Integrating Relational Migrator with Kafka
On this page
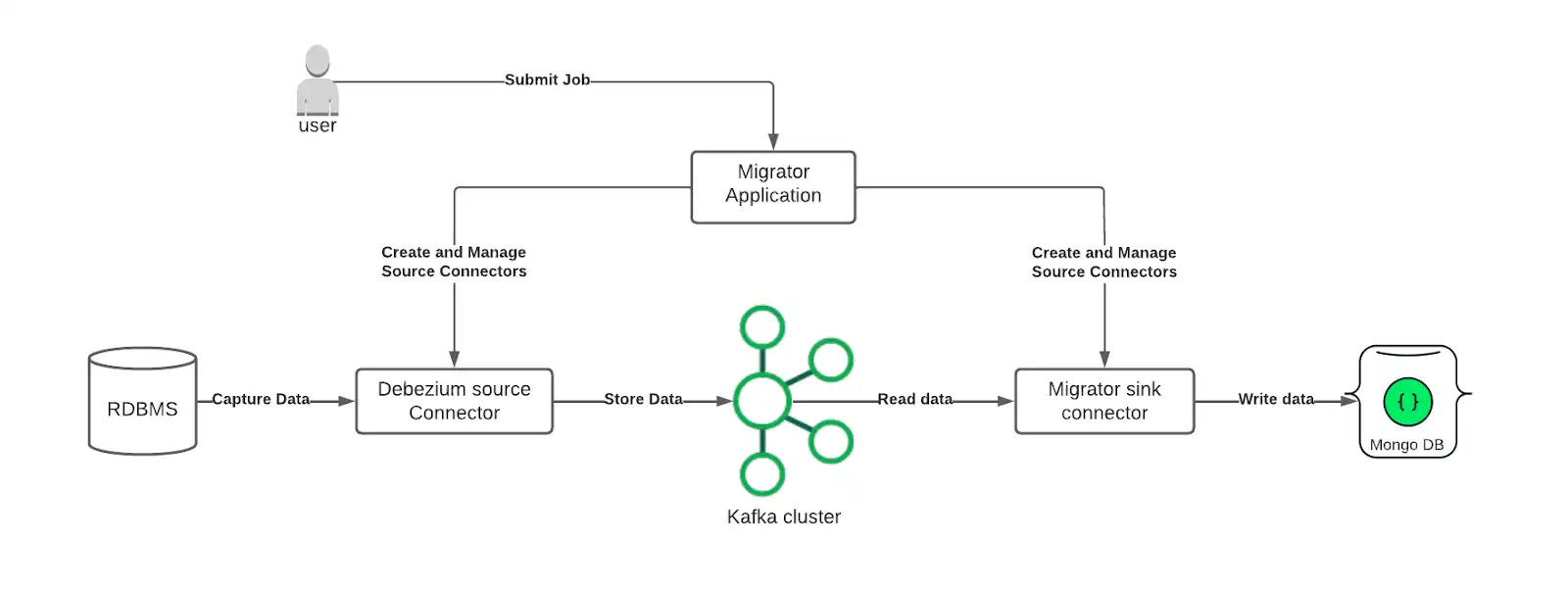
Relational Migrator uses Apache Kafka as a robust transport layer to migrate data from a source relational database to MongoDB. Relational Migrator can be used as a Kafka Connect plugin that improves resilience and scalability of big data migration jobs.
Use Cases
Relational Migrator with Kafka is intended for large and long running jobs. Kafka's built-in resilience ensures the sync job can recover and continue running if any component becomes temporarily unavailable.
Behavior
Relational Migrator works with Kafka as a Kafka Connect sink connector. A Debezium connector captures data events from your source database, while Relational Migrator interprets and transforms events from the Debezium source and sends them to a MongoDB cluster that acts as a data sink.
Architecturally, Relational Migrator is deployed within Kafka as a Kafka Connect sink connector. Database events are captured using the open-source Debezium tool for database change data capture. A Debezium Connector captures these events from your source database.

Tasks
You can use the following deployment methods to install Relational Migrator with Kafka:
Deployment Method | Description |
|---|---|
This deployment method is ideal if you are already running Kafka or
have your own approach to installing and configuring Kafka. | |
This deployment method is ideal for educational purposes. Use this if you
are looking to learn and understand how to configure your own multi-server Kafka
environment. | |
This deployment method is ideal if you want the reliability of Kafka without
having to manage your own cluster. |