문서 데이터베이스란?
문서 데이터베이스(문서 지향 데이터베이스 또는 문서 저장소라고도 함)는 정보를 문서에 저장하는 데이터베이스입니다.

문서 데이터베이스에는 다음을 비롯한 여러 이점이 있습니다.
- 개발자가 빠르고 쉽게 작업할 수 있는 직관적인 데이터 모델
- 애플리케이션 요구 사항이 변경됨에 따라 데이터 모델을 발전시킬 수 있는 유연한 스키마
- 수평 확장 기능
이러한 이점 덕분에 문서 데이터베이스는 다양한 사용 사례와 산업에서 사용할 수 있는 범용 데이터베이스입니다.
문서 데이터베이스는 비관계형(또는 NoSQL) 데이터베이스로 간주됩니다. 문서 데이터베이스는 데이터를 고정된 행과 열에 저장하는 대신 유연한 문서를 사용합니다. 문서 데이터베이스는 테이블 형식의 관계형 데이터베이스를 대체하는 가장 인기 있는 대안입니다. NoSQL 데이터베이스에 대해 자세히 알아보기.
문서란 무엇인가요?
문서는 문서 데이터베이스의 기록입니다. 문서는 일반적으로 하나의 객체 및 이 객체와 관련된 메타데이터의 정보를 저장합니다.
문서는 필드-값 쌍으로 데이터를 저장합니다. 값은 문자열, 숫자, 날짜, 배열 또는 객체를 포함한 다양한 유형과 구조일 수 있습니다. 문서는 JSON, BSON, XML과 같은 형식으로 저장할 수 있습니다.
아래는 Tom이라는 사용자의 정보를 저장하는 JSON 문서입니다.
{
"_id": 1,
"first_name": "Tom",
"email": "tom@example.com",
"cell": "765-555-5555",
"likes": [
"fashion",
"spas",
"shopping"
],
"businesses": [
{
"name": "Entertainment 1080",
"partner": "Jean",
"status": "Bankrupt",
"date_founded": {
"$date": "2012-05-19T04:00:00Z"
}
},
{
"name": "Swag for Tweens",
"date_founded": {
"$date": "2012-11-01T04:00:00Z"
}
}
]
}컬렉션
컬렉션은 문서의 그룹입니다. 컬렉션은 보통 내용이 비슷한 문서를 저장합니다.
문서 데이터베이스의 스키마는 유연하므로, 컬렉션의 모든 문서가 동일한 필드를 가질 필요는 없습니다. 일부 문서 데이터베이스는 필요할 때 스키마를 선택적으로 잠글 수 있도록 스키마 유효성 검사를 제공합니다.
다시 위의 예로 돌아가서, Tom에 관한 정보가 포함된 문서는 users라는 컬렉션에 저장될 수 있습니다. 다른 사용자에 관한 정보를 저장하기 위해 users 컬렉션에 더 많은 문서를 추가할 수 있습니다. 예를 들어, Donna에 관한 정보가 저장된 아래 문서가 users 컬렉션에 추가될 수 있습니다.
{
"_id": 2,
"first_name": "Donna",
"email": "donna@example.com",
"spouse": "Joe",
"likes": [
"spas",
"shopping",
"live tweeting"
],
"businesses": [
{
"name": "Castle Realty",
"status": "Thriving",
"date_founded": {
"$date": "2013-11-21T04:00:00Z"
}
}
]
}Note that the document for Donna does not contain the same fields as the document for Tom. users 컬렉션은 각 사용자에 관한 정보를 저장하기 위해 유연한 스키마를 활용합니다.
CRUD 작업
문서 데이터베이스는 개발자가 CRUD(생성, 읽기, 업데이트, 삭제) 작업을 수행할 수 있도록 일반적으로 API 또는 쿼리 언어를 제공합니다.
- 생성: 데이터베이스에 문서를 생성할 수 있습니다. 각 문서에는 고유 식별자가 있습니다.
- 읽기: 문서는 데이터베이스에서 읽을 수 있습니다. 개발자는 API 또는 쿼리 언어를 사용하여 고유 식별자나 필드 값으로 문서를 쿼리할 수 있습니다. 데이터베이스에 인덱스를 추가하여 읽기 성능을 향상할 수 있습니다.
- 업데이트: 기존 문서를 전체적으로 또는 부분적으로 업데이트할 수 있습니다.
- 삭제: 데이터베이스의 문서를 삭제할 수 있습니다.
문서 데이터베이스의 주요 기능은 무엇인가요?
문서 데이터베이스의 주요 기능을 다음과 같습니다.
- 문서 모델: 테이블이나 그래프와 같은 구조에 데이터를 저장하는 여타 데이터베이스와 달리, 데이터는 문서에 저장됩니다. 문서는 자주 사용되는 대부분의 프로그래밍 언어 객체에 매핑되어 개발자가 애플리케이션을 신속하게 개발할 수 있게 합니다.
유연한 스키마: 문서 데이터베이스의 스키마는 유연하여 컬렉션의 모든 문서 필드가 동일하지 않아도 됩니다. 일부 문서 데이터베이스는 필요할 때 스키마를 선택적으로 잠글 수 있도록 스키마 유효성 검사를 지원합니다.
- 분산되고 탄력적인 데이터베이스: 문서 데이터베이스는 분산되어 있어 수평 확장(일반적으로 수직 확장보다 저렴)과 데이터 분산이 가능합니다. 문서 데이터베이스는 복제를 통해 탄력성을 제공합니다.
- API 또는 쿼리 언어를 통한 쿼리: 문서 데이터베이스는 개발자가 데이터베이스에서 CRUD 작업을 수행할 수 있도록 API 또는 쿼리 언어를 제공합니다. 개발자는 고유 식별자나 필드 값을 기반으로 문서를 쿼리할 수 있습니다.
문서 데이터베이스와 관계형 데이터베이스의 차이는 무엇인가요?
문서 데이터베이스와 관계형 데이터베이스를 구분하는 세 가지 주요 요소는 다음과 같습니다.
1. 데이터 모델의 직관성: 문서가 코드의 객체에 매핑되므로 훨씬 더 자연스럽게 작업할 수 있습니다. 테이블 간 데이터를 해체하거나, 비용이 많이 드는 결합을 실행하거나 별도의 객체 관계 매핑(ORM) 계층을 통합할 필요가 없습니다. 함께 액세스하는 데이터는 함께 저장되므로, 개발자가 작성해야 할 코드가 줄어들고 최종 사용자는 더 높은 성능을 얻을 수 있습니다.
2. JSON 문서의 보편성: JSON은 데이터 교환 및 저장을 위한 확고한 표준이 되었습니다. JSON 문서는 가볍고, 언어에 구애받지 않으며, 사람이 해독할 수 있습니다. 문서가 다른 모든 데이터 모델의 상위 집합이어서 개발자가 애플리케이션에 필요한 방식으로 데이터를 구조화할 수 있습니다. 여기에는 대량의 객체, 키-값 쌍, 테이블, 지리 공간적 데이터, 시계열 데이터, 또는 그래프의 노드와 엣지가 포함됩니다.
3. 스키마의 유연성: 문서의 스키마는 동적이고 자체 설명적이어서 개발자가 데이터베이스에서 사전에 정의할 필요가 없습니다. 문서의 필드는 문서마다 다를 수 있습니다. 개발자는 언제든지 방해가 되는 스키마 마이그레이션을 피하면서 구조를 수정할 수 있습니다. 일부 문서 데이터베이스는 문서 구조를 관리하는 규칙의 선택적 집행이 가능하도록 스키마 유효성 검사 기능을 제공합니다.
문서는 테이블에 비해 작업하기가 얼마나 더 쉬운가요?
개발자들은 보통 문서에서 데이터 작업을 하는 것이 테이블에서 데이터 작업을 하는 것보다 더 쉽고 직관적이라고 생각합니다. 문서는 대다수의 인기 있는 프로그래밍 언어의 데이터 구조에 매핑됩니다. 개발자는 데이터를 저장할 때 관련 데이터를 여러 테이블에 수동으로 분할하거나 검색할 때 재결합하는 일에 대해 염려할 필요가 없습니다. 데이터를 조작하기 위해 ORM을 사용할 필요도 없습니다. 개발자는 애플리케이션 내에서 직접 간편하게 데이터를 작업할 수 있습니다.
사용자 Tom을 위한 문서를 다시 살펴보겠습니다.
사용자
{
"_id": 1,
"first_name": "Tom",
"email": "tom@example.com",
"cell": "765-555-5555",
"likes": [
"fashion",
"spas",
"shopping"
],
"businesses": [
{
"name": "Entertainment 1080",
"partner": "Jean",
"status": "Bankrupt",
"date_founded": {
"$date": "2012-05-19T04:00:00Z"
}
},
{
"name": "Swag for Tweens",
"date_founded": {
"$date": "2012-11-01T04:00:00Z"
}
}
]
}Tom에 관한 모든 정보는 하나의 문서에 저장됩니다.
이제 같은 정보를 관계형 데이터베이스에 저장하는 방법을 살펴보겠습니다. 먼저 사용자에 관한 기본 정보를 저장하는 테이블을 만듭니다.
Users
| ID | first_name | cell | |
|---|---|---|---|
| 1 | Tom | tom@example.com | 765-555-5555 |
사용자 한 명이 여러 가지를 좋아할 수 있으므로(즉, 사용자와 좋아요 사이에 일대다 관계가 성립될 수 있으므로), 사용자의 좋아요를 저장하기 위한 새로운 "Likes" 테이블을 만듭니다. Likes 테이블에는 Users 테이블의 ID 열을 참조하는 외래 키가 있습니다.
Likes
| ID | user_id | like |
|---|---|---|
| 10 | 1 | fashion |
| 11 | 1 | spas |
| 12 | 1 | shopping |
마찬가지로 사용자는 여러 개의 비즈니스를 운영할 수 있으므로 "Businesses"라는 새 테이블을 만들어 비즈니스 정보를 저장하겠습니다. 비즈니스 테이블에는 Users 테이블의 ID 열을 참조하는 외래 키가 있습니다.
Businesses
| ID | user_id | name | partner | status | date_founded |
|---|---|---|---|---|---|
| 20 | 1 | Entertainment 1080 | Jean | Bankrupt | 2011-05-19 |
| 21 | 1 | Swag for Tweens | NULL | NULL | 2012-11-01 |
이 간단한 예에서 사용자에 관한 데이터가 문서 데이터베이스의 단일 문서나 관계형 데이터베이스의 테이블 세 개에 저장될 수 있음을 확인할 수 있습니다. 개발자는 문서 데이터베이스에서 사용자에 관한 정보를 조회하거나 업데이트하려고 할 때 결합이 없는 하나의 쿼리를 작성할 수 있습니다. 데이터베이스와의 상호 작용은 단순하며, 데이터베이스 내의 데이터 모델링은 직관적입니다.
SQL에서 MongoDB로 용어 및 개념 매핑을 방문하여 자세히 알아보세요.
문서 데이터베이스와 다른 데이터베이스 간의 관계는 무엇인가요?
문서 모델은 키-값 쌍, 관계형, 객체, 그래프, 지리 공간을 포함한 다른 데이터 모델의 상위 집합입니다.
- 키-값 쌍은 문서의 필드와 값으로 모델링할 수 있습니다. 문서의 모든 필드는 인덱싱될 수 있어서 개발자에게 추가적인 데이터 쿼리 유연성을 제공합니다.
- 관계형 데이터는 내장된 문서와 배열을 사용하여 관련 데이터를 하나의 문서에 함께 보관함으로써 다르게(일부의 주장으로는 더 직관적으로) 모델링할 수 있습니다. 관련 데이터는 별도의 문서에 저장할 수 있으며, 데이터베이스 참조를 사용하여 관련 데이터를 연결할 수 있습니다.
- 문서는 대다수의 인기 있는 프로그래밍 언어의 객체로 매핑됩니다.
- 그래프 노드 및/또는 엣지는 문서로 모델링할 수 있습니다. 엣지는 데이터베이스 참조를 통해서도 모델링할 수 있습니다. 그래프 쿼리는 $graphLookup과 같은 연산을 사용하여 실행할 수 있습니다.
- 지리 공간적 데이터는 문서 내 배열로 모델링될 수 있습니다.
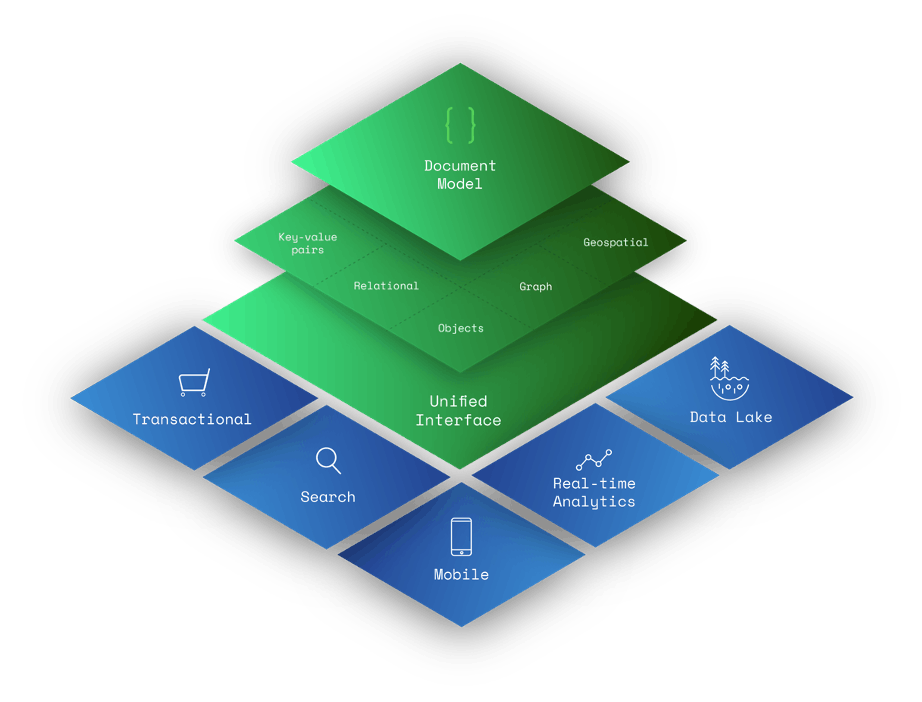 문서 모델은 다른 데이터 모델의 상위 집합입니다
문서 모델은 다른 데이터 모델의 상위 집합입니다
문서 데이터베이스는 풍부한 데이터 모델링 기능 덕분에 다양한 사용 사례에 관한 데이터를 저장할 수 있는 범용 데이터베이스입니다.
관계형 데이터베이스에서 JSON을 사용하지 않는 이유는 무엇인가요?
개발자가 문서 데이터베이스를 활용하여 더 빠르게 빌드할 수 있게 되면서 대다수의 관계형 데이터베이스가 JSON 지원을 지원하게 되었습니다. 그러나 JSON 데이터 유형을 추가하는 것만으로는 JSON을 네이티브로 지원하는 데이터베이스의 이점을 제공할 수 없습니다. 그 이유는 무엇일까요? 관계형 접근 방식은 개발자 생산성을 개선하기 보다는 저하시킬 수 있기 때문입니다. 이는 개발자가 해결해야 하는 문제에 속합니다.
독점 확장 기능
문서 작업을 위해서는 대부분의 개발자가 익숙하지 않으며 자주 사용하는 SQL 도구에서 작동하지 않는 벤더별 맞춤형 SQL 함수를 사용해야 합니다. 저수준 JDBC/ODBC 드라이버와 ORM을 추가하면 개발 프로세스가 복잡해져 생산성이 저하됩니다.
원시 데이터 처리
MongoDB와 같은 네이티브 문서 데이터베이스에서 지원하는 대량 데이터 유형 대신 단순한 문자열과 숫자로 JSON 데이터를 제시하면 데이터 계산, 비교 및 정렬이 복잡하고 오류가 발생하기 쉽습니다.
데이터 품질 저하 및 고정된 테이블
관계형 데이터베이스는 문서의 스키마를 검증할 수 있는 기능이 거의 없으므로 JSON 데이터의 품질을 제어할 수 없습니다. 또한 애플리케이션의 기능이 발전함에 따라 테이블을 변경해야 할 때 발생하는 모든 추가 오버헤드를 고려하여 일반 테이블 형식 데이터를 위한 스키마를 정의해야 합니다.
낮은 성능
대다수의 관계형 데이터베이스는 JSON 데이터 통계를 유지 관리하지 않으므로, 쿼리 플래너가 문서에 대한 쿼리를 최적화할 수 없으며 사용자가 쿼리를 조정할 수 없습니다.
네이티브 확장 없음
전통적인 관계형 데이터베이스는 워크로드 증가에 따라 데이터베이스를 여러 인스턴스로 분할(샤드)하여 확장할 수 있는 방법을 제공하지 않습니다. 대신 애플리케이션 계층에서 직접 샤딩을 구현하거나 비용이 많이 드는 확장 시스템에 의존해야 합니다.
문서 데이터베이스의 장단점은 무엇인가요?
문서 데이터베이스는 다음과 같은 여러 장점이 있습니다.
- 문서 모델은 어디에나 존재하고, 직관적이며 빠른 소프트웨어 개발을 가능하게 합니다.
- 유연한 스키마는 애플리케이션 요구 사항 변화에 따라 데이터 모델을 변경할 수 있도록 합니다.
- 문서 데이터베이스는 개발자가 데이터를 쉽게 상호 작용할 수 있도록 대량 API와 쿼리 언어를 제공합니다.
- 문서 데이터베이스는 분산되어 있어 수평적 확장 및 글로벌 데이터 분산이 가능하며, 탄력적입니다.
이러한 장점으로 인해 문서 데이터베이스는 범용 데이터베이스로서 탁월합니다.
문서 데이터베이스의 일반적 단점으로 알려진 사항은 많은 데이터베이스가 다중 문서 ACID 트랜잭션을 지원하지 않는다는 것입니다. 문서 모델을 활용하는 애플리케이션의 80%-90%는 다중 문서 트랜잭션을 사용할 필요가 없을 것으로 예상됩니다.
일부 문서 데이터베이스는 MongoDB처럼 다중 문서 ACID 트랜잭션을 지원합니다.
ACID 트랜잭션이란?을 방문하여 문서 모델이 다중 문서 트랜잭션의 필요를 대부분 제거하는 방법 및 드물게 필요한 경우 MongoDB가 트랜잭션을 지원하는 방법에 대해 자세히 알아보세요.
문서 데이터베이스의 사용 사례는 무엇이 있나요?
문서 데이터베이스는 트랜잭션 및 분석 애플리케이션을 위한 다양한 사용 사례를 제공하는 범용 데이터베이스입니다.
- 단일 보기 또는 데이터 허브
- 고객 데이터 관리 및 개인화
- 사물인터넷(IoT) 및 Time Series 데이터
- 제품 카탈로그 및 콘텐츠 관리
- 결제 처리
- 모바일 앱
- Mainframe 오프로드
- 운영 분석
- 실시간 분석
사용 사례 안내: MongoDB를 사용해야 하는 경우를 방문하여 상기 애플리케이션에 대해 자세히 알아보세요.
요약
문서 데이터베이스는 직관적이고 유연한 문서 데이터 모델을 사용하여 데이터를 저장합니다. 문서 데이터베이스는 다양한 산업 분야의 여러 사용 사례에 활용할 수 있는 범용 데이터베이스입니다.
MongoDB의 개발자 데이터 플랫폼인 MongoDB Atlas에서 데이터베이스를 생성하여 문서 데이터베이스를 시작하세요. Atlas는 문서 모델을 실험하고 탐색할 수 있는 영구 무료 티어를 제공합니다.
FAQ
문서 데이터베이스는 어떤 용도에 적합한가요?
MongoDB는 문서 데이터베이스인가요?
문서 데이터베이스의 예에는 무엇이 있나요?
문서 데이터베이스는 어떻게 작동하나요?
문서는 데이터베이스에 어떻게 저장되나요?
어떤 필드가 문서에서 항상 첫 번째 필드인가요?
MongoDB에서 모든 문서의 첫 번째 필드는 _id로 명명됩니다. _id 필드는 문서의 고유 식별자로 사용됩니다. 자세한 내용은 공식 MongoDB 문서를 참조하세요..
참고로 각 문서 데이터베이스 관리 시스템은 고유한 필드 요구 사항이 있습니다.
MongoDB 데이터는 어떻게 저장되나요?
MongoDB는 데이터를 BSON (바이너리 JSON) 문서 형식으로 저장합니다.
MongoDB를 무료로 사용할 수 있나요?
네, 두 가지 무료 MongoDB 옵션이 있습니다:
- MongoDB Atlas는 MongoDB의 개발자 데이터 플랫폼으로, 실험 및 MongoDB 사용법 학습에 알맞은 영구 무료 옵션입니다.
- MongoDB를 자체 호스팅하려면 Server Side Public License(SSPL)에 따라 MongoDB Community Server를 사용할 수 있습니다.
문서 데이터베이스 vs. 관계형 데이터베이스
문서 데이터베이스와 관계형 데이터베이스의 가장 분명한 차이점은 데이터가 모델링되는 방식입니다. 문서 데이터베이스는 일반적으로 필드-값 쌍을 가진 유연한 JSON 유사 문서를 사용하여 데이터를 모델링합니다. 관계형 데이터베이스는 일반적으로 고정된 행과 열이 있는 테이블을 사용하여 데이터를 모델링합니다.