Accelerate Your AI journey: Simplify Gen AI RAG With MongoDB Atlas & Google’s Vertex AI Reasoning Engine







Rate this tutorial


Imagine a world of data-driven applications, demanding flexibility and power. This is where MongoDB thrives, with features perfectly aligned with these modern needs. But data alone isn't enough. Applications need intelligence too. Enter generative AI (gen AI), a powerful tool for content creation. But what if gen AI could do even more?
This is where AI agents come in. Acting as the mastermind behind gen AI, they orchestrate tasks, learn continuously, and make decisions. With agents, gen AI transforms into a versatile tool, automating tasks, personalizing interactions, and constantly improving. But how do we unleash this full potential?
Here's where the Vertex AI Reasoning Engine steps in. Reasoning Engine (LangChain on Vertex AI) is a managed service that helps you to build and deploy an agent reasoning framework. It is a platform specifically designed for intelligent gen AI applications. Reasoning Engine is a Vertex AI service that has all the benefits of Vertex AI integration: security, privacy, observability, and scalability. Easily deploy and scale your application from development to production with a straightforward API, minimizing time-to-market. As a managed service, Reasoning Engine empowers you to build and deploy agent reasoning framework. It offers flexibility in how much reasoning you delegate to the large language model (LLM) and how much you control with custom code.
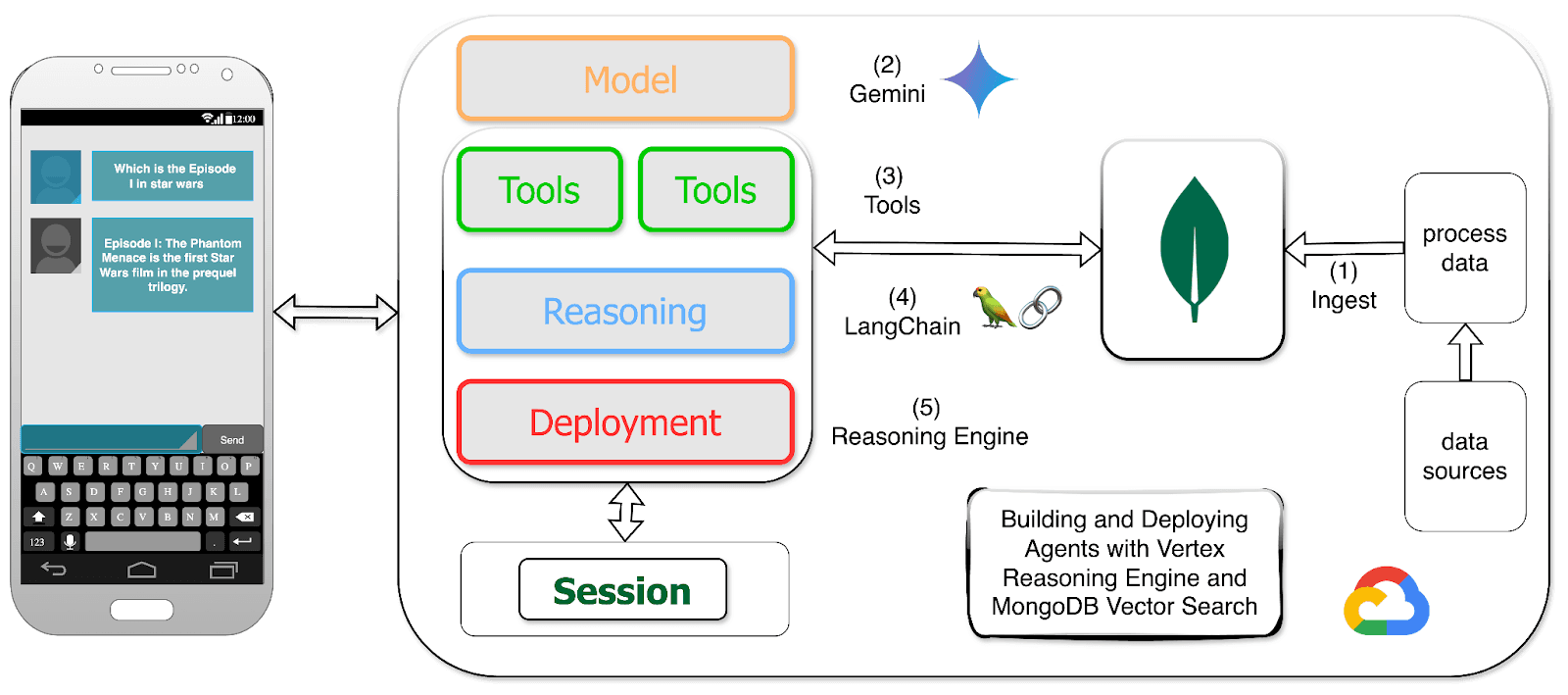
Figure 1 : How it works: MongoDB as vector store for Google Reasoning engine
Lets see how MongoDB Atlas and Vertex AI Reasoning Engine can help you build and deploy a new generation of intelligent applications using LangChain on Vertex AI by combining data, automation, and machine learning. Here's a breakdown of the benefits: \
- Powerful and flexible data management with MongoDB: MongoDB's features like data store and vector store are suited for modern data-driven applications that require flexibility and scalability.
- Enhanced applications with generative AI: Generative AI can create content, potentially saving time and resources.
- Intelligent workflows with AI agents: AI agents can manage and automate tasks behind the scenes, improving efficiency. They can learn from data and experience, constantly improving the application's performance. Agents can analyze data and make decisions, potentially leading to more intelligent application behavior.
This solution is beneficial for various industries and applications, such as customer service chatbots that can learn and personalize interactions, or e-commerce platforms that can automate product recommendations based on customer data. Let's have a deep dive into the setup.
In this post, we will cover how to build a retrieval-augmented generation (RAG) application using MongoDB and Vertex AI and deploy it on Reasoning Engine. Firstly, we will ingest data into MongoDB Atlas and create embeddings for the RAG solution. We will also cover how to use agents to call different tools in return, querying different collections on MongoDB based on the context of the natural language query from the user.
MongoDB Atlas simplifies the process by storing your complex data (like protein sequences or user profiles and so on) alongside their corresponding vector embeddings. This allows you to leverage vector search to efficiently find similar data points, uncovering hidden patterns and relationships. Furthermore, MongoDB Atlas facilitates data exploration by enabling you to group similar data together based on their vector representations.
LangChain is an open-source toolkit that helps developers build with LLMs. Like Lego for AI, it offers pre-built components to connect the models with your data and tasks. This simplifies building creative AI applications that answer questions, generate text formats, and more.
To begin with the setup, the first step is to create a MongoDB Atlas cluster on Google Cloud. Configure IP access list entries and a database user for accessing the cluster using the connection string. We will use Google Colab to ingest, build, and deploy the RAG.
LangChain streamlines text embedding generation with pre-built models like text-embedding and textembedding-gecko. These models convert your text data into vector representations, capturing semantic meaning in a high-dimensional space. This facilitates efficient information retrieval and comparison within LangChain's reasoning workflows. We are using Google's text-embedding-004 model to convert the input data into embeddings on 768 dimensions.
1 def get_text_embeddings(chunks): 2 from vertexai.language_models import TextEmbeddingModel 3 model = TextEmbeddingModel.from_pretrained("text-embedding-004") 4 inputs = chunks[0] 5 embeddings = model.get_embeddings(chunks) 6 return [embedding.values for embedding in embeddings]
The generated embeddings are stored in MongoDB Atlas alongside the actual data. Before executing the write_to_mongoDB function, update the URI to connect to your MongoDB cluster. Pass the db_name and coll_name for the function where you want to store the embeddings.
1 def write_to_mongoDB(embeddings, chunks, db_name, coll_name): 2 from pymongo import MongoClient 3 client = MongoClient("URI", tlsCAFile=certifi.where()) 4 db = client[db_name] 5 collection = db[coll_name] 6 7 for i in range(len(chunks)): 8 collection.insert_one({ 9 "chunk": chunks[i], 10 "embedding": embeddings[i] 11 })
The first step in building your Reasoning Engine agent is specifying the generative AI model. Here, we're using the latest "gemini-1.5-pro" LLM, which will form the foundation of the RAG component.
1 model = "gemini-1.5-pro-001"
LangChain acts as the bridge between your generative model and MongoDB Atlas, allowing it to query vectors. It takes a "query" as input, transforms it into embeddings using Google's embedding models, and retrieves the most semantically near data from MongoDB Atlas. Below is the script for a tool that generates vectors for the query string, performs vector search on MongoDB Atlas, and returns the relevant document to the LLM. Update the function name database and collection name to read from different collections. We can initialize multiple tools and pass to the agent in the next step.
1 def star_wars_query_tool( 2 query: str) : 3 """ 4 Retrieves vectors from a MongoDB database and uses them to answer a question related to Star wars. 5 6 Args: 7 query: The question to be answered about star wars. 8 9 Returns: 10 A dictionary containing the response to the question. 11 """ 12 from langchain.chains import ConversationalRetrievalChain, RetrievalQA 13 from langchain_mongodb import MongoDBAtlasVectorSearch 14 from langchain_google_vertexai import VertexAIEmbeddings, ChatVertexAI 15 from langchain.memory import ConversationBufferMemory, ConversationBufferWindowMemory 16 from pymongo import MongoClient 17 18 from langchain.prompts import PromptTemplate 19 20 21 prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Do not return any answers from your own knowledge. 22 23 {context} 24 Question: {question} 25 """ 26 # create prompt for LLM 27 PROMPT = PromptTemplate( 28 template=prompt_template, input_variables=["context", "question"] 29 ) 30 31 # Add your connection string in srv format below in place of URI 32 client = MongoClient("URI") 33 db = client["embeddings"] 34 35 embeddings =VertexAIEmbeddings(model_name="text-embedding-004") 36 37 # initilize the vector store 38 vs = MongoDBAtlasVectorSearch( 39 collection=db["sample_starwars_embeddings"], 40 embedding=embeddings, 41 index_name="vector_index", 42 embedding_key="embedding", 43 text_key="chunk", 44 ) 45 46 # initilize LLM 47 llm = ChatVertexAI( 48 model_name="gemini-1.5-pro", 49 convert_system_message_to_human=True, 50 max_output_tokens=1000, 51 ) 52 53 # initilize retriver for the vector store object created 54 retriever = vs.as_retriever( 55 search_type="mmr", search_kwargs={"k": 10, "lambda_mult": 0.25} 56 ) 57 memory = ConversationBufferWindowMemory( 58 memory_key="chat_history", k=5, return_messages=True 59 ) 60 61 # initilize the conversation chain 62 conversation_chain = ConversationalRetrievalChain.from_llm( 63 llm=llm, 64 retriever=retriever, 65 memory=memory, 66 combine_docs_chain_kwargs={"prompt": PROMPT}, 67 ) 68 69 # query and get the response from conversation chain 70 response = conversation_chain({"question": query}) 71 72 return response
Vertex AI's Reasoning Engine agent goes beyond just decision-making tools, transforming LangChain agents into versatile AI assistants that can handle data, connect to systems, and make complex decisions, all while understanding and responding to text. This will let you tailor them to specific tasks like choosing the right tool for the job. Teaming up powerful language models like Gemini with reasoning agents enhances their skills by enabling them to understand and generate natural language, making them communication- and information-processing masters — a valuable addition to their toolkit.
By incorporating a reasoning layer, your agent leverages the provided tools to guide the end user toward achieving their ultimate objective. You can define multiple tools at the same time and the LLM will find out which tool to use based on the relevance to the question being asked and the description provided in the tool itself. We are using the default LangchainAgent class that can be further customized based on your requirements.
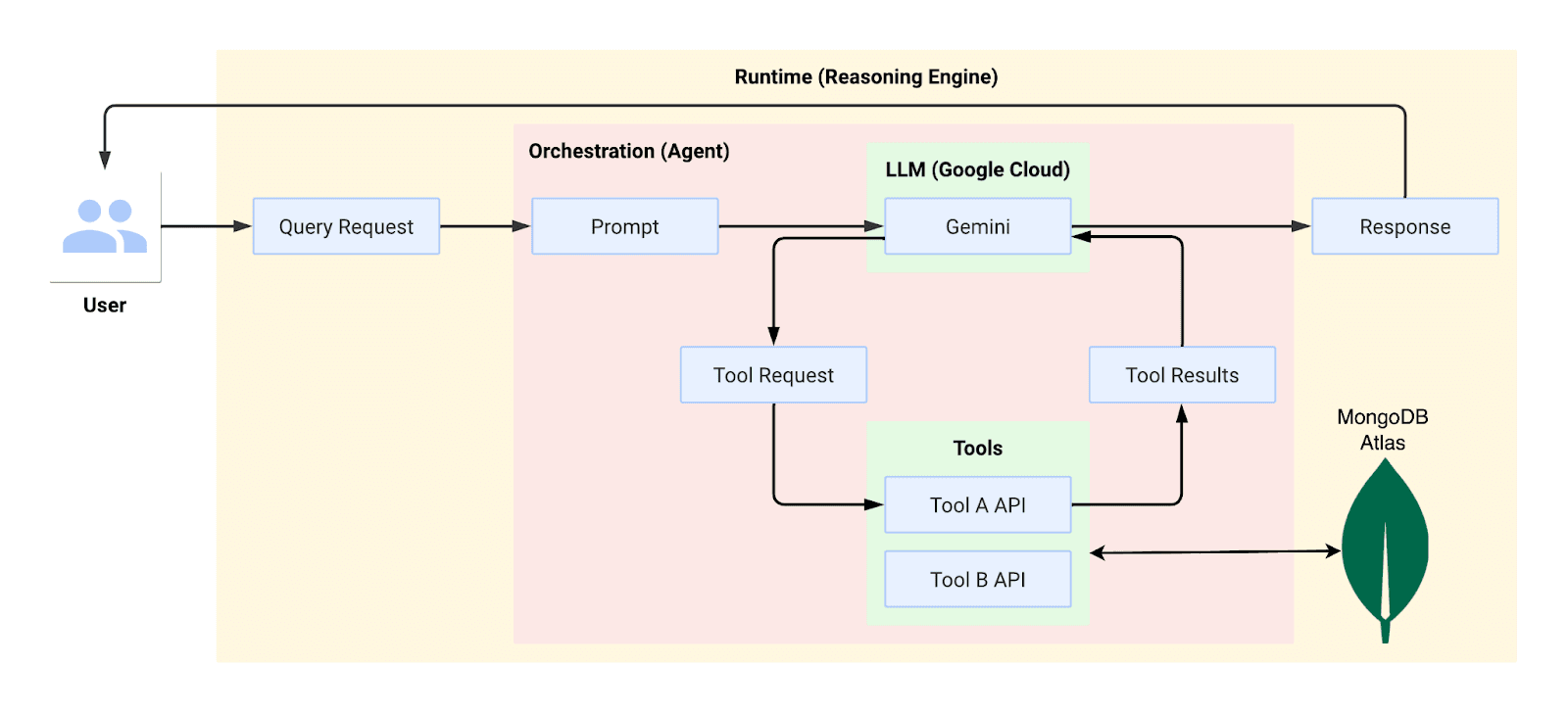
Figure 2: Workflow for the above use case we discussed from end to end
With the below code, we will initialize the agent for tools to perform vector search on MongoDB collections. The star_wars_query_tool will read from the sample_starwars_embeddings collection. Similarly, create a tool to read from the sample_startrek_embeddings collection. The Reasoning Engine will redirect the query to read from the Star Wars or Star Trek collection based on the reasoning and prompt set by the user while creating the tools.
1 agent = reasoning_engines.LangchainAgent( 2 model=model, 3 tools=[star_wars_query_tool, star_trek_query_tool], 4 agent_executor_kwargs={"return_intermediate_steps": True}, 5 ) 6 agent.query(input="tell me about star wars?")
With the model, tools, and reasoning logic defined and tested locally, it's time to deploy your agent as a remote service on Vertex AI. We have used:
1 remote_agent = reasoning_engines.ReasoningEngine.create( 2 agent, 3 requirements=[ 4 "google-cloud-aiplatform[langchain,reasoningengine]", 5 "cloudpickle==3.0.0", 6 "pydantic==2.7.4", 7 "langchain-mongodb", 8 "pymongo", 9 "langchain-google-vertexai", 10 11 ], 12 )
The output will include the deployment details for the Reasoning Engine that can be used to implement the user application.
1 INFO:vertexai.reasoning_engines._reasoning_engines:reasoning_engine = vertexai.preview.reasoning_engines.ReasoningEngine('projects/project-id/locations/us-central1/reasoningEngines/reasoning-engine-id') 2 3 from vertexai.preview import reasoning_engines 4 REASONING_ENGINE_RESOURCE_NAME = "projects/project-id/locations/us-central1/reasoningEngines/reasoning-engine-id" 5 remote_agent = reasoning_engines.ReasoningEngine(REASONING_ENGINE_RESOURCE_NAME) 6 response = remote_agent.query(input="Tell me about episode 1 from wars")
You can also debug and optimize your agents by enabling tracing in the Reasoning Engine. View the notebook that explains how you can use Cloud Trace for exploring the tracing data to get insights.
Every aspect of your agent is customizable, from core instructions and starting prompts to managing conversation history for a seamless, context-aware experience across multiple queries. Follow the instructions in the Python notebook of the GitHub repository to create your own agent. The solution in this post can be easily extended to have an agent with multiple and any kind of LangChain tools (like function calling and extensions) and to have an application with multiple agents. We will talk about the multi-agents with MongoDB and Google Cloud in detail in our follow-up articles.
Want $500 in credits for the Google Marketplace? Simply check out our program, subscribe to Atlas, and claim your credits today, and try out Atlas on the GCP marketplace for your new workload.
Top Comments in Forums
There are no comments on this article yet.
Rate this tutorial