Building AI and RAG Apps With MongoDB, Anyscale and PyMongo





.jpg&w=3840&q=75)
Rate this quickstart


The AI pillar has become a significant consideration in modern applications. The enterprise industry is very interested in modernizing and involving AI models in enterprise applications. However, using publicly available APIs and relying on public services will not suit all enterprises, especially if they require high-scale and secure data segregation.
Having said that, increasingly, more enterprises are moving to the cloud to build applications at scale in fast, competitive cycles, utilizing smart and robust deployment services. This is where the MongoDB Atlas data platform and the Anyscale AI compute platform come in.
Anyscale is a platform for running distributed applications using Ray, an open-source framework for building scalable applications. Integrating MongoDB Atlas with Anyscale and PyMongo, can help you efficiently manage and analyze large datasets by leveraging Ray's distributed computing capabilities while using MongoDB as the backend database.
Using Anyscale for fast and efficient LLM inference and MongoDB Atlas scalable vector indexing for contextual search, users can build and deploy super scalable, AI-based retrieval-augmented generation (RAG) flows and agentic systems.
In this tutorial, we will cover the following main aspects of creating a scalable RAG back end for your application:
- Deploy a scalable vector store using MongoDB Atlas.
- Deploy the required embedding model and LLM on Anyscale.
- Connect the vector store with your deployed service using PyMongo and Anyscale services.
Get the MongoDB connection string and allow access from relevant IP addresses. For this tutorial, you will use the
0.0.0.0/0 network access list.For production deployments, users can manage VPCs and private networks on the Anyscale platform and connect them securely via VPC peering or cloud private endpoints to Atlas.
Using the Data Explorer or a Compass connection, create the following collection to host our application context for the RAG process. Use database name
anyscale_db and collection name stories. Once the collection is created, head to the Atlas Search tab (or the Index tab in Compass using the Atlas search toggle) and create the following vector index:name : vector_index
1 { 2 "fields": [ 3 { 4 "type": "vector", 5 "path": "embedding", 6 "numDimensions": 1024, 7 "similarity": "cosine" 8 } 9 ] 10 }
Register for an account and get free compute credits to try out the Anyscale platform.
Anyscale offers a simple-to-follow template that you can launch from within the Anyscale platform to optimally self-host the models for your RAG service leveraging ray-LLM. ray-LLM makes use of best-in-class optimizations from inference libraries like vLLM and offers an OpenAI-compatible API for our deployed models.
With Anyscale, you get the flexibility to choose the hardware and autoscaling configurations for the models so you can trade off cost and performance given your use case.
For the purposes of our guide, we will:
We will use the default values given they offer a good starting point for hardware and autoscaling configurations.
Please note that some models require approval on the Hugging Face website.
Once you deploy the above models, you should have two working services with accessible API URL and bearer tokens:
Let's say that the embedding deployed service is on:
1 https://XXXXXXXXXXXX.anyscaleuserdata.com
Take note of the embedding bearer as it will be used as our API key for embedding related tasks.
The LLM is deployed to another endpoint:
1 https://YYYYYYYYYYYYY.anyscaleuserdata.com
Take note of the LLM bearer as it will be used as our API key for LLM-related tasks.
Create a workspace template to build our RAG service. We recommend you launch the Intro to Services template to get a running workspace that showcases how to deploy your first Anyscale service.
You can think of an Anyscale workspace as an IDE (Visual Studio) running against an elastically scalable compute cluster.
We will use this workspace to create all our services.
Let's start by specifying the dependencies and environment variables that our RAG service will require…
1 pip install pymongo openai fastapi
…by clicking on the Dependencies tab as shown in the screenshot below:
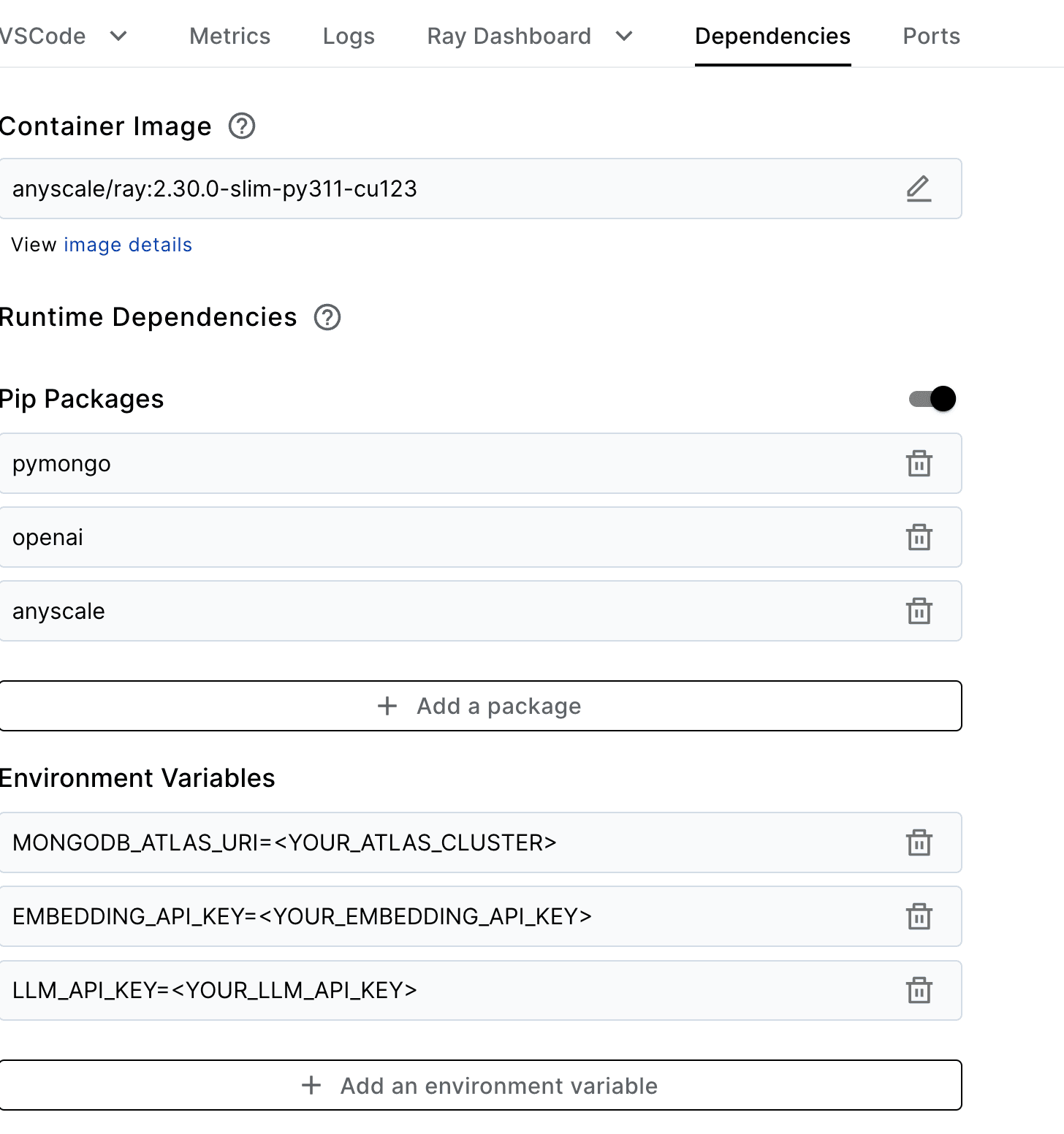
You will need to place the API keys as environment variables in Workspace > YOUR NAME > Dependencies:
- Place the embedding bearer as an environment variable in the workspace:
EMBEDDING_API_KEY
- Place the LLM bearer as an environment variable in our workspace:
LLM_API_KEY
- Place your Atlas connection string (e.g.,
mongodb+srv://<user>:<pass>@cluster0.abcd.mongodb.net/):MONGODB_ATLAS_URI
Remember to replace the values with your cluster connection string and your keys.
Now, you can use those services to build your RAG service to use private embedding endpoints and LLM. Those are compatible with the OpenAI client, and therefore, you can use the OpenAI client as part of our MongoDB RAG service as follows.
Create a new file named
main.py in the root directory of the workspace.1 from typing import Any 2 from fastapi import FastAPI, HTTPException 3 from pydantic import BaseModel 4 from pymongo import MongoClient 5 import os 6 import openai 7 from dotenv import load_dotenv 8 from ray import serve 9 import logging 10 11 # Initialize FastAPI 12 fastapi = FastAPI() 13 14 # Initialize logger 15 logger = logging.getLogger("ray.serve") 16 17 # Data model for the request 18 class QueryModel(BaseModel): 19 query: str 20 21 22 23 class MongoDBRag: 24 25 def __init__(self): 26 # MongoDB connection 27 client = MongoClient(os.getenv("MONGODB_ATLAS_URI")) 28 db = client["anyscale_db"] 29 self.collection = db["stories"] 30 31 # AI Client initialization 32 # LLM endpoint for text generation 33 self.openai_llm = openai.OpenAI( 34 base_url="https://YYYYYYYYYYYYY.anyscaleuserdata.com/v1", 35 api_key=os.getenv('LLM_API_KEY') 36 ) 37 38 # Embedding endpoint for vector embeddings 39 self.openai_embedding = openai.OpenAI( 40 base_url="https://XXXXXXXXXXXX.anyscaleuserdata.com/v1", 41 api_key=os.getenv('EMBEDDING_API_KEY') 42 ) 43 44 45 async def rag_endpoint(self, query: QueryModel) -> Any: 46 try: 47 # Generate embedding for the input query 48 embedding = self.openai_embedding.embeddings.create( 49 model="thenlper/gte-large", 50 input=query.query, 51 ) 52 53 # Perform vector search in MongoDB to find relevant context 54 context = list(self.collection.aggregate([ 55 {"$vectorSearch": { 56 "queryVector": embedding.data[0].embedding, 57 "index": "vector_index", 58 "numCandidates": 3, 59 "path": "embedding", 60 "limit": 1 61 }}, 62 { 63 "$project": { 64 "_id": 0, 65 "embedding": 0 66 } 67 } 68 ])) 69 70 # Construct prompt with context and query 71 prompt = f""" Based on the following context please answer and elaborate the user query. 72 context: {context} 73 74 query: {query.query} 75 Answer: """ 76 77 # Generate response using LLM 78 chat_completion = self.openai_llm.chat.completions.create( 79 model="meta-llama/Llama-2-70b-chat-hf", 80 messages=[ 81 {"role": "system", "content": "You are a helpful QA assistant"}, 82 {"role": "user", "content": prompt} 83 ], 84 temperature=0.7 85 ) 86 87 answer = chat_completion.choices[0].message.content 88 89 return answer 90 91 except Exception as e: 92 raise HTTPException(status_code=500, detail=str(e)) 93 94 # Bind the deployment 95 my_app = MongoDBRag.bind()
This service utilizes Ray Serve integrated with FastAPI to connect MongoDB Atlas with the embedding model and the LLM services that we previously deployed.
- All state initialization (e.g., loading model weights, creating database and client connections) is defined under the "init" method.
- HTTP routes are defined by wrapping a method with the corresponding FastAPI decorator like we did with the
rag_endpointmethod.
To generate a sample subset of data to test our RAG service, we suggest running the code snippet below (eg.
generate_embeddings.py):1 from pymongo import MongoClient 2 import os 3 import openai 4 from dotenv import load_dotenv 5 6 client = MongoClient(os.getenv("MONGODB_ATLAS_URI")) 7 db = client["anyscale_db"] 8 collection = db["stories"] 9 10 # Embedding endpoint for vector embeddings 11 openai_embedding = openai.OpenAI( 12 base_url="https://XXXXXXXXXXXX.anyscaleuserdata.com/v1", 13 api_key=os.getenv('EMBEDDING_API_KEY') 14 ) 15 16 def generate_data() -> str: 17 # Sample data to be inserted into MongoDB 18 data = [ 19 "Karl lives in NYC and works as a chef", 20 "Rio lives in Brasil and works as a barman", 21 "Jessica lives in Paris and works as a programmer." 22 ] 23 24 for info in data: 25 # Generate embedding for each piece of information 26 embedding = openai_embedding.embeddings.create( 27 model="thenlper/gte-large", 28 input=info, 29 ) 30 31 # Update or insert the data with its embedding into MongoDB 32 collection.update_one( 33 {'story': info}, 34 {'$set': {'embedding': embedding.data[0].embedding}}, 35 upsert=True 36 ) 37 38 return "Data Ingested Successfully" 39 40 generate_data()
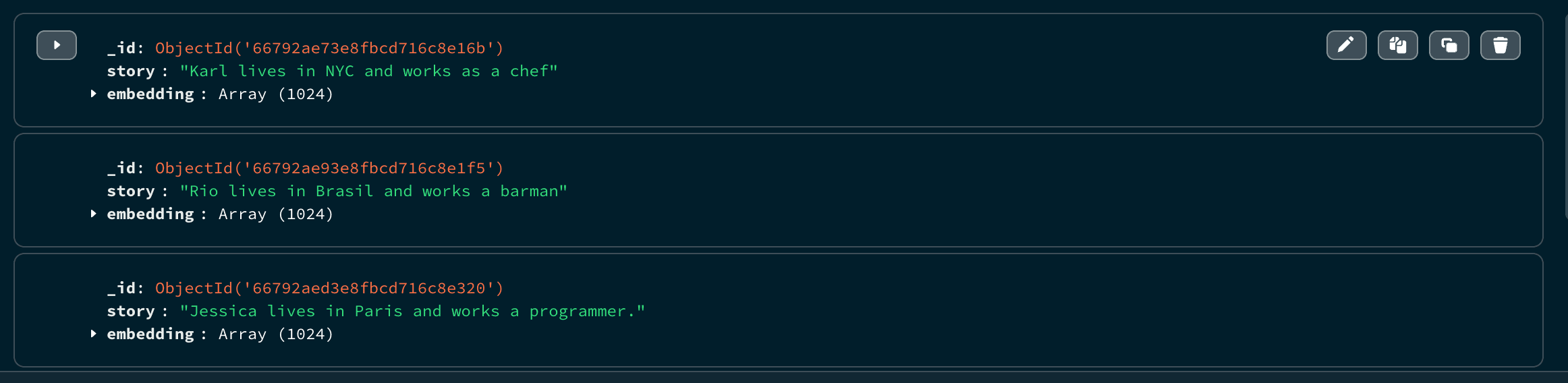
You can now access the service. Let's ingest the data to create the collection with embeddings and populate our “stories” collection with three sample documents:
1 data = [ 2 "Karl lives in NYC and works as a chef", 3 "Rio lives in Brasil and works as a barman", 4 "Jessica lives in Paris and works as a programmer." 5 ]
Use the following command to load data:
1 python generate.py
The collection was added with the following stories and embeddings:
Note for scaling out text embedding generation, you can follow the workspace template for computing text embeddings at scale. This template leverages best practices for batch inference of embedding models to maximize the throughput of the underlying heterogeneous cluster of CPUs and GPUs.
Now, run the service locally:
1 serve run main:my_app --non-blocking
Now, the RAG endpoint is active on rag_endpoint:
1 payload = {"query": "Main character list"} 2 3 4 # Perform the POST request 5 response = requests.post("http://localhost:8000/rag_endpoint", json=payload) 6 7 # Print the response in JSON format 8 print(response.json())
The expected output:
1 Based on the provided context, the main character list is: 2 3 4 1. Jessica 5 2. Rio 6 3. Karl
Now that you have tested the service by running locally within the workspace, you can proceed to deploy it as a standalone Anyscale service which is accessible via a URL and bearer token to external users.
1 anyscale services deploy main:my_app --name=my-rag-service
Once the command is successfully propagated, you will get the service endpoint URL and its “bearer” token for authorization:
1 (anyscale +2.0s) Starting new service 'my-rag-service'. 2 (anyscale +4.5s) Using workspace runtime dependencies env vars: {'MONGODB_ATLAS_URI': '<YOUR_URI>', 'LLM_API_KEY': '<YOURKEY>', 'EMBEDDING_API_KEY': '<YOURKEY>'}. 3 (anyscale +4.5s) Uploading local dir '.' to cloud storage. 4 (anyscale +5.5s) Including workspace-managed pip dependencies. 5 (anyscale +6.1s) Service 'my-rag-service' deployed. 6 (anyscale +6.1s) View the service in the UI: 'https://console.anyscale.com/services/service2_wx8ar3cbuf84g9u87g3yvx2cq8' 7 (anyscale +6.1s) Query the service once it's running using the following curl command: 8 (anyscale +6.1s) curl -H 'Authorization: Bearer xxxxxxx' https://my-rag-service-yyyy.xxxxxxxxxxxx.s.anyscaleuserdata.com/
The service you deployed will be visible under the Services tab on the Anyscale platform:
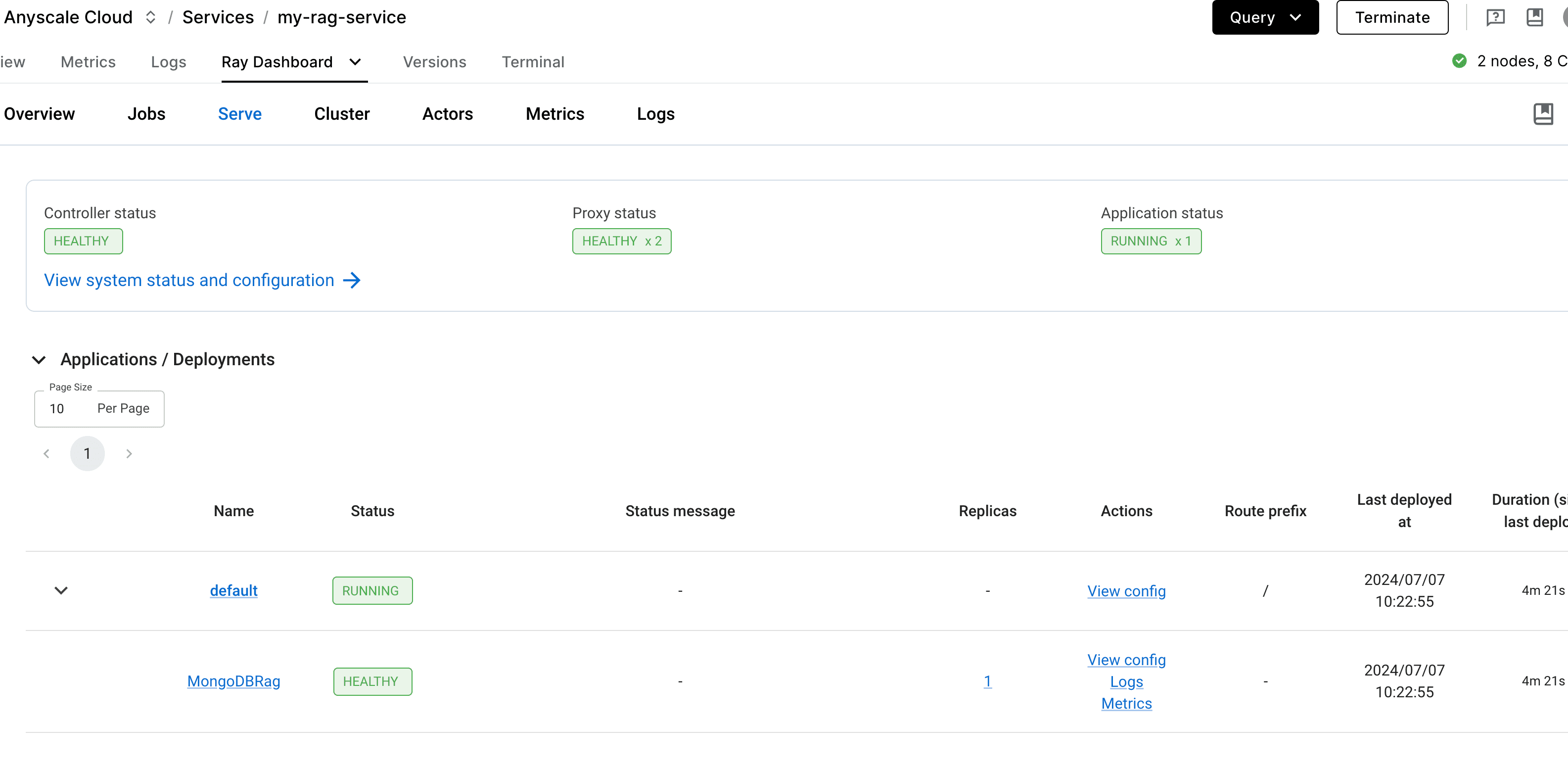
Once the service is healthy, you will be able to access it via the provided URL and credentials the same way that you did in the workspace:
1 curl -X POST \ 2 -H "Authorization: Bearer XXXX" \ 3 -H "Content-Type: application/json" \ 4 https://my-rag-service-yyyy.cld-yga7qm8f6yamqev7.s.anyscaleuserdata.com/rag_endpoint/ \ 5 --data-raw '{"query": "What are the main character names?" }' 6 "The main character names mentioned in the stories are Jessica, Karl and Rio."
Integrating MongoDB with Anyscale and PyMongo enables powerful distributed data processing and analysis workflows. By combining MongoDB's flexible document model, Atlas developer data platform built-in scalability, and vector search capabilities with Anyscale's distributed computing platform, developers can build scalable RAG pipelines and AI-powered applications.
- MongoDB Atlas provides a managed database solution with vector indexing for semantic search.
- Anyscale offers a platform for running distributed Python applications using Ray.
- PyMongo allows easy interaction with MongoDB from Python. These technologies enable the building of performant RAG systems that can scale.
This tutorial walked through setting up a basic RAG service using MongoDB, Anyscale, and open-source language models. For production use cases, consider:
- Fine-tuning models on domain-specific data.
- Implementing caching and batching for improved performance.
- Adding monitoring and observability.
- Scaling up compute resources as needed.
Integrating MongoDB and Anyscale opens up exciting possibilities for building AI applications that can efficiently process and reason over large datasets. We encourage you to explore further and push the boundaries of what's possible with these powerful tools.
Top Comments in Forums
There are no comments on this article yet.