The Data Explorer provides an aggregation pipeline builder to process your data. Aggregation pipelines transform your documents into aggregated results based on selected pipeline stages.
The MongoDB Atlas aggregation pipeline builder is primarily designed for building pipelines, rather than executing them. The pipeline builder provides an easy way to export your pipeline to execute in a driver.
Access Data
To interact with your data in the Cloud Manager UI:
In MongoDB Cloud Manager, go to the Processes page for your project.
If it's not already displayed, select the organization that contains your desired project from the Organizations menu in the navigation bar.
If it's not already displayed, select your desired project from the Projects menu in the navigation bar.
In the sidebar, click Processes under the Database heading.
The Processes page displays.
Required Roles
To create and execute aggregation pipelines in the
Data Explorer, you must have been granted at least the
Project Data Access Read Only role.
To utilize the $out stage in your pipeline, you must
have been granted at least the
Project Data Access Read/Write role.
Access the Aggregation Pipeline Builder


Create an Aggregation Pipeline


Fill in your aggregation stage.
Fill in your stage with the appropriate values. If Comment Mode is enabled, the pipeline builder provides syntactic guidelines for your selected stage.
As you modify your stage, the Data Explorer updates the preview documents on the right based on the results of the current stage.

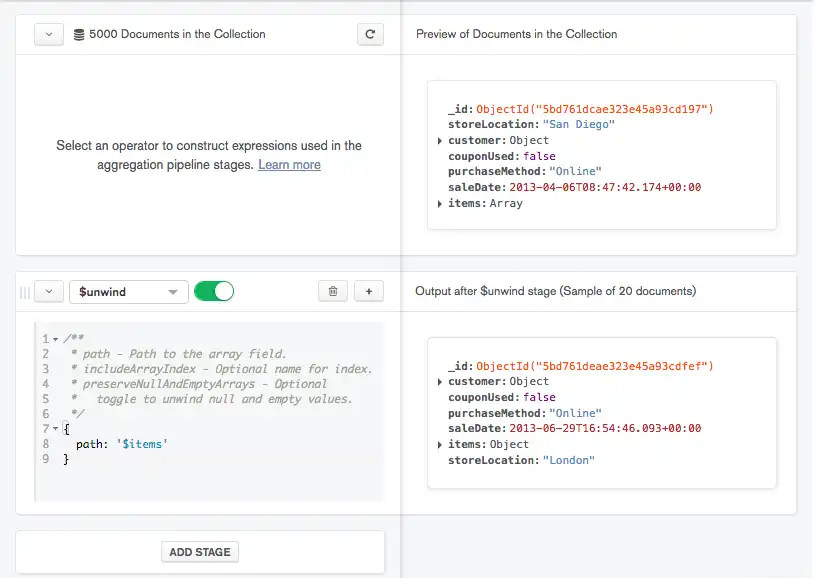
Add additional stages to your pipeline as desired.
There are two ways to add additional stages to your pipeline:
Click the Add Stage button at the bottom of the pipeline to add a new stage at the end of your pipeline:
Click the button on a stage to add a new stage directly after the stage where the button was clicked.

To delete a pipeline stage, click the icon on the desired stage.
Collation
Use collation to specify language-specific rules for string comparison, such as rules for lettercase and accent marks.
To specify a collation document, click Collation at the top of the pipeline builder.
A collation document has the following fields:
{ locale: <string>, caseLevel: <boolean>, caseFirst: <string>, strength: <int>, numericOrdering: <boolean>, alternate: <string>, maxVariable: <string>, backwards: <boolean> }
The locale field is mandatory; all other collation fields are
optional. For descriptions of the fields, see
Collation Document.
Import an Aggregation Pipeline from Text
You can import aggregation pipelines from plain text into the pipeline builder to easily modify and verify your pipelines.
To import a pipeline from plain text:


Type or paste your pipeline in the dialog.
Your pipeline must match the syntax of the pipeline parameter of
the db.collection.aggregate()
method.
Reset Your Pipeline
To return your pipeline to the initial blank state, click the plus icon at the top of the pipeline builder.
Export an Aggregation Pipeline to a Client Library Language
You can use the aggregation pipeline builder to export your finished pipeline to one of the supported client library languages; Java, Node, C#, and Python 3. Use this feature to format and export pipelines for use in your applications.
To export your aggregation pipeline:
Construct an aggregation pipeline.
For instructions on creating an aggregation pipeline, see Create an Aggregation Pipeline.
Select your desired export language.
In the Export Pipeline To dropdown, select your desired language.
The My Pipeline pane on the left displays your
pipeline in mongosh syntax.
The pane on the right displays your pipeline in the selected language.
Aggregation Pipeline Settings
To modify the aggregation pipeline builder settings:


Modify pipeline settings as desired.
You can modify the following settings:
Setting | Description | Default |
|---|---|---|
Comment Mode | When enabled, the Data Explorer adds helper comments to each stage. Changing this setting only affects new stages and does not modify stages which have already been added to your pipeline. | On |
Number of Preview Documents | Number of documents to show in the preview for each stage. | 20 |