MongoDB provides an API for Voyage AI's best-in-class embedding and reranking models. Use Voyage AI models with other parts of your AI stack, including vector databases and large language models (LLMs), to build production-ready applications with accurate AI search and retrieval.
Start Building
Use the following resources to get started:
Create an API key, generate your first embeddings, and build a RAG application.
Learn how to manage your API keys in MongoDB Atlas.
Explore the API specification.
Voyage AI Models
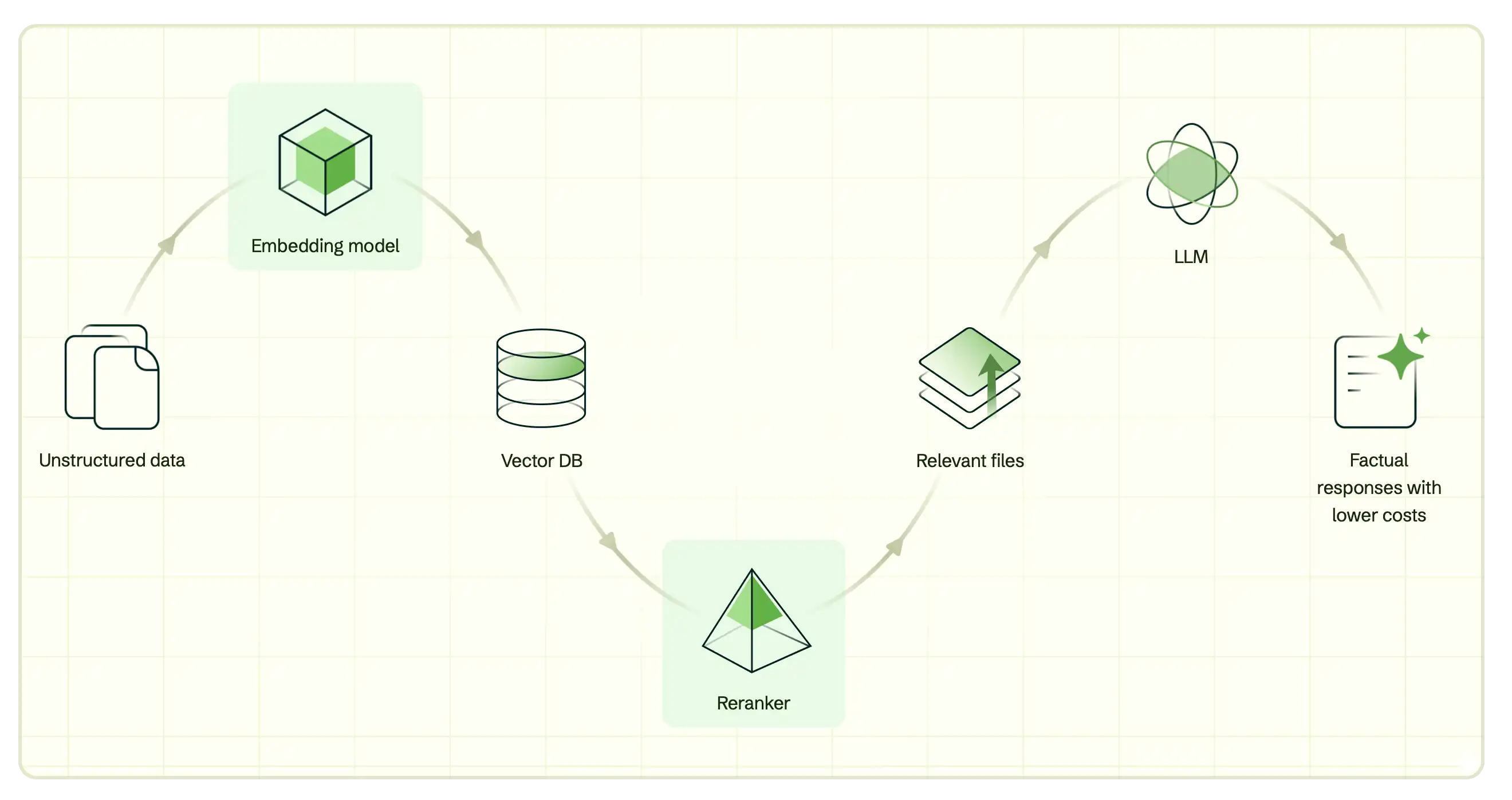
Voyage AI's embedding and reranking models are state-of-the-art in retrieval accuracy. To learn more about the models, see Models Overview.
voyage-4-large
The best general-purpose and multilingual retrieval quality. All 4 series models share the same embedding space.
voyage-context-3
Contextualized chunk embeddings optimized for general-purpose and multilingual retrieval quality.
voyage-multimodal-3.5
Rich multimodal embedding model that can vectorize interleaved text and visual data, such as screenshots of PDFs, slides, tables, figures, videos, and more.
rerank-2.5
Our generalist reranker optimized for quality with instruction-following and multilingual support.
Use Cases
Voyage AI models support the following use cases:
Use semantic search to retrieve contextually relevant information.
Implement RAG to ground LLMs in your data and reduce hallucinations.
Better Together
Leverage Voyage AI with MongoDB Vector Search and AI integrations to streamline your AI application development.
Combine Voyage AI models with MongoDB Vector Search to build production-ready AI applications.
Integrate with LangChain, LlamaIndex, and other popular AI frameworks.
Key Concepts
- embedding model
- Embedding models are algorithms that convert data into vector embeddings that capture your data's semantic, or underlying, meaning. These vectors enable vector search and serve as essential building blocks for retrieval-augmented generation (RAG), the predominant approach for building reliable AI applications.
- reranker
- Rerankers are algorithms that score relevance between a search query and your search results. Rerankers help you refine your initial results by reordering documents based on relevance scores, producing a more accurate subset of results.
- vector embeddings
- A vector embedding is an array of numbers, with each dimension representing a different feature or attribute of your data. Vectors can be used to represent any type of data, from text, images, and video to unstructured data. You create vector embeddings by passing your data through an embedding model, and you can store these embeddings in a database that supports vector embeddings like MongoDB.
- vector search
- Vector search is the search method that powers semantic search and RAG. By measuring the distance between vectors, you can determine semantic similarity between different data points. This allows you to get relevant search results by comparing your vectorized query against your vector embeddings. You can use Voyage AI models with any vector search solution and vector database, but they integrate seamlessly with MongoDB Vector Search and MongoDB Atlas.
- RAG
- Retrieval-augmented generation (RAG) is an architecture used to augment large language models (LLMs) with additional data so that they can generate more accurate responses. To learn more, see RAG with Voyage AI.
- tokens
- In the context of embedding models and LLMs, tokens are the fundamental units of text, such as words, subwords, or characters, that the model processes to create embeddings or generate text. Tokens are how you are billed for usage of embedding models and LLMs.
- rate limits
- Rate limits are restrictions imposed by API providers on the number of requests a user can make within a specific time frame, often measured in tokens per minute (TPM) or requests per minute (RPM). These limits ensure fair usage, prevent abuse, and maintain the stability and performance of the service for all users.