Using the Confluent Cloud With Atlas Stream Processing






Rate this tutorial


Apache Kafka is a massively popular streaming platform today. It is available in the open-source community and also as software (e.g., Confluent Platform) for self-managing. Plus, you can get a hosted Kafka (or Kafka-compatible) service from a number of providers, including AWS Managed Streaming for Apache Kafka (MSK), RedPanda Cloud, and Confluent Cloud, to name a few.
In this tutorial, we will configure network connectivity between MongoDB Atlas Stream Processing instances and a topic within the Confluent Cloud. By the end of this tutorial, you will be able to process stream events from Confluent Cloud topics and emit the results back into a Confluent Cloud topic.
Confluent Cloud dedicated clusters support connectivity through secure public internet endpoints with their Basic and Standard clusters. Private network connectivity options such as Private Link connections, VPC/VNet peering, and AWS Transit Gateway are available in the Enterprise and Dedicated cluster tiers.
Note: At the time of this writing, Atlas Stream Processing only supports internet-facing Basic and Standard Confluent Cloud clusters. This post will be updated to accommodate Enterprise and Dedicated clusters when support is provided for private networks.
The easiest way to get started with connectivity between Confluent Cloud and MongoDB Atlas is by using public internet endpoints. Public internet connectivity is the only option for Basic and Standard Confluent clusters. Rest assured that Confluent Cloud clusters with internet endpoints are protected by a proxy layer that prevents types of DoS, DDoS, SYN flooding, and other network-level attacks. We will also use authentication API keys with the SASL_SSL authentication method for secure credential exchange.
In this tutorial, we will set up and configure Confluent Cloud and MongoDB Atlas for network connectivity and then work through a simple example that uses a sample data generator to stream data between MongoDB Atlas and Confluent Cloud.
This is what you’ll need to follow along:
- An Atlas project (free or paid tier)
- For the purposes of this tutorial, we’ll have the user “tutorialuser.”
- MongoDB shell (Mongosh) version 2.0+
- Confluent Cloud cluster (any configuration)
For this tutorial, you need a Confluent Cloud cluster created with a topic, “solardata,” and an API access key created. If you already have this, you may skip to Step 2.
To create a Confluent Cloud cluster, log into the Confluent Cloud portal, select or create an environment for your cluster, and then click the “Add Cluster” button.
In this tutorial, we can use a Basic cluster type.

Once your cluster is created, create an API key by clicking on the “API Keys” menu under the Cluster Overview on the left side of the page.

Click on “Create Key” and provide a description for your key pair as shown below.
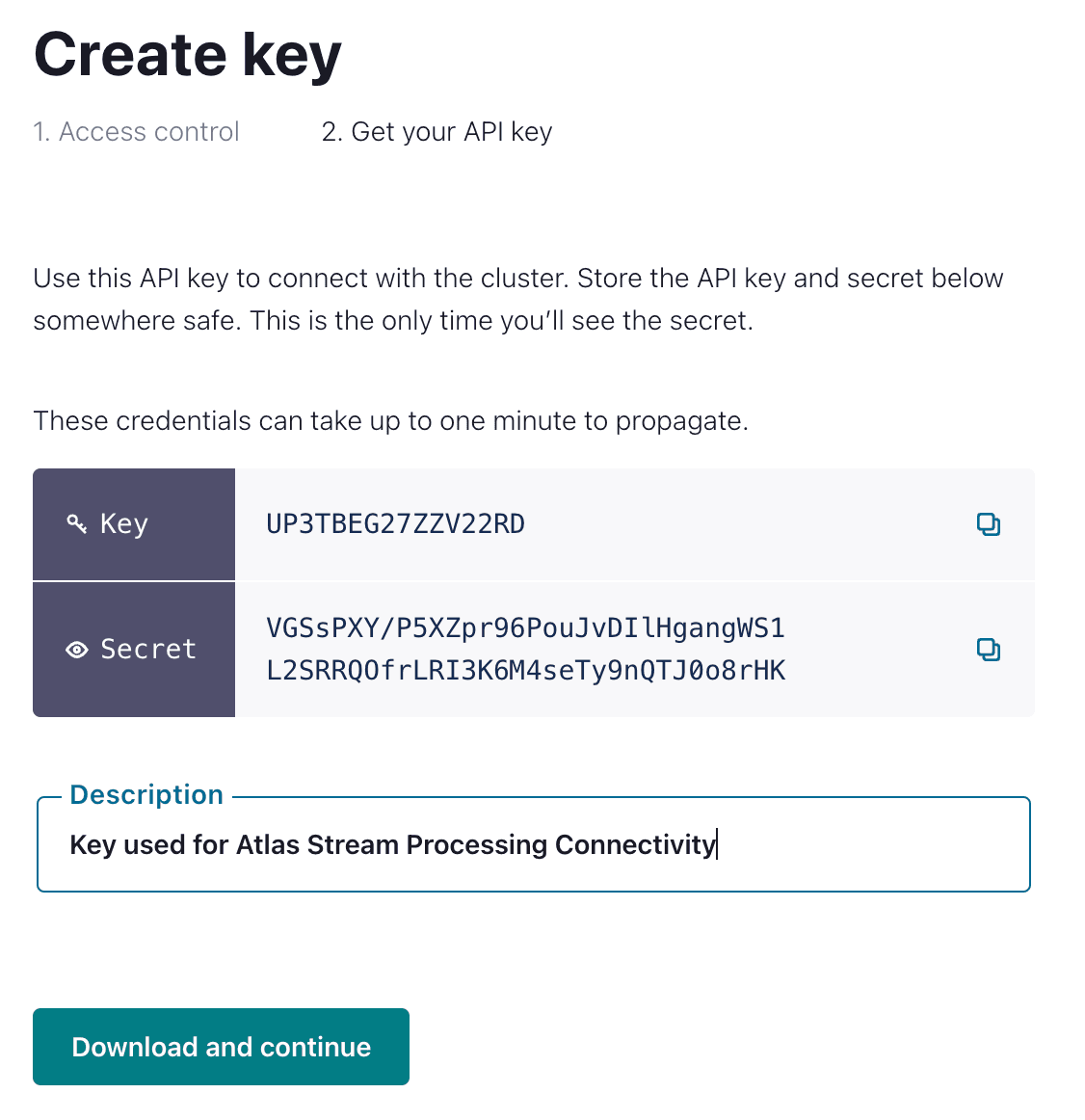
Make a note of the API key and password before you download and continue. You will need these when creating the connection in Atlas Stream Processing. Note that Confluent OAuth and Confluent Single Sign-on are not supported as authentication methods in Atlas Stream Processing.
Next, create a topic by clicking on the “Topics” menu item and then the “Add topic” button. Accept the default settings and give the topic a name: “solardata.” We are now ready to configure MongoDB Atlas Stream Processing.
In MongoDB Atlas, click on “Stream Processing” from the Services menu. Next, click on the “Create Instance” button. Provide a name, cloud provider, and region. Note: For a lower network cost, choose the cloud provider and region that matches your Confluent Cloud cluster. In this tutorial, we will use AWS us-east-1 for both Confluent Cloud and MongoDB Atlas.
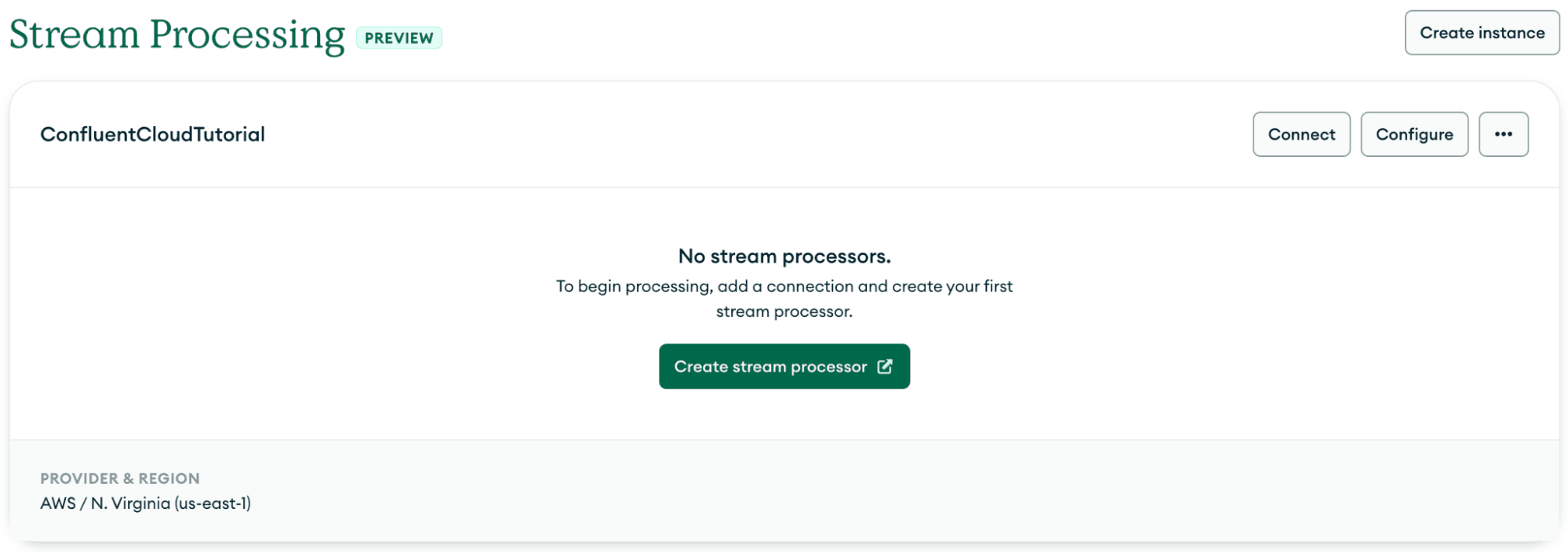
Once the Stream Processing Instance (SPI) is created, we can create our connection to the Confluent Cloud using the Connection Registry. Click on “Configure,” and then click on the “Connection Registry” tab as shown below.

To create the connection to the Confluent Cloud, click on “Add Connection.”
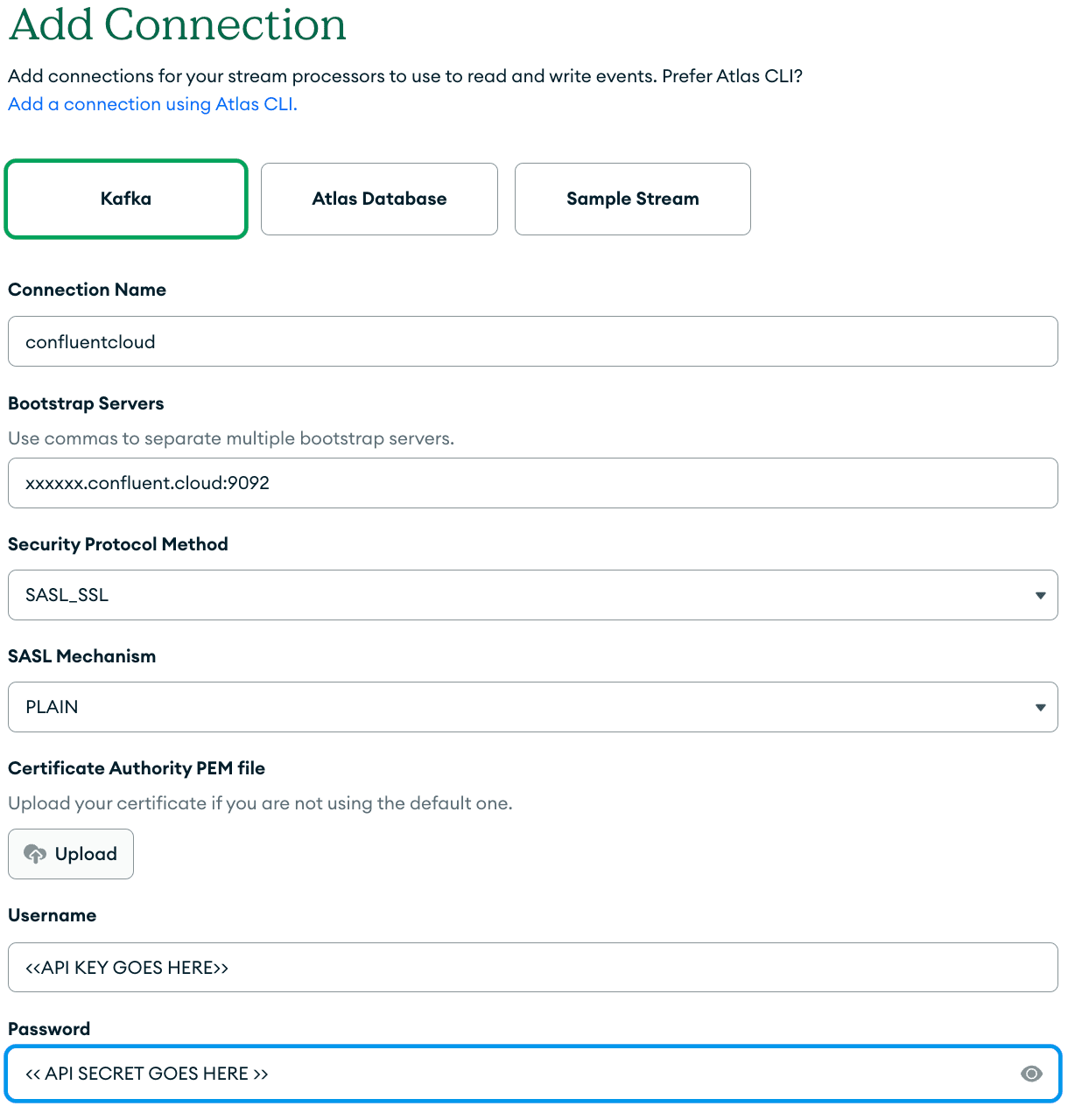
Select, “Kafka” and enter “confluentcloud” for the connection name. Fill out the following details from the information in your Confluent Cloud cluster.
- Bootstrap server: Provided in Confluent Cloud under Cluster Settings/Endpoints
- Security Protocol: SASL_SSL
- SASL Mechanism: PLAIN
- Username: Paste in the API KEY
- Password: Paste in the API SECRET
An example of add connection dialog is shown below.
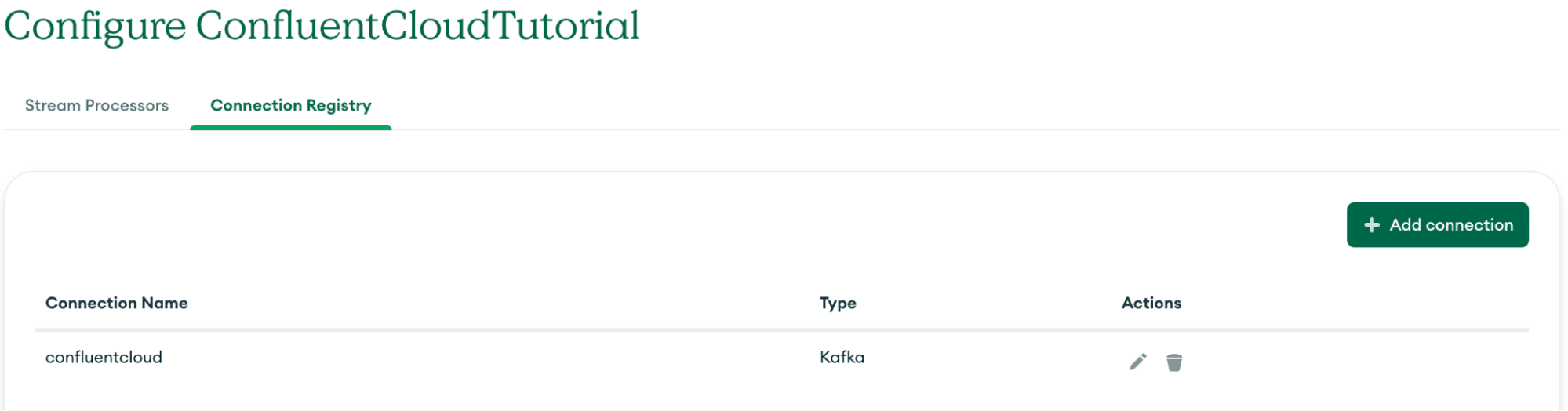
Click on “Add Connection” and your new connection to the Confluent Cloud will show up in the list.
Next, create another connection by clicking on the “Add Connection” button. This time, we will select “Sample Stream” and “sample_stream_solar” in the drop-down as shown below.
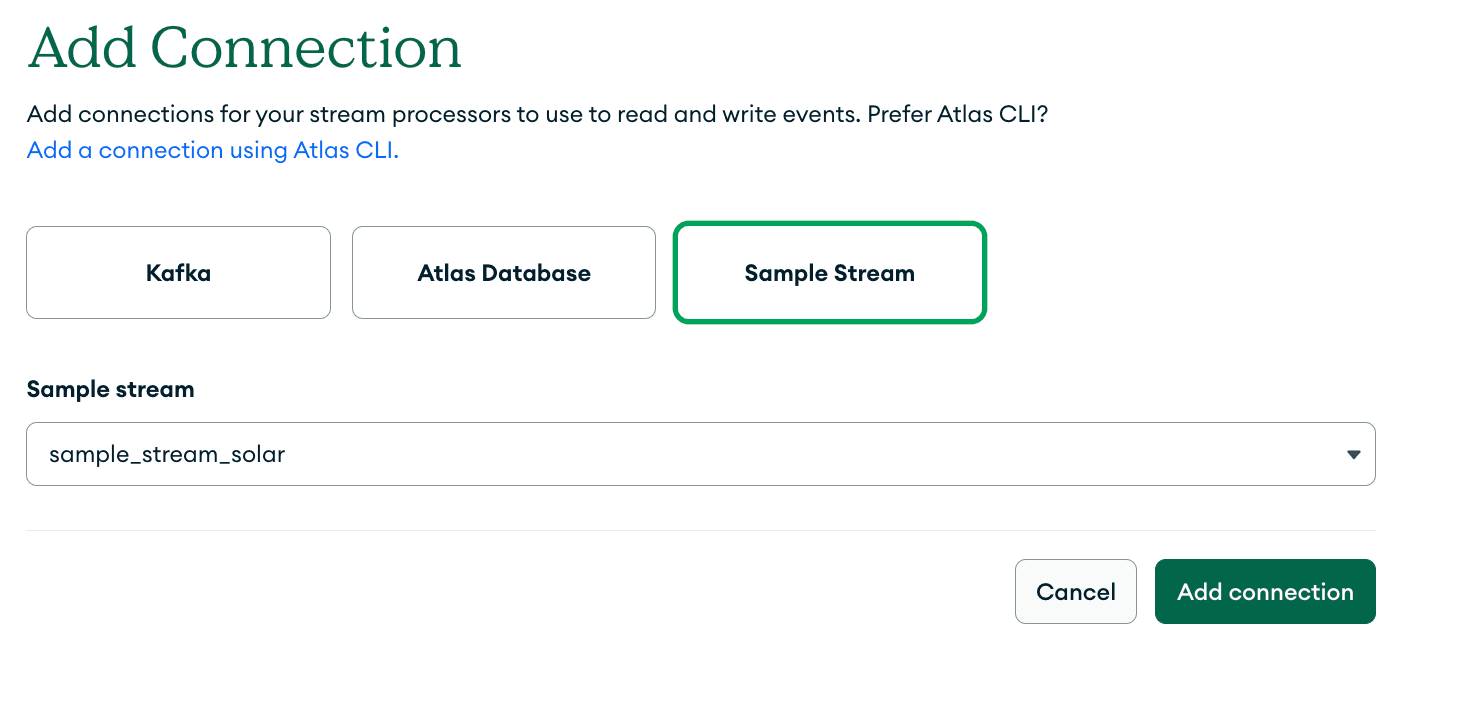
This will make a sample data generator called “sample_stream_solar” available in our SPI.
Next, let’s test the connectivity to Confluent and run our first Atlas Stream Processor with data from Confluent Cloud.
Note: To connect to the SPI, you will need a database user with Atlas Admin permissions or a member of the Project Owner role. If you do not already have this, create it now before continuing this tutorial.
Connection information can be found by clicking on the “Connect” button on your SPI. The connect dialog is similar to the connect dialog when connecting to an Atlas cluster. To connect to the SPI, you will need to use the mongosh command line tool.
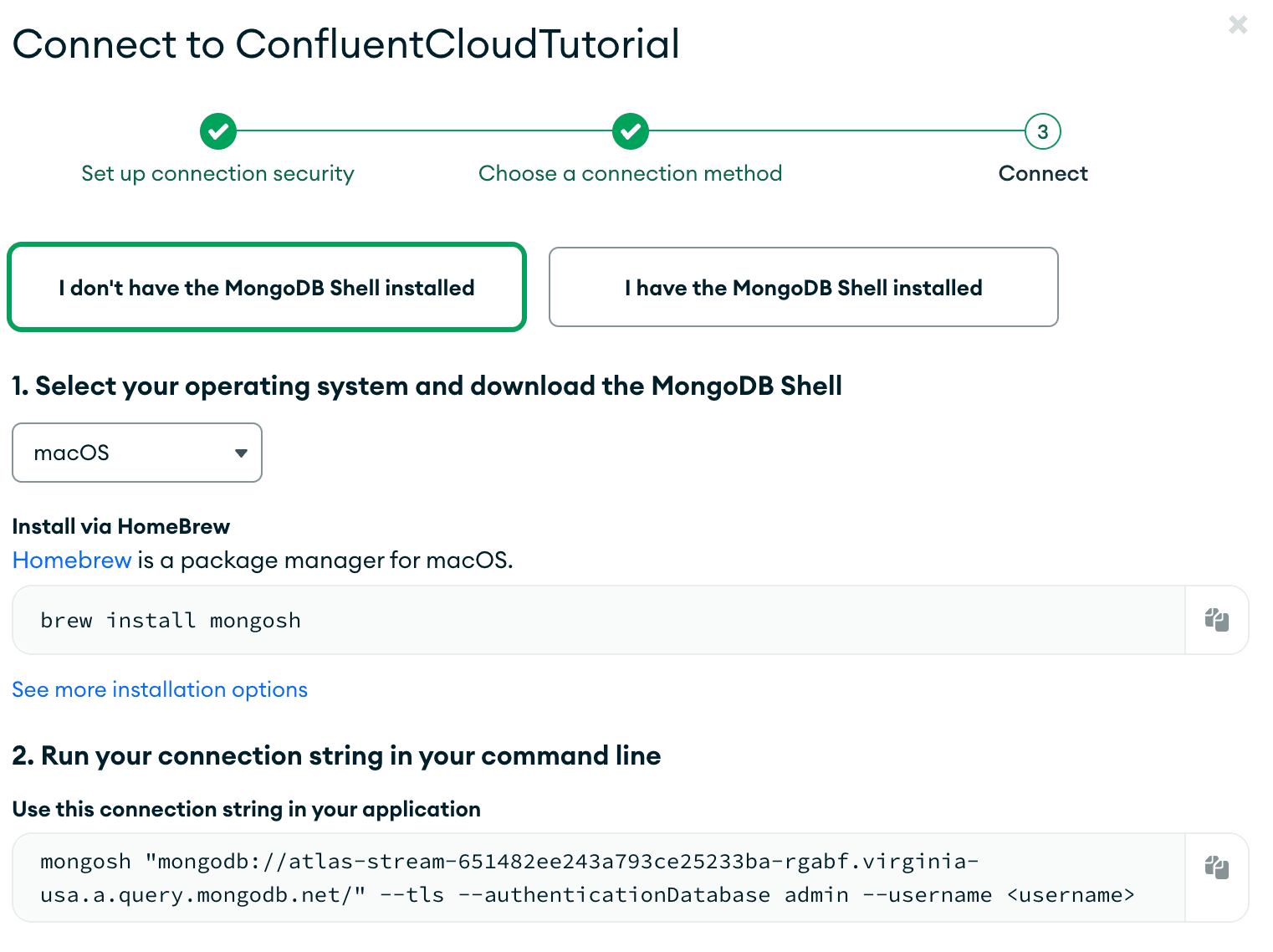
To connect to the SPI, use the connection string provided in the connect dialog.
Once connected, you can enumerate the available connections using the
sp.listConnections() command.1 AtlasStreamProcessing> sp.listConnections() 2 [ 3 { name: 'sample_stream_solar', type: 'inmemory' }, 4 { name: 'confluentcloud', type: 'kafka' } 5 ]
Now that we have confirmed both our ‘sample_stream_solar’ sample data and our ‘confluentcloud’ Kafka topic are available, let’s use the solar sample source to create a streaming query that calculates the average power output and writes this to a Kafka topic “solardata”.
1 s_solar={$source: { connectionName: "sample_stream_solar"}} 2 3 Twindow = { $tumblingWindow: { interval: { size: NumberInt(30), unit: "second" }, pipeline: [ { $group: { _id: "$device_id", max: { $max: "$obs.watts" }, avg: { $avg: "$obs.watts" } } }] } } 4 5 write_kafka={ $emit: { "connectionName": "confluentcloud", "topic" : "solardata"}}
Now that we have our pipeline variables defined, let’s use the
.process to run this stream processor in the foreground.1 AtlasStreamProcessing> sp.process([s_solar,Twindow,write_kafka])
To read the topic data, open another terminal window and connect to the SPI. Define a variable for the Kafka topic as shown below.
1 s_kafka={$source: { connectionName: "confluentcloud", "topic": "solardata"}}
Next, use the
.process() command to read the data from the ‘solardata’ topic.1 AtlasStreamProcessing> sp.process([s_solar])
After about 30 seconds, you will see data output from the ‘solardata’ topic.
In this tutorial, we used Atlas Stream Processing to create a stream processor with sample data and wrote the aggregation results to a Kafka topic in Confluent Cloud. We also streamed data from Confluent Cloud into Atlas Stream Processing and confirmed that the transformed data was written to the topic. This tutorial was done without any extra network configuration.
You might recall that by default, no network connections are allowed into Atlas. Users need to either open their cluster to the world via adding 0.0.0.0 or specify specific IP ranges. What is important to note is connections from Atlas Stream Processing originate within Atlas and connect out to the Confluent Cloud. Thus, there is no network access IP that needs to be opened or IP allowlisted.
In Confluent Cloud, there is no concept of IP filtering or IP allowlisting. For this reason, there is nothing extra to perform on the Confluent Cloud side with respect to networking configuration. At the time of this writing, September 2023, private networking options available in Confluent Cloud such as PrivateLink are not supported in Atlas Stream Processing. This tutorial will be updated when these private networking options are supported.
Log in today to get started. Atlas Stream Processing is now available to all developers in Atlas. Give it a try today!