. If we are more sophisticated, some of the members of the cluster are persisting data.
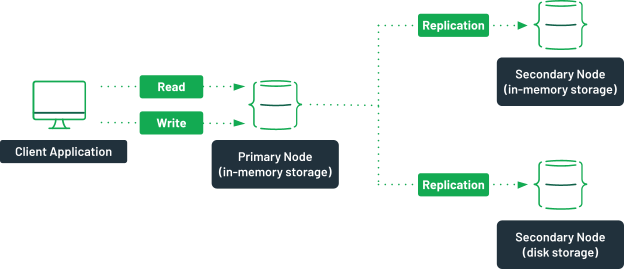
A replica set with both in-memory and traditional storage.
In this scenario, possible with MongoDB Enterprise Advanced, the primary node of the replica set uses an in-memory storage engine. It has two other nodes, one of which uses an in-memory storage, the other one using the WiredTiger engine. The secondary node using the disk storage is configured as a hidden member.
In case of a failure, the secondary in-memory server would become the primary and still provide quick access to the data. Once the failing server comes back up, it would sync with the server using the WiredTiger engine, and no data would be lost.
Many in-memory database offerings nowadays offer in-memory performance with persistence. They typically use a configuration similar to this one.
Similar setups can be done with sharded clusters when using MongoDB Enterprise Advanced.
Advantages of in-memory databases
Speed and performance
In-memory computing provides low latency responses by storing frequently accessed data in RAM. The speed of random access memory far outpaces even the fastest solid-state drives (SSDs), allowing real-time analytics and high-performance operations.
Efficient data access
Memory databases ensure fewer CPU instructions for accessing data, resulting in faster data retrieval and improved real-time data processing. With structured data stored in a directly usable format, these databases can handle complex operations quickly.
Scalability
Many in-memory database systems support horizontal scaling across multi-core servers, enabling applications to manage larger workloads efficiently.
Reduced complexity
By eliminating the need for traditional disk-based databases in certain scenarios, in-memory storage simplifies the overall data architecture and enhances user experiences with low latency.
Disadvantages of in-memory databases
Volatility and data durability
The primary trade-off for faster access is the potential for data loss due to the volatile nature of RAM. In the event of a server failure, power outage, or system crash, all data stored in memory could be lost unless persistent storage mechanisms like data replication or journaling are in place.
Cost
While lower RAM prices have made memory databases more accessible, RAM remains significantly more expensive than disk space. This makes in-memory solutions costlier compared to traditional databases.
Limited storage
On-disk databases typically offer more storage capacity, as disk space is less expensive and more abundant. In-memory databases, constrained by available RAM, may run out of storage, leading to failed write operations or the need to prioritize which data to store.
Why use an in-memory database?
The main use case for in-memory databases is when real-time data is needed. With its very low latency, RAM can provide near-instantaneous access to the needed data. Because of the potential data losses, in-memory databases without a persistence mechanism should not be used for mission-critical applications.
Any application where the need for speed is more important than the need for durability could benefit from an in-memory database over a traditional database.
In many cases, the in-memory database can be used only by a small portion of the total application, while the more critical data is stored in an on-disk database such as MongoDB.
In-memory database examples
In-memory databases can find their place in many different scenarios. Some of the typical use cases could include:
IoT data: IoT sensors can provide large amounts of data. An in-memory database could be used for storing and computing data to later be stored in a traditional database.
E-commerce: Some parts of e-commerce applications, such as the shopping cart, can be stored in an in-memory database for faster retrieval on each page view, while the product catalog could be stored in a traditional database.
Gaming: Leaderboards require quick updates and fast reads when millions of players are accessing a game at the same time. In-memory databases can help to sort the results more quickly than traditional databases.
Session management: In stateful web applications, a session is created to keep track of a user identity and recent actions. Storing this information in an in-memory database avoids a round trip to the central database with each web request.
In-memory use in MongoDB Atlas
MongoDB Atlas, the database-as-a-service offering by MongoDB, offers many possible configurations with regards to disk space, CPUs, and physical RAM. You can also choose the type of disk used in your cluster, such as the NVMe SSD drives, which would offer a performance close to that of a true in-memory database.
The available RAM offered for your Atlas instance will also have a significant impact on the speed at which data is accessed. This is due to how MongoDB, and more specifically its storage engine, WiredTiger, uses the available memory.
On MongoDB Atlas instances using the M40 tier or higher, 50% of the available memory is used for caching. The other 50% is used for in-memory operations and the other services running on the server.
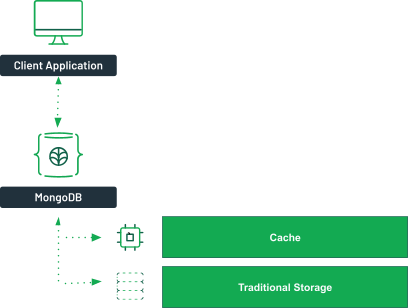
WiredTiger will try to fetch data from the cache, and then rely on disk storage.
The database engine cache holds the indexes to provide quicker access to the requested data. It also contains the data from recent queries. If the incoming queries are already in the cache, it can return them just as it would if it was served from an in-memory database.
You can take a look at this presentation to further understand how MongoDB manages memory.
Maximizing the benefits of in-memory databases
In-memory databases deliver unparalleled performance by storing data in a computer’s main memory, enabling faster access and real-time data processing with minimal latency. This makes them ideal for applications requiring frequent data retrieval, such as real-time analytics, session management, or online gaming.
By eliminating reliance on disk storage, memory databases provide high performance and low-latency responses, transforming how data is accessed and processed in demanding environments.
Balancing performance and persistence
While in-memory databases excel in speed and efficiency, they come with challenges such as higher costs due to RAM prices and the potential for data loss during a system failure or power outage. These databases are less suitable for applications where data durability is critical. To address these limitations, hybrid solutions, like MongoDB’s in-memory storage configurations combined with traditional disk-based options, ensure data persistence while maintaining high performance. Understanding these trade-offs allows you to harness the benefits of in-memory computing without compromising on data reliability or scalability.
If you're ready to give in-memory databases a try, you can give the in-memory storage engine with MongoDB Enterprise Advanced a spin or use MongoDB Atlas as a persistence layer alongside any other in-memory database.