The Performance Advisor orders the indexes that it suggests by their respective Impact. Impact indicates the estimated performance improvement that the suggested index would bring.
How Performance Advisor Suggests and Ranks Indexes
The Performance Advisor monitors queries that take longer than 100 milliseconds to
execute and groups these queries into common query shapes. The Performance Advisor calculates the inefficiency of each query shape by
considering the following aggregated metrics from queries which match
the shape:
Amount of time spent executing the query.
Number of documents scanned.
Number of documents returned.
Average object size.
To establish recommended indexes, the Performance Advisor uses these metrics in a formula to calculate the Impact, or performance improvement that creating an index matching that query shape would cause. When the Performance Advisor suggests indexes, it ranks the indexes by their Impact. The Impact indicates High or Medium based on the total wasted bytes read.
Index Field Order
The type of query operation in the query shape affects the order of the fields used to construct the index. In general, the Performance Advisor ranks fields by their cardinality.
The following table shows how the Performance Advisor ranks various operation types by order of relative importance:
Limiting Proposed Indexes
The Performance Advisor doesn't suggest indexes that have more than 16 fields.
Also, the Performance Advisor suggests the index only if the difference between scanned documents and returned documents is greater than 500 for impacted queries.
Index De-Duplication
The Performance Advisor de-duplicates overlapping indexes before it makes suggestions. For example, consider if the Performance Advisor calculates the following potential suggested indexes:
{ a : 1 } { a : 1, b : 1 }
Since { a : 1 } is a prefix of { a : 1, b : 1 }, Performance Advisor
suggests only { a : 1, b : 1 }. To learn more about index prefixes,
see Prefixes.
Example: New York City Taxi Data
This example uses a database named cab-db that contains information
about New York City taxi rides, with fields for the times of pickup and
dropoff, ride distance, and a breakdown of ride costs. A typical
document in the collection yellow looks like the following example:
{ "_id" : ObjectId("5db9daab0b2a17b7706cd6a3"), "pickup_datetime" : "2014-06-30 02:09:23", "dropoff_datetime" : "2014-06-30 02:20:36", "passenger_count" : 2, "trip_distance" : 3, "fare_amount" : 12, "tip_amount" : 2.6, "total_amount" : 15.6 }
The collection contains more than 10 million documents, so an application that needs to run queries based on specific field data will generate some very inefficient operations unless you properly index the collection.
Typical queries for this application search for documents that contain a specific dropoff time, combined with one or more other fields. For example:
db.yellow.find({ "dropoff_datetime": "2014-06-19 21:45:00", "passenger_count": 1, "trip_distance": {"$gt": 3 } })
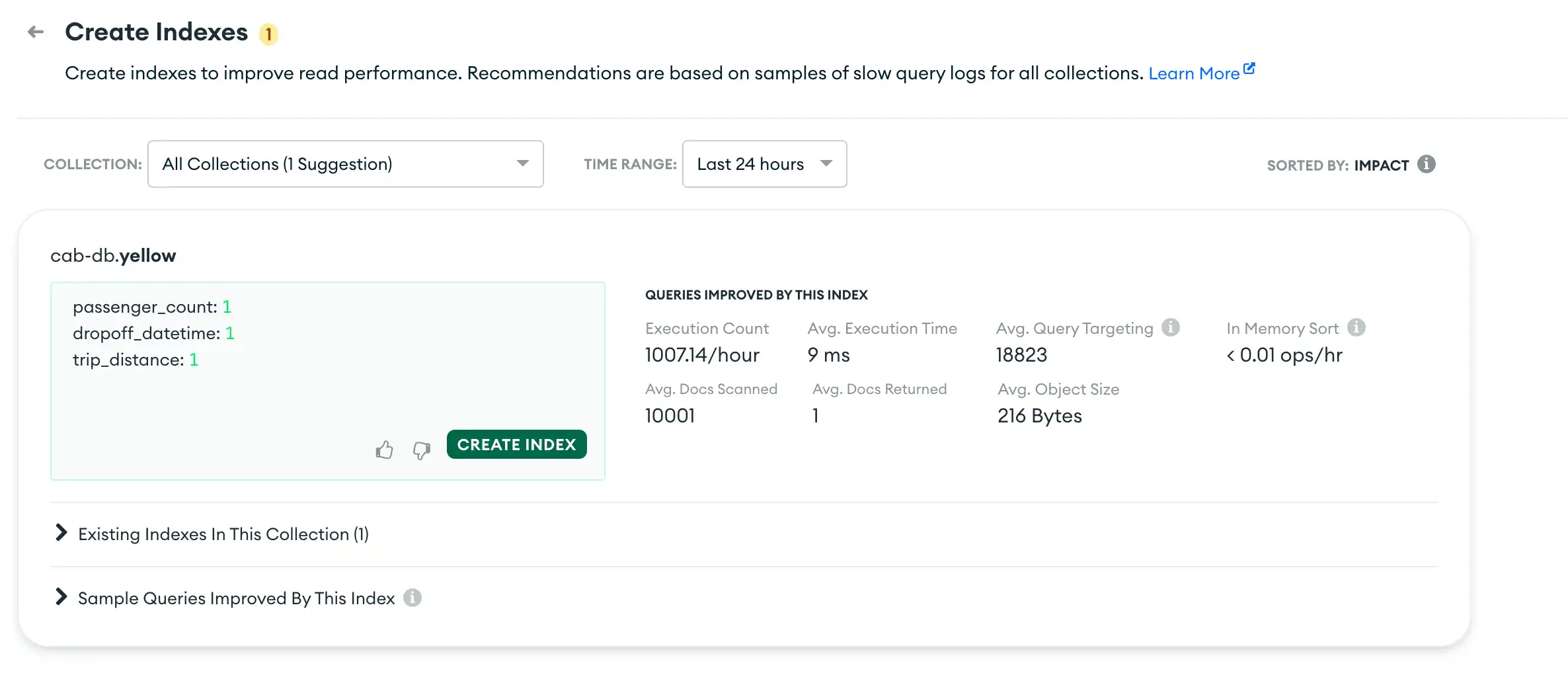
The Performance Advisor recommends the following indexes to improve performance:

Note
By default, the Performance Advisor shows index recommendations for all collections in your cluster. To narrow the recommendations down to a specific collection, select one from the Collection dropdown menu.
The Performance Advisor lists recommended indexes in order of performance impact, from greatest to least.
The first recommendation is for an index on three fields:
passenger_countdropoff_datetimetrip_distance
Click the Create Index button to create the index with any desired additional options. To learn more about creating an index in the Performance Advisor, see Create Suggested Indexes.
If you create this index, you remove the need for the database engine to scan the entire collection to find documents that match the query, which improves performance. Queries with the shape shown in the example return results in 50 milliseconds or less on the indexed collection, as opposed to several seconds on the unindexed collection.
Note
You can also create indexes with the Data Explorer.