Having a proper data modeling strategy is essential to a project for a variety of reasons. Modern applications require data, but how that data is modeled will have a drastic impact on the performance of the application, as well as the development speed. Proper data modeling management is integral to setting up an application for success from the beginning.
In this article, we will discuss what data modeling is, why data modeling is necessary, and important data modeling techniques that can be used in conjunction with MongoDB. Let’s get started!
Table of contents
- What is data modeling?
- What are the advantages of the data modeling process?
- How are data models used to address business needs?
- What are the 3 different types of data models?
- What does the process of data modeling look like?
- What is an example of a data model?
- What data modeling tools are available?
- Flexible data modeling with MongoDB Atlas
- Next steps
- FAQs
What is data modeling?
Data modeling is a process which identifies relevant data, how that data should be captured and worked with, and ultimately, how the data can be visualized as a diagram. This visual representation not only helps identify all data components, but also helps determine the relationships among data elements while finding the best way to demonstrate those relationships.
Data models consist of the following components:
Entity is defined as an independent object that is also a logical component in the system. Entities can be categorized as tangible and intangible. This means that tangible entities (such as books) exist in the real world, while intangible entities (such as book loans) don’t have a physical form.
Entity instances describe the specific instance of an entity group. For example, the tangible book entity “Alice in Wonderland” belongs to the specific instance of “book.”
Attributes describe the characteristics of an entity. For example, the entity “book” has the attributes International Standard Book Number or ISBN (String) and title (String).
Relationships define the connections between the entities. For example, one user can borrow many books at a time. The relationship between the entities "users" and "books" is one to many.
MongoDB supports multiple ways to model relationships between entities:
One to one (1-1): In this relationship, one field is associated with only one document. Another way of thinking about this example can be with the term value – entity. For example, a book can have only one ISBN.
Please also keep in mind that when we talk about a relationship between an entity and a value, it is represented as an attribute.
One to many (1-N): Here, one value can be associated with more than one document or value. Another way of thinking about this is with the term value – value or entity – entity. For example, a user can borrow more than one book at a time.
Many to many (N-N): In this type of model, multiple documents can be associated with each other. For example, a book can have many authors, and one author can write many different books. The relationship between author and book is many to many.
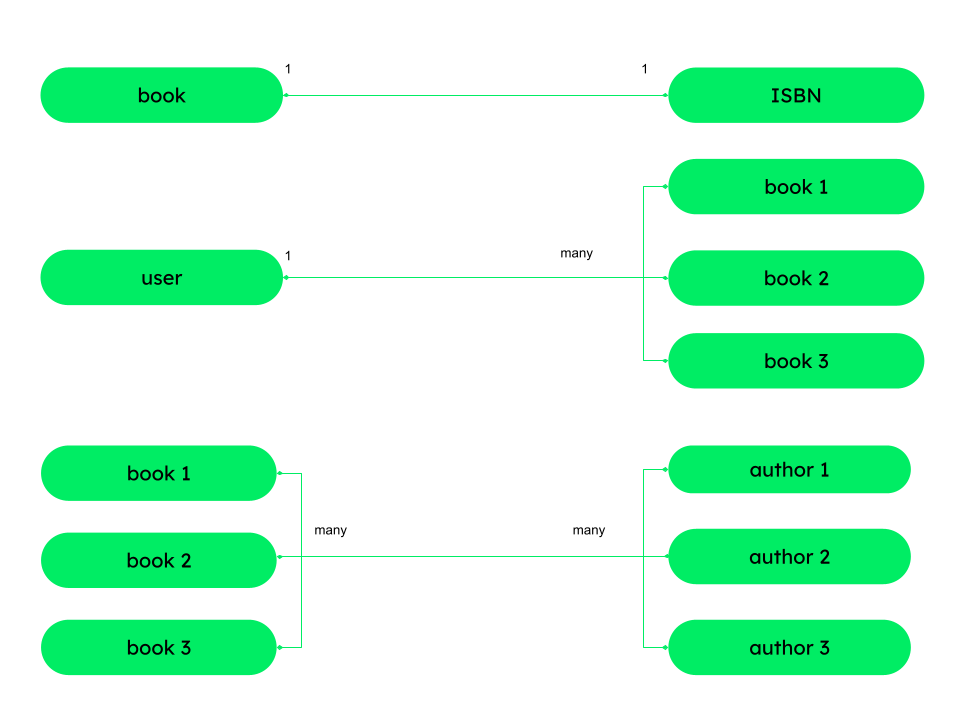
Data can have 1:1, 1:many or many:many relationships
To learn more about the basics, please watch our data modeling introduction video.
What are the advantages of the data modeling process?
While data modeling can initially just seem like an additional step, it is crucial for a successful application. Creating data models not only helps speed up development cycles as it helps overall efficiency, but it also aids in anticipating future business requirements which can save time and money, as proper data modeling helps you to better understand the data at hand. Specifically, using proper data models:
Ensures better database planning, design, and implementation, leading to improved application performance.
Promotes faster application development through easier object mapping.
Supports better discovery, standardization, and documentation of various data sources.
Allows organizations to think of long-term solutions and model data considering not only current projects, but also future requirements of the application, including maintenance.
Remember, just as selecting the right pattern is an important step in data modeling, it's also critical to avoid schema design anti-patterns. To learn more, read MongoDB's A Summary of Schema Design Anti-Patterns and How to Spot Them.
How are data models used to address business needs?
The impact of data modeling is felt throughout a business. It doesn’t just affect the person responsible for the data. The types of data modeling used; the application of conceptual, logical, and physical data models; and how data architects, information system analysts, and business intelligence analysts apply them to fulfill business needs may differ by industry. The ability to support business processes and critical business intelligence functions remains consistent, regardless of the industry.
Data analytics and business intelligence
It goes without saying that data modelers provide organizations with organized and accessible data. However, in addition to data management support, modeling also helps uncover business opportunities that were hidden due to a previously non-existent entity relationship or a better way to support business stakeholders by augmenting data-driven business processes or management systems.
What are the 3 different types of data models?
Data models are usually categorized as one of the following three types:
Conceptual data model: The conceptual data model explains what data the system should contain as well as the relationships among data elements. This model is usually built with the help of the business stakeholders, represents the application’s business logic, often contains principles referred to as domain-driven design (DDD), and is often used as the basis for one or more of the following models. The conceptual model is used to mainly identify the data that will be crucial to a business.
Logical data model: The logical data model describes how data will be structured. In this model, the relationship between entities is established at a high level and a list of entity attributes will also be represented. This data model can be thought of as a “blueprint” for the data that will be incorporated.
Physical data model: The physical data model represents how data will be stored in a specific database management system (DBMS). In this model, primary and secondary keys in a relational database are established, or the decision to embed or link data based on entity relationships in a document database such as MongoDB is made. This is also where data types for each of your fields will be established which, in turn, will provide the database schema.
Both logical data models and physical data models are created using a structural diagram called an entity relationship diagram (ERD). To learn more, an example of these data models can be found in the section titled What is an example of a data model? below.
What does the process of data modeling look like?
The data modeling process is a series of steps taken to create one of the data models described above, specifically for MongoDB, and may vary for other DBMS. These steps include:
Gathering requirements
The first step in the data modeling process is to gather all requirements for the application. This step helps uncover the underlying data structure that needs to be reviewed and it's important to not only analyze the data objects, but also the amount of data, the operations that will be performed on that data, and the frequency with which the operations will be performed. Often, domain experts are involved in helping provide requirements and are a valuable resource in making sure all information needed to draft your conceptual data model is present. The final result of this step is the complete conceptual model.
Understand relationships among entities
The next step is to understand the relationships between data entities that make up the data model. Try to think about how the objects are related (e.g., one to one, one to many, or many to many) and what data attributes will be used to describe these objects. The completion of this step results in the logical data model. A great way to decide whether to reference or embed data in a document is through using this great set of questions from the book MongoDB Data Modeling and Schema Design. These questions can help give “points” to each option:
Questions and points for embedding:
Simplicity: Would keeping the pieces of information together lead to a simpler data model and code?
- Yes – point for embedding
Go together: Do the pieces of information have a “has-a”, “contains”, or similar relationships?
- Yes – point for embedding
Query atomicity: Does the application query the pieces of information together?
- Yes – point for embedding
Update complexity: Are the pieces of information updated together?
- Yes – point to embedding
Archival: Should the pieces of information be archived at the same time?
- Yes – point for embedding
Questions and points for referencing:
Cardinality: Is there a high cardinality (current or growing) in a “many” side of the relationship?
- Yes – point for reference
Data duplication: Would data duplication be too complicated to manage and undesired?
- Yes – point for reference
Document size: Would the combined sizes of the pieces of information take too much memory or transfer bandwidth for the application?
- Yes – point for reference
Document growth: Would the embedded piece grow without bound?
- Yes – point for reference
Workload: Are the pieces of information written at different times in a write-heavy workload?
- Yes – point for reference
Individuality: For the children's side of the relationship, can the pieces exist by themselves without a parent?
- Yes – point for reference
Identify the data structure
This step considers the actual data stored in the database, and data modeling techniques will also depend on the type of DBMS used. For example, if using a relational database, identifying unique keys and field types, as well as normalizing data, will be necessary. However, with a document database, embedding related information may be warranted.
Regardless of the structure chosen, this step will produce a physical data model representing the initial database design.
Apply design patterns
Patterns make data modeling more efficient and effective. With design patterns, it’s easier to accommodate changes in application requirements and structure. There are a number of patterns to choose from, including schema versioning, bucket, computed, and tree, to name just a few. For a more complete list, including details on each pattern type, check out MongoDB's Building with Patterns: A Summary.
What is an example of a data model?
Imagine a scenario where you are building an application for the users of a library. How will you model this database?
Gather requirements
First, you will speak with business stakeholders, business analysts, and even clients to understand the entities that need to be part of your system. In an example where you are dealing with an organization such as a library, you’ll likely find out that the following entities must be included:
Books: The library has millions of books, and they all have a unique ISBN. The users will also need to search books by title or by author.
Users: This library has thousands of users and each user has a name and address. The library will also assign each user a unique number found on their library card.
There can be much more than two entities, but for the sake of simplicity, we will use these two for now.
Understand entity relationships
Understanding how these data entities (e.g., book ISBNs, user names) will interact with each other is also key. These interactions will comprise the relationships in your model.
Interaction example:
- Users borrow books: The library will need to know which books have been borrowed by which user. Each user is entitled to five borrowed books at a time.
These business rules enable organization of the information needed to build the conceptual model as you now understand the data necessary to build the first software iteration.

Organize the necessary data and show the main entities
Identify the data structure and apply your design patterns
Logical data model
Based on the information above, we can create a logical data model. As part of this modeling step, you might realize that some data structures are more complex and require new entities. For example, in this data model, the author names may be better represented as their own entities in order to enable searching for books by author.
For the diagram below, we are assuming there is one author per book, but it is possible to embed multiple authors in book documents and have them situated in an array due to the fact that after a book is published, the authors cannot change.
After considering the addition of new or modified entities, relationships between various data model objects will also begin to emerge. Consider the relational logical data model illustration below:
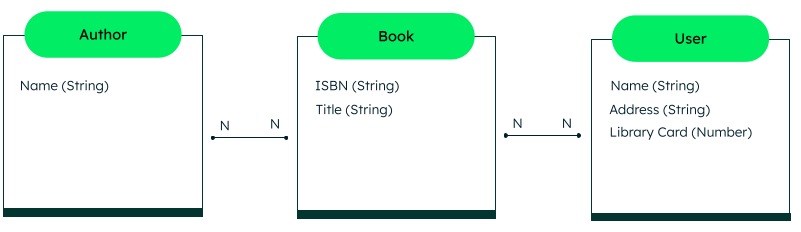
Showing the relationship between authors, books, and users.
Physical data model: document database
Now that we have our logical data model, aka our “blueprint,” let’s change this to represent a document database model. The specific modeling technique used will depend on the type of DBMS used. If using a document database, such as MongoDB, you'll model relationships using embedding or document references. As you establish the relationships between various objects, you'll also find the IDs and unique values representing each entity.
We can modify this diagram to accurately represent our book and user relationships:
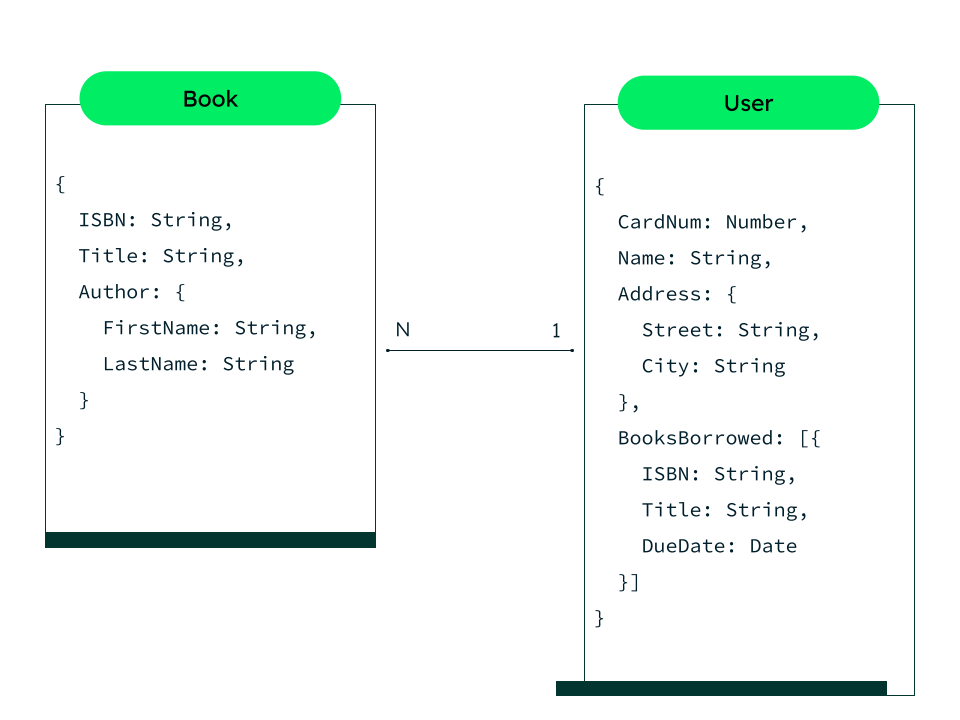
Physical data model representation for a document database
From this diagram, we can see that "author" was embedded in our "books" document. It was done this way because there is a one to one relationship between authors and books. For the sake of this example, we are searching for books based on authors, but there is no requirement to search for authors without a book context. This leads us to embed the author as a sub-document.
Users also have the ability to borrow multiple books, so our logic here is that our User document must have a BooksBorrowed array containing multiple books, if necessary. This is where we will reference the ISBN in our Users collection. Additionally, we will also use the extended reference pattern to add in our book “title”. Our book “title” will be immutable, so duplicating it across various users is not an issue.
We will also avoid embedding users into the books collection as the same book can be borrowed thousands of times and there is no need to show this information when doing a general book search. Let’s also use the questions from above in our “Understand relationships among entities” section to show how they can be applied in real time:
Books → Author
Simplicity answer: Yes – having the author name together with the book name will help find the book based on searching for the author.
Go together answer: Yes – books must have an author, every book has been written by at least one author, and there is no author if there are no books.
Query atomicity answer: Yes – the author needs to be shown with the book.
Users → Books
Simplicity answer: Yes (partial) – if we have only borrowed books, this will simplify the user and book relationship.
- Point for both embed and reference
Go together answer: No – not every user will borrow a book
Cardinality answer: Yes – a book can be borrowed multiple times and a book is not bound to a specific number of borrows.
- Point for reference
Workload answer: Yes – books and users are enrolled and can be changed at different times.
- Point for reference
Individuality: Yes – users can exist without borrowing books and books can exist without users borrowing them.
- Point for reference
The books borrowed are listed as an array in the user document because this information will generally be retrieved all at once on the application’s main page. However, a different use case with the same library data might have called for a different physical data model. The ISBN and CardNum fields are unique for the documents and could be used as the ID field. Both of the collections, ISBN, and CardNum can have a sharding key if there is a need to scale to multiple shards.
Physical data model: relational database
But what if we wanted to go with a relational database instead of a document database? Well, the physical data model will look very different. In this example, the authors and books tables are linked through a one to many relationship. The authorId field is the primary key in the authors table, and the authorId field is the foreign key in the books table. A joint table, an auxiliary table that contains references to the books and to the users that have borrowed them, is added to keep track of the borrowed books along with the due dates.
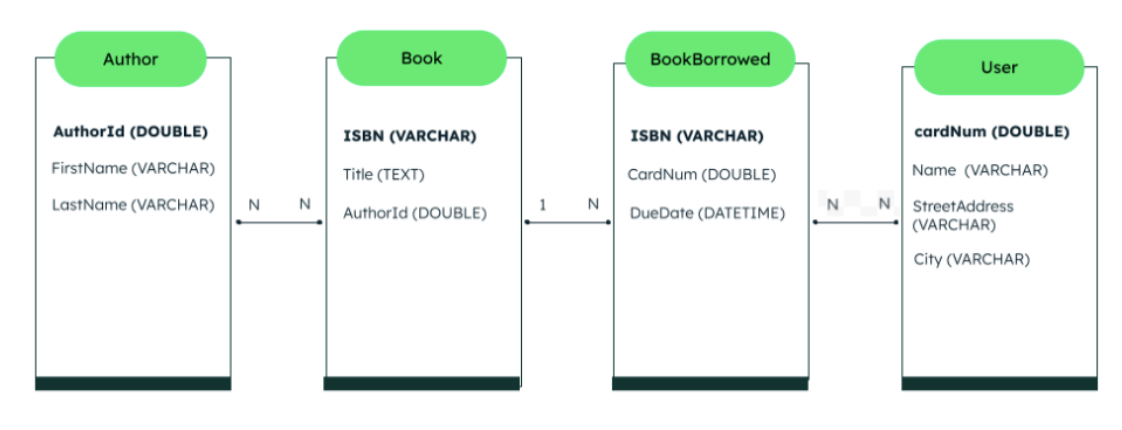
In this approach, there are expensive operations involved that are not needed for our document model. Remember, just as selecting the right pattern is an important step in data modeling, it's also critical to avoid schema design anti-patterns.
Through the progression of the data modeling steps in this example, an entire database model that describes how to store entities and address relationships among them has been created. These steps have also provided insights into keys and indexes as well.
What data modeling tools are available?
While our library example was simple enough to be represented through a simple drawing tool, other data models become more complex. For these intricate data models, you may require a more advanced data mapping tool. Here are some options to consider.
Hackolade: A general purpose tool that helps create visual representations of data for document or relational databases. It can even be used to create MongoDB schemas and get you up and running faster.
Open ModelSphere: A free open-source tool that helps you create most data models.
Creately: A general design tool supporting collaboration that helps you work on your data models together in real time.
PlantUML: Uses simple and human-readable text descriptions to draw UML diagrams.
All of these tools use standard universal markup language (UML) to build entity relationship diagrams (ERDs) and will provide professional-looking diagrams that can then be shared with your team.
Flexible data modeling with MongoDB Atlas
MongoDB provides a flexible schema for data, meaning that you can easily change data structures as your application progresses and requirements change. This flexibility enables you to restructure your schema and optimize your queries as many times as necessary.
In addition, as you model your data, think about how the data will be displayed and used in your application. The way you use the data will likely dictate the structure of your database, and not the other way around. This may be why MongoDB is so intuitive for software developers.
Next steps
Interested in learning even more? Here are three ways to level up your data modeling skill set.
Review the Data Modeling with MongoDB presentation to catch up on the latest trends in data modeling.
Try out MongoDB Atlas — MongoDB's fully managed database as a service (DBaaS) and see how this data modeling tool can take your projects to the next level.
Take a course on data modeling at MongoDB University and build your knowledge even further.