How to Choose the Best Embedding Model for Your LLM Application






Rate this tutorial


If you are building generative AI (GenAI) applications in 2024, you’ve probably heard the term “embeddings” a few times by now and are seeing new embedding models hit the shelf every week. So why do so many people suddenly care about embeddings, a concept that has existed since the 1950s? And if embeddings are so important and you must use them, how do you choose among the vast number of options for embedding models out there?
This tutorial will cover the following:
- What is an embedding?
- Importance of embeddings in RAG applications
- How to choose the best embedding model for your RAG application
- Evaluating embedding models
This tutorial is Part 1 of a multi-part series on retrieval-augmented generation (RAG), where we start with the fundamentals of building a RAG application, and work our way to more advanced techniques for RAG. The series will cover the following:
An embedding is an array of numbers (a vector) representing a piece of information, such as text, images, audio, video, etc. Together, these numbers capture semantics and other important features of the data. The immediate consequence of doing this is that semantically similar entities map close to each other while dissimilar entities map farther apart in the vector space. For clarity, see the image below for a depiction of a high-dimensional vector space:
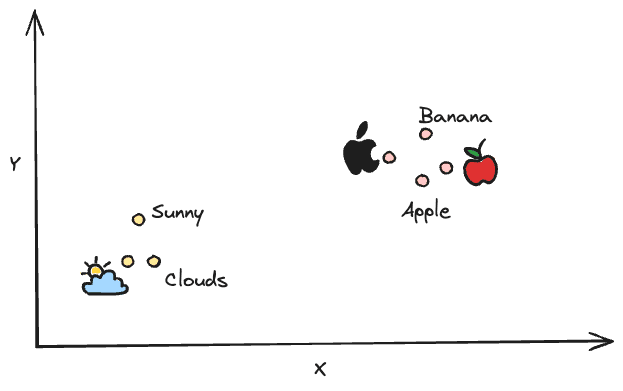
In the context of natural language processing (NLP), embedding models are algorithms designed to learn and generate embeddings for a given piece of information. In today’s AI applications, embeddings are typically created using large language models (LLMs) that are trained on a massive corpus of data and use cutting-edge algorithms to learn complex semantic relationships in the data.
Retrieval-augmented generation, as the name suggests, aims to improve the quality of pre-trained LLM generation using data retrieved from a knowledge base. The success of RAG lies in retrieving the most relevant results from the knowledge base. This is where embeddings come into the picture. A RAG pipeline looks something like this:
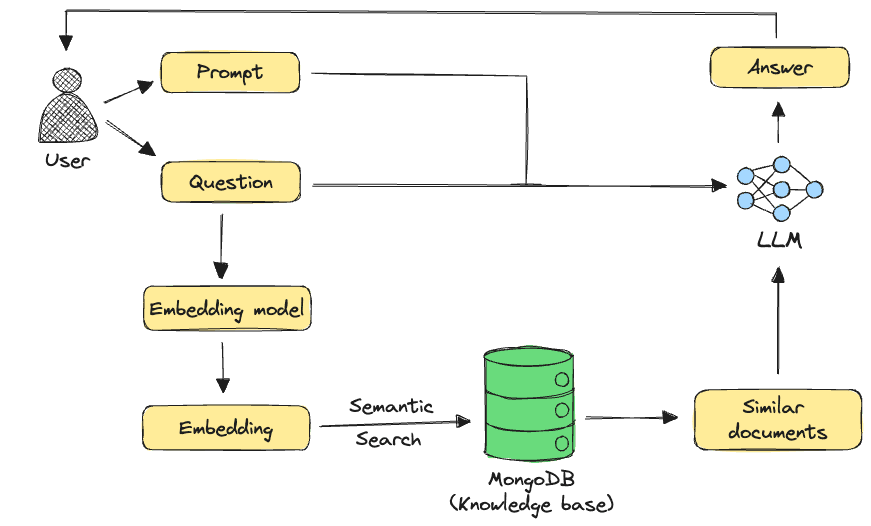
In the above pipeline, we see a common approach used for retrieval in genAI applications — i.e., semantic search. In this technique, an embedding model is used to create vector representations of the user query and of information in the knowledge base. This way, given a user query and its embedding, we can retrieve the most relevant source documents from the knowledge base based on how similar their embeddings are to the query embedding. The retrieved documents, user query, and any user prompts are then passed as context to an LLM, to generate an answer to the user’s question.
As we have seen above, embeddings are central to RAG. But with so many embedding models out there, how do we choose the best one for our use case?
A good place to start when looking for the best embedding models to use is the MTEB Leaderboard on Hugging Face. It is the most up-to-date list of proprietary and open-source text embedding models, accompanied by statistics on how each embedding model performs on various embedding tasks such as retrieval, summarization, etc.
Evaluations of this magnitude for multimodal models are just emerging (see the MME benchmark) so we will only focus on text embedding models for this tutorial. However, all the guidance here on choosing the best embedding model also applies to multimodal models.
Benchmarks are a good place to begin but bear in mind that these results are self-reported and have been benchmarked on datasets that might not accurately represent the data you are dealing with. It is also possible that some embedding models may include the MTEB datasets in their training data since they are publicly available. So even if you choose an embedding model based on benchmark results, we recommend evaluating it on your dataset. We will see how to do this later in the tutorial, but first, let’s take a closer look at the leaderboard.
Here’s a snapshot of the top 10 best embedding models on the leaderboard currently:
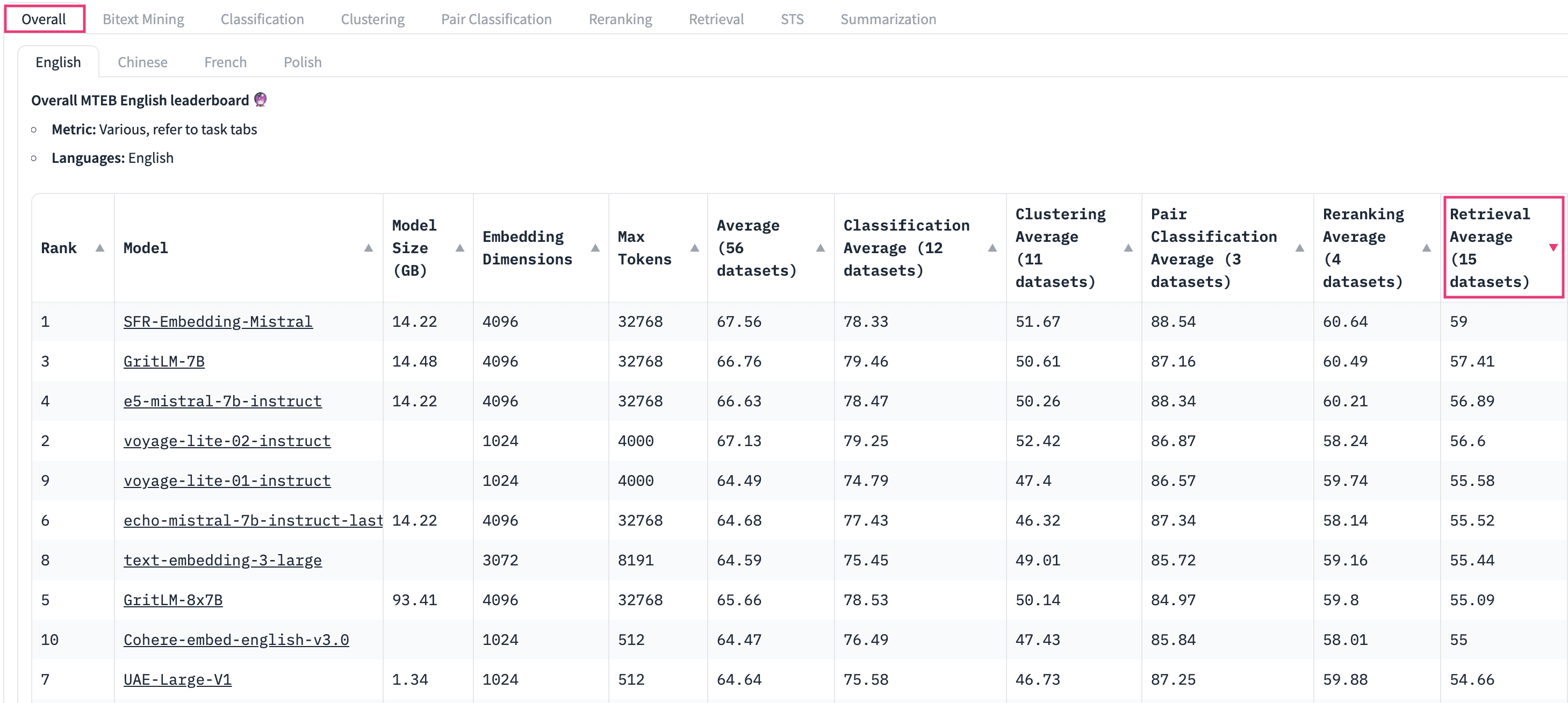
Let’s look at the Overall tab since it provides a comprehensive summary of each embedding model. However, note that we have sorted the leaderboard by the Retrieval Average column. This is because RAG is a retrieval task and we want to see the best retrieval embedding models at the top. We will ignore columns corresponding to other tasks, and focus on the following columns:
- Retrieval Average: Represents average Normalized Discounted Cumulative Gain (NDCG) @ 10 across several datasets. NDCG is a common metric to measure the performance of retrieval systems. A higher NDCG indicates an embedding model that is better at ranking relevant items higher in the list of retrieved results.
- Model Size: Size of the embedding model (in GB). It gives an idea of the computational resources required to run the model. While retrieval performance scales with model size, it is important to note that model size also has a direct impact on latency. The latency-performance trade-off becomes especially important in a production setup.
- Max Tokens: Number of tokens that can be compressed into a single embedding. You typically don’t want to put more than a single paragraph of text (~100 tokens) into a single embedding. So even embedding models with max tokens of 512 should be more than enough.
- Embedding Dimensions: Length of the embedding vector. Smaller embeddings offer faster inference and are more storage-efficient, while more dimensions can capture nuanced details and relationships in the data. Ultimately, we want a good trade-off between capturing the complexity of data and operational efficiency.
The top 10 best embedding models on the leaderboard contain a mix of small vs large and proprietary vs open-source models. Let’s compare some of these to find the best embedding model for our dataset.
Here are some things to note about our evaluation experiment.
MongoDB’s cosmopedia-wikihow-chunked dataset is available on Hugging Face, which consists of prechunked WikiHow-style articles.
- voyage-lite-02-instruct: A proprietary embedding model from VoyageAI
- text-embedding-3-large: One of OpenAI’s latest proprietary embedding models
- UAE-Large-V1: A small-ish (335M parameters) open-source embedding model
We also attempted to evaluate SFR-Embedding-Mistral, currently the #1 best embedding model on the MTEB leaderboard, but the hardware below was not sufficient to run this model. This model and other 14+ GB models on the leaderboard will likely require a/multiple GPU(s) with at least 32 GB of total memory, which means higher costs and/or getting into distributed inference. While we haven’t evaluated this embedding model in our experiment, this is already a good data point when thinking about cost and resources.
We used the following metrics to evaluate embedding performance:
- Embedding latency: Time taken to create embeddings
- Retrieval quality: Relevance of retrieved documents to the user query
1 NVIDIA T4 GPU, 16GB Memory
Evaluation notebooks for each of the above embedding models are available:
To run a notebook, click on the Open in Colab shield at the top of the notebook. The notebook will open in Google Colaboratory.

Click the Connect button on the top right corner to connect to a hosted runtime environment.

Once connected, you can also change the runtime type to use the T4 GPUs available for free on Google Colab.
The libraries required for each embedding model differ slightly, but the common ones are as follows:
- datasets: Python library to get access to datasets available on Hugging Face Hub
- sentence-transformers: Framework for working with text and image embeddings
- numpy: Python library that provides tools to perform mathematical operations on arrays
- pandas: Python library for data analysis, exploration, and manipulation
- tdqm: Python module to show a progress meter for loops
1 ! pip install -qU datasets sentence-transformers numpy pandas tqdm
Additionally for Voyage AI:
voyageai: Python library to interact with OpenAI APIs
1 ! pip install -qU voyageai
Additionally for OpenAI:
openai: Python library to interact with OpenAI APIs
1 ! pip install -qU openai
Additionally for UAE:
transformers: Python library that provides APIs to interact with pre-trained models available on Hugging Face
1 ! pip install -qU transformers
OpenAI and Voyage AI models are available via APIs. So you’ll need to obtain API keys and make them available to the respective clients.
1 import os 2 import getpass
Initialize Voyage AI client:
1 import voyageai 2 VOYAGE_API_KEY = getpass.getpass("Voyage API Key:") 3 voyage_client = voyageai.Client(api_key=VOYAGE_API_KEY)
Initialize OpenAI client:
1 from openai import OpenAI 2 os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:") 3 openai_client = OpenAI()
As mentioned previously, we will use MongoDB’s cosmopedia-wikihow-chunked dataset. The dataset is quite large (1M+ documents). So we will stream it and grab the first 25k records, instead of downloading the entire dataset to disk.
1 from datasets import load_dataset 2 import pandas as pd 3 4 # Use streaming=True to load the dataset without downloading it fully 5 data = load_dataset("MongoDB/cosmopedia-wikihow-chunked", split="train", streaming=True) 6 # Get first 25k records from the dataset 7 data_head = data.take(25000) 8 df = pd.DataFrame(data_head) 9 10 # Use this if you want the full dataset 11 # data = load_dataset("MongoDB/cosmopedia-wikihow-chunked", split="train") 12 # df = pd.DataFrame(data)
Now that we have our dataset, let’s perform some simple data analysis and run some sanity checks on our data to ensure that we don’t see any obvious errors:
1 # Ensuring length of dataset is what we expect i.e. 25k 2 len(df) 3 4 # Previewing the contents of the data 5 df.head() 6 7 # Only keep records where the text field is not null 8 df = df[df["text"].notna()] 9 10 # Number of unique documents in the dataset 11 df.doc_id.nunique()
Now, let’s create embedding functions for each of our embedding models.
For voyage-lite-02-instruct:
1 def get_embeddings(docs: List[str], input_type: str, model:str="voyage-lite-02-instruct") -> List[List[float]]: 2 """ 3 Get embeddings using the Voyage AI API. 4 5 Args: 6 docs (List[str]): List of texts to embed 7 input_type (str): Type of input to embed. Can be "document" or "query". 8 model (str, optional): Model name. Defaults to "voyage-lite-02-instruct". 9 10 Returns: 11 List[List[float]]: Array of embedddings 12 """ 13 response = voyage_client.embed(docs, model=model, input_type=input_type) 14 return response.embeddings
The embedding function above takes a list of texts (
docs) and an input_type as arguments and returns a list of embeddings. The input_type can be document or query depending on whether we are embedding a list of documents or user queries. Voyage uses this value to prepend the inputs with special prompts to enhance retrieval quality.For text-embedding-3-large:
1 def get_embeddings(docs: List[str], model: str="text-embedding-3-large") -> List[List[float]]: 2 """ 3 Generate embeddings using the OpenAI API. 4 5 Args: 6 docs (List[str]): List of texts to embed 7 model (str, optional): Model name. Defaults to "text-embedding-3-large". 8 9 Returns: 10 List[float]: Array of embeddings 11 """ 12 # replace newlines, which can negatively affect performance. 13 docs = [doc.replace("\n", " ") for doc in docs] 14 response = openai_client.embeddings.create(input=docs, model=model) 15 response = [r.embedding for r in response.data] 16 return response
The embedding function for the OpenAI model is similar to the previous one, with some key differences — there is no
input_type argument, and the API returns a list of embedding objects, which need to be parsed to get the final list of embeddings. A sample response from the API looks as follows:1 { 2 "data": [ 3 { 4 "embedding": [ 5 0.018429679796099663, 6 -0.009457024745643139 7 . 8 . 9 . 10 ], 11 "index": 0, 12 "object": "embedding" 13 } 14 ], 15 "model": "text-embedding-3-large", 16 "object": "list", 17 "usage": { 18 "prompt_tokens": 183, 19 "total_tokens": 183 20 } 21 }
For UAE-large-V1:
1 from typing import List 2 from transformers import AutoModel, AutoTokenizer 3 import torch 4 5 # Instruction to append to user queries, to improve retrieval 6 RETRIEVAL_INSTRUCT = "Represent this sentence for searching relevant passages:" 7 8 # Check if CUDA (GPU support) is available, and set the device accordingly 9 device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu") 10 # Load the UAE-Large-V1 model from the Hugging Face 11 model = AutoModel.from_pretrained('WhereIsAI/UAE-Large-V1').to(device) 12 # Load the tokenizer associated with the UAE-Large-V1 model 13 tokenizer = AutoTokenizer.from_pretrained('WhereIsAI/UAE-Large-V1') 14 15 # Decorator to disable gradient calculations 16 @torch.no_grad() 17 def get_embeddings(docs: List[str], input_type: str) -> List[List[float]]: 18 """ 19 Get embeddings using the UAE-Large-V1 model. 20 21 Args: 22 docs (List[str]): List of texts to embed 23 input_type (str): Type of input to embed. Can be "document" or "query". 24 25 Returns: 26 List[List[float]]: Array of embedddings 27 """ 28 # Prepend retrieval instruction to queries 29 if input_type == "query": 30 docs = ["{}{}".format(RETRIEVAL_INSTRUCT, q) for q in docs] 31 # Tokenize input texts 32 inputs = tokenizer(docs, padding=True, truncation=True, return_tensors='pt', max_length=512).to(device) 33 # Pass tokenized inputs to the model, and obtain the last hidden state 34 last_hidden_state = model(**inputs, return_dict=True).last_hidden_state 35 # Extract embeddings from the last hidden state 36 embeddings = last_hidden_state[:, 0] 37 return embeddings.cpu().numpy()
The UAE-Large-V1 model is an open-source model available on Hugging Face Model Hub. First, we will need to download the model and its tokenizer from Hugging Face. We do this using the Auto classes — namely,
AutoModel and AutoTokenizer from the Transformers library — which automatically infers the underlying model architecture, in this case, BERT. Next, we load the model onto the GPU using .to(device) since we have one available.The embedding function for the UAE model, much like the Voyage model, takes a list of texts (
docs) and an input_type as arguments and returns a list of embeddings. A special prompt is prepended to queries for better retrieval as well.The input texts are first tokenized, which includes padding (for short sequences) and truncation (for long sequences) as needed to ensure that the length of inputs to the model is consistent — 512, in this case, defined by the
max_length parameter. The pt value for return_tensors indicates that the output of tokenization should be PyTorch tensors.The tokenized texts are then passed to the model for inference and the last hidden layer (
last_hidden_state) is extracted. This layer is the model’s final learned representation of the entire input sequence. The final embedding, however, is extracted only from the first token, which is often a special token ([CLS] in BERT) in transformer-based models. This token serves as an aggregate representation of the entire sequence due to the self-attention mechanism in transformers, where the representation of each token in a sequence is influenced by all other tokens. Finally, we move the embeddings back to CPU using .cpu() and convert the PyTorch tensors to numpy arrays using .numpy().As mentioned previously, we will evaluate the models based on embedding latency and retrieval quality.
To measure embedding latency, we will create a local vector store, which is essentially a list of embeddings for the entire dataset. Latency here is defined as the time it takes to create embeddings for the full dataset.
1 from tqdm.auto import tqdm 2 3 # Get all the texts in the dataset 4 texts = df["text"].tolist() 5 6 # Number of samples in a single batch 7 batch_size = 128 8 9 embeddings = [] 10 # Generate embeddings in batches 11 for i in tqdm(range(0, len(texts), batch_size)): 12 end = min(len(texts), i+batch_size) 13 batch = texts[i:end] 14 # Generate embeddings for current batch 15 batch_embeddings = get_embeddings(batch) 16 # Add to the list of embeddings 17 embeddings.extend(batch_embeddings)
We first create a list of all the texts we want to embed and set the batch size. The voyage-lite-02-instruct model has a batch size limit of 128, so we use the same for all models, for consistency. We iterate through the list of texts, grabbing
batch_size number of samples in each iteration, getting embeddings for the batch, and adding them to our "vector store".The time taken to generate embeddings on our hardware looked as follows:
| Model | Batch Size | Dimensions | Time |
|---|---|---|---|
| text-embedding-3-large | 128 | 3072 | 4m 17s |
| voyage-lite-02-instruct | 128 | 1024 | 11m 14s |
| UAE-large-V1 | 128 | 1024 | 19m 50s |
The OpenAI model has the lowest latency. However, note that it also has three times the number of embedding dimensions compared to the other two models. OpenAI also charges by tokens used, so both the storage and inference costs of this model can add up over time. While the UAE model is the slowest of the lot (despite running inference on a GPU), there is room for optimizations such as quantization, distillation, etc., since it is open-source.
To evaluate retrieval quality, we use a set of questions based on themes seen in our dataset. For real applications, however, you will want to curate a set of "cannot-miss" questions — i.e. questions that you would typically expect users to ask from your data. For this tutorial, we will qualitatively evaluate the relevance of retrieved documents as a measure of quality, but we will explore metrics and techniques for quantitative evaluations in a following tutorial.
Here are the main themes (generated using ChatGPT) covered by the top three documents retrieved by each model for our queries:
😐 denotes documents that we felt weren’t as relevant to the question. Sentences that contributed to this verdict have been highlighted in bold.
Query: Give me some tips to improve my mental health.
| voyage-lite-02-instruct | text-embedding-3-large | UAE-large-V1 |
|---|---|---|
| 😐 Regularly reassess treatment efficacy and modify plans as needed. Track mood, thoughts, and behaviors; share updates with therapists and support network. Use a multifaceted approach to manage suicidal thoughts, involving resources, skills, and connections. | Eat balanced, exercise, sleep well. Cultivate relationships, engage socially, set boundaries. Manage stress with effective coping mechanisms. | Prioritizing mental health is essential, not selfish. Practice mindfulness through meditation, journaling, and activities like yoga. Adopt healthy habits for better mood, less anxiety, and improved cognition. |
| Recognize early signs of stress, share concerns, and develop coping mechanisms. Combat isolation by nurturing relationships and engaging in social activities. Set boundaries, communicate openly, and seek professional help for social anxiety. | Prioritizing mental health is essential, not selfish. Practice mindfulness through meditation, journaling, and activities like yoga. Adopt healthy habits for better mood, less anxiety, and improved cognition. | Eat balanced, exercise regularly, get 7-9 hours of sleep. Cultivate positive relationships, nurture friendships, and seek new social opportunities. Manage stress with effective coping mechanisms. |
| Prioritizing mental health is essential, not selfish. Practice mindfulness through meditation, journaling, and activities like yoga. Adopt healthy habits for better mood, less anxiety, and improved cognition. | Acknowledging feelings is a step to address them. Engage in self-care activities to boost mood and health. Make self-care consistent for lasting benefits. | 😐 Taking care of your mental health is crucial for a fulfilling life, productivity, and strong relationships. Recognize the importance of mental health in all aspects of life. Managing mental health reduces the risk of severe psychological conditions. |
While the results cover similar themes, the Voyage AI model keys in heavily on seeking professional help, while the UAE model covers slightly more about why taking care of your mental health is important. The OpenAI model is the one that consistently retrieves documents that cover general tips for improving mental health.
Query: Give me some tips for writing good code.
| voyage-lite-02-instruct | text-embedding-3-large | UAE-large-V1 |
|---|---|---|
| Strive for clean, maintainable code with consistent conventions and version control. Utilize linters, static analyzers, and document work for quality and collaboration. Embrace best practices like SOLID and TDD to enhance design, scalability, and extensibility. | Strive for clean, maintainable code with consistent conventions and version control. Utilize linters, static analyzers, and document work for quality and collaboration. Embrace best practices like SOLID and TDD to enhance design, scalability, and extensibility. | Strive for clean, maintainable code with consistent conventions and version control. Utilize linters, static analyzers, and document work for quality and collaboration. Embrace best practices like SOLID and TDD to enhance design, scalability, and extensibility. |
| 😐 Code and test core gameplay mechanics like combat and quest systems; debug and refine for stability. Use modular coding, version control, and object-oriented principles for effective game development. Playtest frequently to find and fix bugs, seek feedback, and prioritize significant improvements. | 😐 Good programming needs dedication, persistence, and patience. Master core concepts, practice diligently, and engage with peers for improvement. Every expert was once a beginner—keep pushing forward. | Read programming books for comprehensive coverage and deep insights, choosing beginner-friendly texts with pathways to proficiency. Combine reading with coding to reinforce learning; take notes on critical points and unfamiliar terms. Engage with exercises and challenges in books to apply concepts and enhance skills. |
| 😐 Monitor social media and newsletters for current software testing insights. Participate in networks and forums to exchange knowledge with experienced testers. Regularly update your testing tools and methods for enhanced efficiency. | Apply learning by working on real projects, starting small and progressing to larger ones. Participate in open-source projects or develop your applications to enhance problem-solving. Master debugging with IDEs, print statements, and understanding common errors for productivity. | 😐 Programming is key in various industries, offering diverse opportunities. This guide covers programming fundamentals, best practices, and improvement strategies. Choose a programming language based on interests, goals, and resources. |
All the models seem to struggle a bit with this question. They all retrieve at least one document that is not as relevant to the question. However, it is interesting to note that all the models retrieve the same document as their number one.
Query: What are some environment-friendly practices I can incorporate in everyday life?
| voyage-lite-02-instruct | text-embedding-3-large | UAE-large-V1 |
|---|---|---|
| 😐 Conserve resources by reducing waste, reusing, and recycling, reflecting Jawa culture's values due to their planet's limited resources. Monitor consumption (e.g., water, electricity), repair goods, and join local environmental efforts. Eco-friendly practices enhance personal and global well-being, aligning with Jawa values. | Carry reusable bags for shopping, keeping extras in your car or bag. Choose sustainable alternatives like reusable water bottles and eco-friendly cutlery. Support businesses that minimize packaging and use biodegradable materials. | Educate others on eco-friendly practices; lead by example. Host workshops or discussion groups on sustainable living.Embody respect for the planet; every effort counts towards improvement. |
| Learn and follow local recycling rules, rinse containers, and educate others on proper recycling. Opt for green transportation like walking, cycling, or electric vehicles, and check for incentives. Upgrade to energy-efficient options like LED lights, seal drafts, and consider renewable energy sources. | Opt for sustainable transportation, energy-efficient appliances, solar panels, and eat less meat to reduce emissions. Conserve water by fixing leaks, taking shorter showers, and using low-flow fixtures. Water conservation protects ecosystems, ensures food security, and reduces infrastructure stress. | Carry reusable bags for shopping, keeping extras in your car or bag. Choose sustainable alternatives like reusable water bottles and eco-friendly cutlery. Support businesses that minimize packaging and use biodegradable materials. |
| 😐 Consistently implement these steps. Actively contribute to a cleaner, greener world. Support resilience for future generations. | Conserve water with low-flow fixtures, fix leaks, and use rainwater for gardening. Compost kitchen scraps to reduce waste and enrich soil, avoid meat and dairy. Shop locally at farmers markets and CSAs to lower emissions and support local economies. | Join local tree-planting events and volunteer at community gardens or restoration projects. Integrate native plants into landscaping to support pollinators and remove invasive species. Adopt eco-friendly transportation methods to decrease fossil fuel consumption. |
We see a similar trend with this query as with the previous two examples — the OpenAI model consistently retrieves documents that provide the most actionable tips, followed by the UAE model. The Voyage model provides more high-level advice.
Overall, based on our preliminary evaluation, OpenAI’s text-embedding-3-large model comes out on top. When working with real-world systems, however, a more rigorous evaluation of a larger dataset is recommended than what you'll get with text-embedding-3-large. Also, operational costs become an important factor and should be considered before proceeding with text-embedding-3-large. More on evaluation coming in Part 2 of this series!
In this tutorial, we looked into how to choose the best embedding model to embed data for RAG. The MTEB leaderboard is a good place to start, especially for text embedding models, but evaluating them on your data is important to find the best one for your RAG application. Storage and inference costs, embedding latency, and retrieval quality are all important parameters to consider while evaluating embedding models. The best embedding model is typically one that offers the biggest trade-off across these dimensions.
Now that you have a good understanding of embedding models, here are some resources to get started with building RAG applications using MongoDB:
Follow along with these by creating a free MongoDB Atlas cluster and reach out to us in our Generative AI community forums if you have any questions.
Top Comments in Forums
There are no comments on this article yet.
Rate this tutorial