How to Seamlessly Use MongoDB Atlas and IBM watsonx.ai LLMs in Your GenAI Applications

Ashwin Gangadhar9 min read • Published Sep 18, 2024 • Updated Sep 18, 2024





Rate this tutorial


One of the challenges of e-commerce applications is to provide relevant and personalized product recommendations to customers. Traditional keyword-based search methods often fail to capture the semantic meaning and intent of the user search queries, and return results that do not meet the user’s needs. In turn, they fail to convert into a successful sale. To address this problem, RAG (retrieval-augmented generation) is used as a framework powered by MongoDB Atlas Vector Search, LangChain, and IBM watsonx.ai.
RAG is a natural language generation (NLG) technique that leverages a retriever module to fetch relevant documents from a large corpus and a generator module to produce text conditioned on the retrieved documents. Here, the RAG framework is used to power product recommendations as an extension to existing semantic search techniques.
- RAG use cases can be easily built using the vector search capabilities of MongoDB Atlas to store and query large-scale product embeddings that represent the features and attributes of each product. Because of MongoDB’s flexible schema, these are stored right alongside the product embeddings, eliminating the complexity and latency of having to retrieve the data from separate tables or databases.
- RAG then retrieves the most similar products to the user query based on the cosine similarity of their embeddings, and generates natural language reasons that highlight why these products are relevant and appealing to the user.
- RAG can also enhance the user experience (UX) by handling complex and diverse search queries, such as "a cozy sweater for winter" or "a gift for my daughter who is interested in science", and provides accurate and engaging product recommendations that increase customer satisfaction and loyalty.
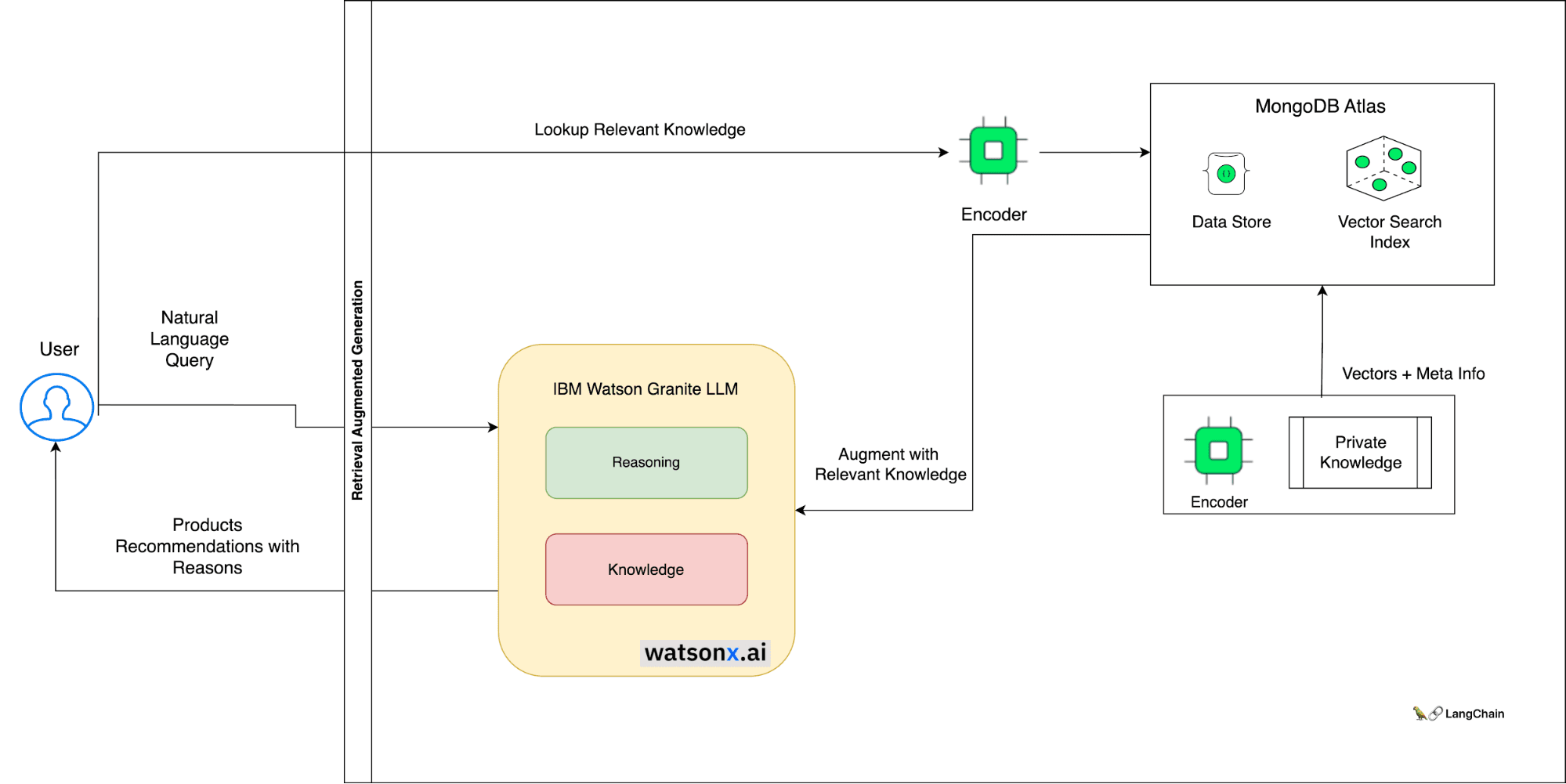
To enable RAG to retrieve relevant documents, we need a vector search engine that can efficiently store and query large-scale document embeddings. MongoDB Atlas allows us to index documents based on their embeddings and perform similarity search using cosine distance, euclidean distance, or dot product. MongoDB Atlas also provides flexible schema, scalability, security, and performance features that over 45,000 organizations — from startups to enterprises and governments — rely on.
By using RAG with MongoDB Atlas Vector Search, we can enhance the user experience of product recommendations in several ways. First, we can provide more personalized and diverse recommendations that match the user's query or context. Second, we can generate more informative and engaging responses that can explain why each product is recommended and how it compares to others. Third, we can improve the relevance and accuracy of the recommendations by updating the document embeddings as MongoDB is primarily an operational data layer (ODL) that provides transaction features.
Watsonx.ai is IBM’s next-generation enterprise studio for AI builders, bringing together new generative AI capabilities with traditional machine learning (ML) that span the entire AI lifecycle. With watsonx.ai, you can train, validate, tune, and deploy foundation and traditional ML models.
watsonx.ai brings forth a curated library of foundation models, including IBM-developed models, open-source models, and models sourced from third-party providers. Not all models are created equal, and the curated library provides enterprises with the optionality to select the model best suited to a particular use case, industry, domain, or even price performance. Further, IBM-developed models, such as the Granite model series, offer another level of enterprise-readiness, transparency, and indemnification for production use cases. We’ll be using Granite models in our demonstration. For the interested reader, IBM has published information about its data and training methodology for its Granite foundation models.
For this tutorial, we will be using an e-commerce products dataset containing over 10,000 product details. We will be using the sentence-transformers/all-mpnet-base-v2 model from Hugging Face to generate the vector embeddings to store and retrieve product information. You will need a Python notebook or an IDE, a MongoDB Atlas account, and a wastonx.ai account for hands-on experience.
For convenience, the notebook to follow along and execute in your environment is available on GitHub.
langchain: Orchestration frameworkibm-watson-machine-learning: For IBM LLMswget: To download knowledge base datasentence-transformers: For embedding modelpymongo: For the MongoDB Atlas vector store
We’ll be using the watsonx.ai foundation models and Python SDK to implement our RAG pipeline in LangChain.
- Create a watsonx.ai Project. During onboarding, a sandbox project can be quickly created for you. You can either use the sandbox project or create one; the link will work once you have registered and set up watsonx.ai. If more help is needed, you can read the documentation.
- Install and use watsonx.ai. Also known as the IBM Watson Machine Learning SDK, watsonx.ai SDK information is available on GitHub. Like any other Python module, you can install it with a pip install. Our example notebook takes care of this for you.
We will be running all the code snippets below in a Jupyter notebook. You can choose to run these on VS Code or any other IDE of your choice.
Initialize the LLM
Initialize the watsonx URL to connect by running the below code blocks in your Jupyter notebook:
1 # watsonx URL 2 3 try: 4 wxa_url = os.environ["WXA_URL"] 5 6 except KeyError: 7 wxa_url = getpass.getpass("Please enter your watsonx.ai URL domain (hit enter): ")
To be able to access the LLM models and other AI services on watsonx, you need to initialize the API key. You init the API key by running the following code block in you Jupyter notebook:
1 # watsonx API Key 2 3 try: 4 wxa_api_key = os.environ["WXA_API_KEY"] 5 except KeyError: 6 wxa_api_key = getpass.getpass("Please enter your watsonx.ai API key (hit enter): ")
You will be prompted when you run the above code to add the IAM API key you fetched earlier.
Each experiment can tagged or executed under specific projects. To fetch the relevant project, we can initialize the project ID by running the below code block in the Jupyter notebook:
1 # watsonx Project ID 2 3 try: 4 wxa_project_id = os.environ["WXA_PROJECT_ID"] 5 except KeyError: 6 wxa_project_id = getpass.getpass("Please enter your watsonx.ai Project ID (hit enter): ")
You can find the project ID alongside your IAM API key in the settings panel in the watsonx.ai portal.
Language model
In the code example below, we will initialize Granite LLM from IBM and then demonstrate how to use the initialized LLM with the LangChain framework before we build our RAG.
We will use the query: "I want to introduce my daughter to science and spark her enthusiasm. What kind of gifts should I get her?"
This will help us demonstrate how the LLM and vector search work in an RAG framework at each step.
Firstly, let us initialize the LLM hosted on the watsonx cloud. To access the relevant Granite model from watsonx, you need to run the following code block to initialize and test the model with our sample query in the Jupyter notebook:
1 from ibm_watson_machine_learning.foundation_models.utils.enums import ModelTypes 2 from ibm_watson_machine_learning.foundation_models import Model 3 from ibm_watson_machine_learning.metanames import GenTextParamsMetaNames as GenParams 4 from ibm_watson_machine_learning.foundation_models.utils.enums import DecodingMethods 5 6 parameters = { 7 GenParams.DECODING_METHOD: DecodingMethods.GREEDY, 8 GenParams.MIN_NEW_TOKENS: 1, 9 GenParams.MAX_NEW_TOKENS: 100 10 } 11 12 model = Model( 13 model_id=ModelTypes.GRANITE_13B_INSTRUCT, 14 params=parameters, 15 credentials={ 16 "url": wxa_url, 17 "apikey": wxa_api_key 18 }, 19 project_id=wxa_project_id 20 ) 21 22 from ibm_watson_machine_learning.foundation_models.extensions.langchain import WatsonxLLM 23 24 granite_llm_ibm = WatsonxLLM(model=model) 25 26 # Sample query chosen in the example to evaluate the RAG use case 27 query = "I want to introduce my daughter to science and spark her enthusiasm. What kind of gifts should I get her?" 28 29 # Sample LLM query without RAG framework 30 result = granite_llm_ibm(query)
Output:

Prior to starting this section, you should have already set up a cluster in MongoDB Atlas. If you have not created one for yourself, then you can follow the steps in the MongoDB Atlas tutorial to create an account in Atlas (the developer data platform) and a cluster with which we can store and retrieve data. It is also advised that the users spin an Atlas dedicated cluster with size M10 or higher for this tutorial.
Now, let us see how we can set up MongoDB Atlas to provide relevant information to augment our RAG framework.
Init Mongo client
We can connect to the MongoDB Atlas cluster using the connection string as detailed in the tutorial link above. To initialize the connection string, run the below code block in your Jupyter notebook:
1 from pymongo import MongoClient 2 3 try: 4 MONGO_CONN = os.environ["MONGO_CONN"] 5 except KeyError: 6 MONGO_CONN = getpass.getpass("Please enter your MongoDB connection String (hit enter): ")
When prompted, you can enter your MongoDB Atlas connection string.
Download and load data to MongoDB Atlas
In the steps below, we demonstrate how to download the products dataset from the provided URL link and add the documents to the respective collection in MongoDB Atlas. We will also be embedding the raw product texts as vectors before adding them in MongoDB. You can do this by running the following lines of code your Jupyter notebook:
1 import wget 2 3 filename = './amazon-products.jsonl' 4 url = "https://github.com/ashwin-gangadhar-mdb/mbd-watson-rag/raw/main/amazon-products.jsonl" 5 6 if not os.path.isfile(filename): 7 wget.download(url, out=filename) 8 9 # Load the documents using Langchain Document Loader 10 from langchain.document_loaders import JSONLoader 11 12 loader = JSONLoader(file_path=filename, jq_schema=".text",text_content=False,json_lines=True) 13 docs = loader.load() 14 15 # Initialize Embedding for transforming raw documents to vectors** 16 from langchain.embeddings import HuggingFaceEmbeddings 17 from tqdm import tqdm as notebook_tqdm 18 19 embeddings = HuggingFaceEmbeddings() 20 21 # Initialize MongoDB client along with Langchain connector module 22 from langchain.vectorstores import MongoDBAtlasVectorSearch 23 24 client = MongoClient(MONGO_CONN) 25 vcol = client["amazon"]["products"] 26 vectorstore = MongoDBAtlasVectorSearch(vcol, embeddings) 27 28 # Load documents to collection in MongoDB** 29 vectorstore.add_documents(docs)
You will be able to see the documents have been created in
amazon database under the collection products.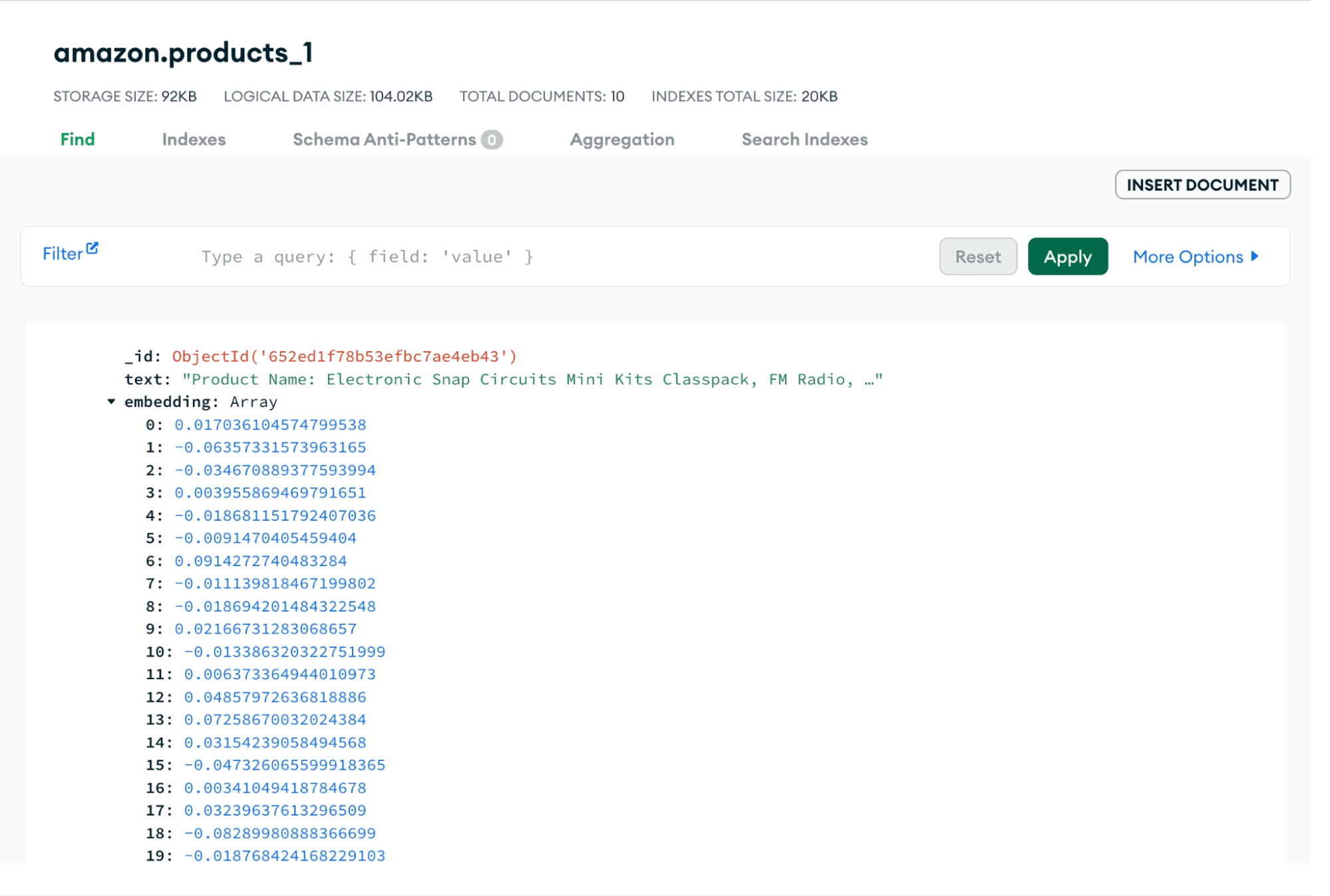
Now all the product information is added to the respective collection, we can go ahead and create a vector index by following the steps given in the Atlas Search index tutorial. You can create the search index using both the Atlas UI as well as programmatically. Let us look at the steps if we are doing this using the Atlas UI.
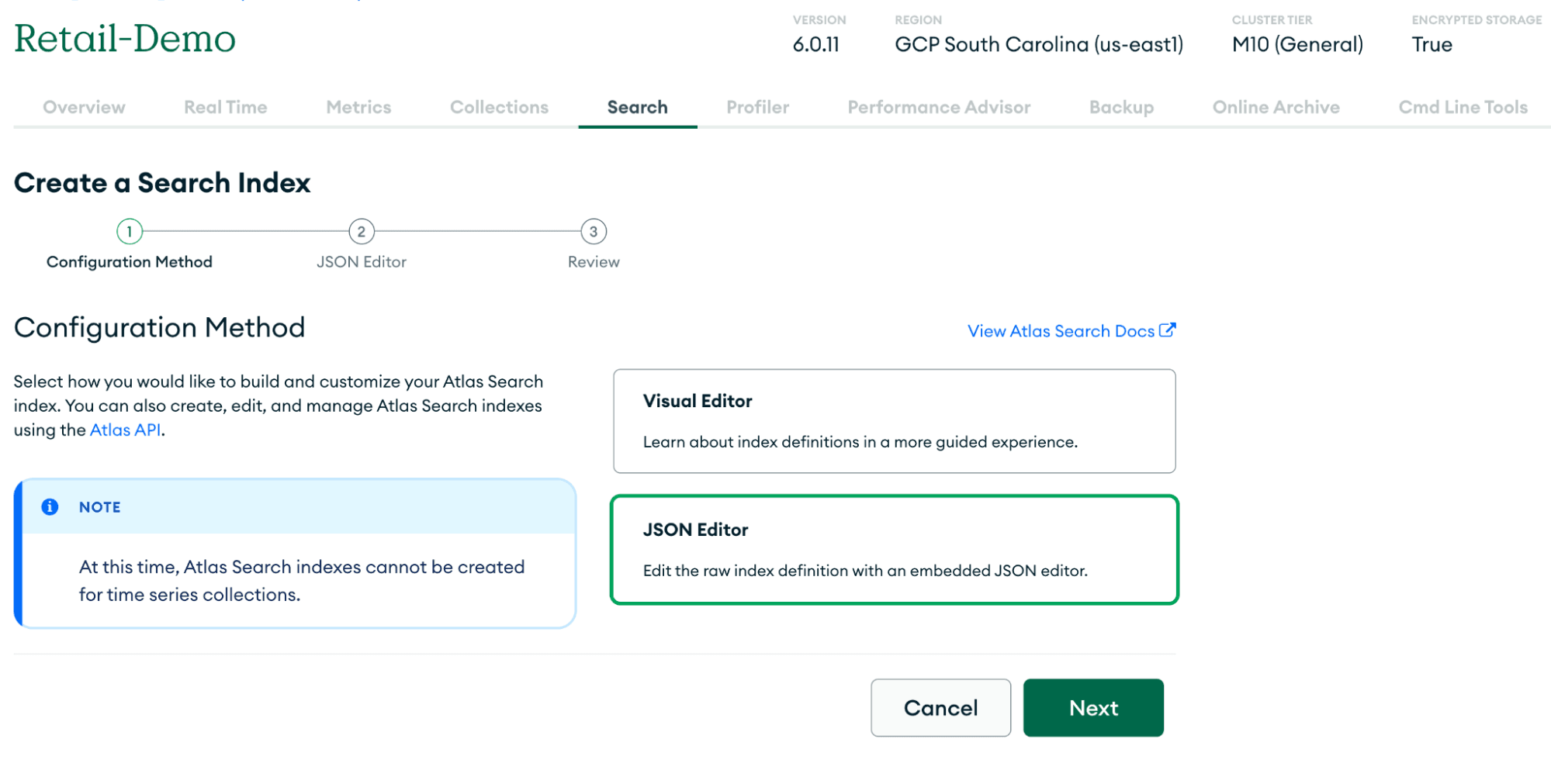
You can select the Json Editor view to insert the vector search index config as shown in the image. Insert the following mapping to create the vector indexes.
1 { 2 "mappings": { 3 "dynamic": true, 4 "fields": { 5 "embedding": [ 6 { 7 "dimensions": 768, 8 "similarity": "cosine", 9 "type": "knnVector" 10 } 11 ] 12 } 13 } 14 }
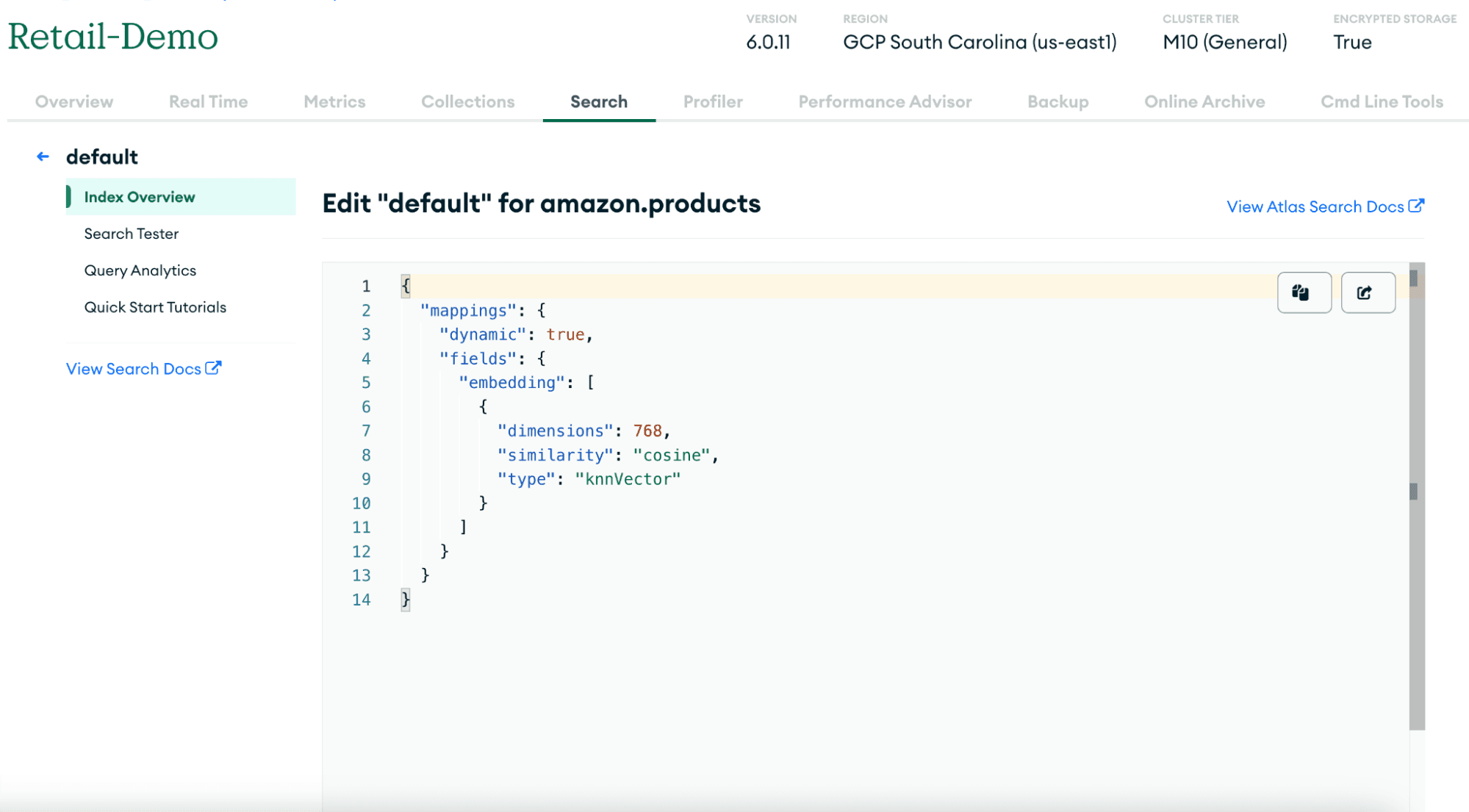
Once you have updated the vector search indexes in the Atlas UI, this will start an automatic process to create the vector search indexes for the collection for the first time. Also, this will automatically index any new document added to the collection. Seamlessly, you will be able to update the collection in real time as you add new products and augment the RAG framework so that users are always served with the latest and greatest products you are offering.
For a description of the other fields in this configuration, you can check out our Vector Search documentation.
Sample query to vector search
We can test the vector similarity search by running the sample query with the LangChain MongoDB Atlas Vector Search connector. Run the following code in your Jupyter notebook:
1 texts_sim = vectorstore.similarity_search(query, k=3) 2 3 print("Number of relevant texts: " + str(len(texts_sim))) 4 print("First 100 characters of relevant texts.") 5 6 for i in range(len(texts_sim)): 7 print("Text " + str(i) + ": " + str(texts_sim[i].page_content[0:100]))
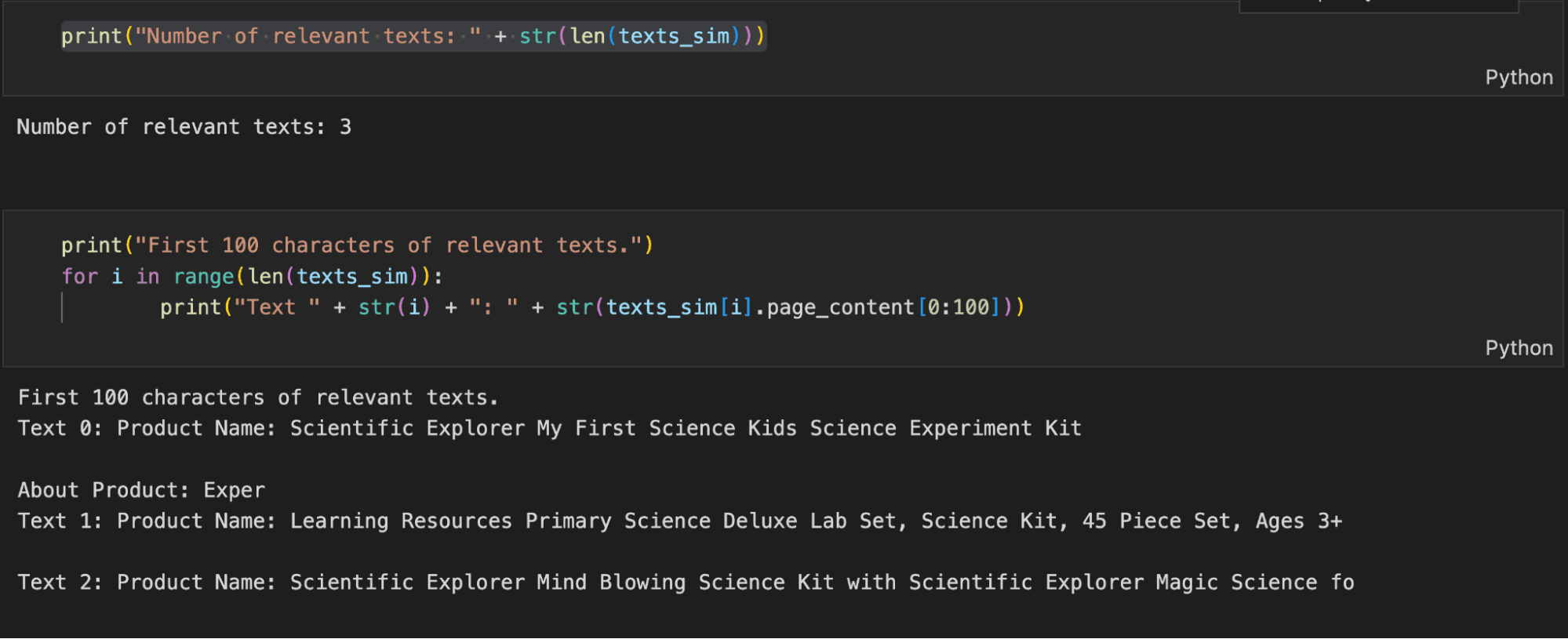
In the above example code, we are able to use our sample text query to retrieve three relevant products. Further in the tutorial, let’s see how we can combine the capabilities of LLMs and vector search to build a RAG framework. For further information on various operations you can perform with the
MongoDBAtlasVectorSearch module in LangChain, you can visit the Atlas Vector Search documentation.In the code snippets below, we demonstrate how to initialize and query the RAG chain. We also introduce methods to improve the output from RAG so you can customize your output to cater to specific needs, such as the reason behind the product recommendation, language translation, summarization, etc.
So, you can set up the RAG chain and execute to get the response for our sample query by running the following lines of code in your Jupyter notebook:
1 from langchain.chains import RetrievalQA 2 from langchain.prompts import PromptTemplate 3 4 prompt = PromptTemplate(template=""" 5 6 Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. 7 8 {context} 9 10 ##Question:{question} \n\ 11 12 ##Top 3 recommnedations from Products and reason:\n""",input_variables=["context","question"]) 13 14 chain_type_kwargs = {"prompt": prompt} 15 retriever = vectorstore.as_retriever(search_type="mmr", search_kwargs={'k': 6, 'lambda_mult': 0.25}) 16 17 qa = RetrievalQA.from_chain_type(llm=granite_llm_ibm, chain_type="stuff", 18 retriever=retriever, 19 chain_type_kwargs=chain_type_kwargs) 20 21 res = qa.run(query) 22 23 print(f"{'-'*50}") 24 print("Query: " + query) 25 print(f"Response:\n{res}\n{'-'*50}\n")
The output will look like this:

You can see from the example output where the RAG is able to recommend products based on the query as well as provide a reasoning or explanation as to how this product suggestion is relevant to the query, thereby enhancing the user experience.
In this tutorial, we demonstrated how to use watsonx LLMs along with Atlas Vector Search to build a RAG framework. We also demonstrated how to efficiently use the RAG framework to customize your application needs, such as the reasoning for product suggestions. By following the steps in the article, we were also able to bring the power of machine learning models to a private knowledge base that is stored in the Atlas Developer Data Platform.
In summary, RAG is a powerful NLG technique that can generate product recommendations as an extension to semantic search using vector search capabilities provided by MongoDB Atlas. RAG can also improve the UX of product recommendations by providing more personalized, diverse, informative, and engaging descriptions.
Explore more details on how you can build generative AI applications using various assisted technologies and MongoDB Atlas Vector Search.
To learn more about Atlas Vector Search, visit the product page or the documentation for creating a vector search index or running vector search queries.
Top Comments in Forums


Jack_WoehrJack Woehr2 quarters ago
Now you’re talking my language!