Building Generative AI Applications Using MongoDB: Harnessing the Power of Atlas Vector Search and Open Source Models





Artificial intelligence is at the core of what's being heralded as the fourth industrial revolution. There is a fundamental change happening in the way we live and the way we work, and it's happening right now. While AI and its applications across businesses are not new, recently, generative AI has become a hot topic worldwide with the incredible success of ChatGPT, the popular chatbot from OpenAI. It reached 100 million monthly active users in two months, becoming the fastest-growing consumer application.
In this blog, we will talk about how you can leverage the power of large language models (LLMs), the transformative technology powering ChatGPT, on your private data to build transformative AI-powered applications using MongoDB and Atlas Vector Search. We will also walk through an example of building a semantic search using Python, machine learning models, and Atlas Vector Search for finding movies using natural language queries. For instance, to find “Funny movies with lead characters that are not human” would involve performing a semantic search that understands the meaning and intent behind the query to retrieve relevant movie recommendations, and not just the keywords present in the dataset.
Using vector embeddings, you can leverage the power of LLMs for use cases like semantic search, a recommendation system, anomaly detection, and a customer support chatbot that are grounded in your private data.
A vector is a list of floating point numbers (representing a point in an n-dimensional embedding space) and captures semantic information about the text it represents. For instance, an embedding for the string "MongoDB is awesome" using an open source LLM model called
all-MiniLM-L6-v2 would consist of 384 floating point numbers and look like this:1 [-0.018378766253590584, -0.004090079106390476, -0.05688102915883064, 0.04963553324341774, ….. 2 3 .... 4 0.08254531025886536, -0.07415960729122162, -0.007168072275817394, 0.0672200545668602]
Note: Later in the tutorial, we will cover the steps to obtain vector embeddings like this.
Vector search is a capability that allows you to find related objects that have a semantic similarity. This means searching for data based on meaning rather than the keywords present in the dataset.
Vector search uses machine learning models to transform unstructured data (like text, audio, and images) into numeric representation (called vector embeddings) that captures the intent and meaning of that data. Then, it finds related content by comparing the distances between these vector embeddings, using approximate k nearest neighbor (approximate KNN) algorithms. The most commonly used method for finding the distance between these vectors involves calculating the cosine similarity between two vectors.
Atlas Vector Search is a fully managed service that simplifies the process of effectively indexing high-dimensional vector data within MongoDB and being able to perform fast vector similarity searches. With Atlas Vector Search, you can use MongoDB as a standalone vector database for a new project or augment your existing MongoDB collections with vector search functionality.
Having a single solution that can take care of your operational application data as well as vector data eliminates the complexities of using a standalone system just for vector search functionality, such as data transfer and infrastructure management overhead. With Atlas Vector Search, you can use the powerful capabilities of vector search in any major public cloud (AWS, Azure, GCP) and achieve massive scalability and data security out of the box while being enterprise-ready with provisions like SoC2 compliance.
For this tutorial, we will be using a movie dataset containing over 23,000 documents in MongoDB. We will be using the
all-MiniLM-L6-v2 model from HuggingFace for generating the vector embedding during the index time as well as query time. But you can apply the same concepts by using a dataset and model of your own choice, as well. You will need a Python notebook or IDE, a MongoDB Atlas account, and a HuggingFace account for an hands-on experience.For a movie database, various kinds of content — such as the movie description, plot, genre, actors, user comments, and the movie poster — can be easily converted into vector embeddings. In a similar manner, the user query can be converted into vector embedding, and then the vector search can find the most relevant results by finding the nearest neighbors in the embedding space.
To create a MongoDB Atlas cluster, first, you need to create a MongoDB Atlas account if you don't already have one. Visit the MongoDB Atlas website and click on “Register.”
For this tutorial, we will be using the sample data pertaining to movies. The “sample_mflix” database contains a “movies” collection where each document contains fields like title, plot, genres, cast, directors, etc.
You can also connect to your own collection if you have your own data that you would like to use.
You can use an IDE of your choice or a Python notebook for following along. You will need to install the
pymongo package prior to executing this code, which can be done via pip install pymongo.1 import pymongo 2 3 client = pymongo.MongoClient("<Your MongoDB URI>") 4 db = client.sample_mflix 5 collection = db.movies
Note: In production environments, it is not recommended to hard code your database connection string in the way shown, but for the sake of a personal demo, it is okay.
You can check your dataset in the Atlas UI.
There are many options for creating embeddings, like calling a managed API, hosting your own model, or having the model run locally.
In this example, we will be using the HuggingFace inference API to use a model called all-MiniLM-L6-v2. HuggingFace is an open-source platform that provides tools for building, training, and deploying machine learning models. We are using them as they make it easy to use machine learning models via APIs and SDKs.
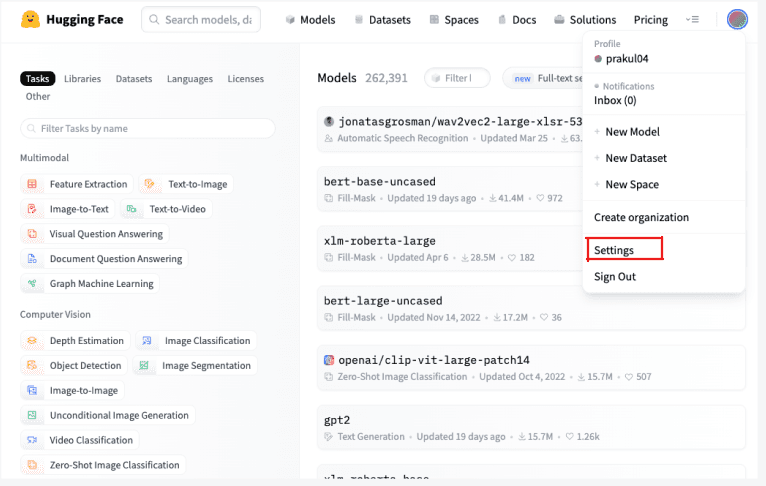
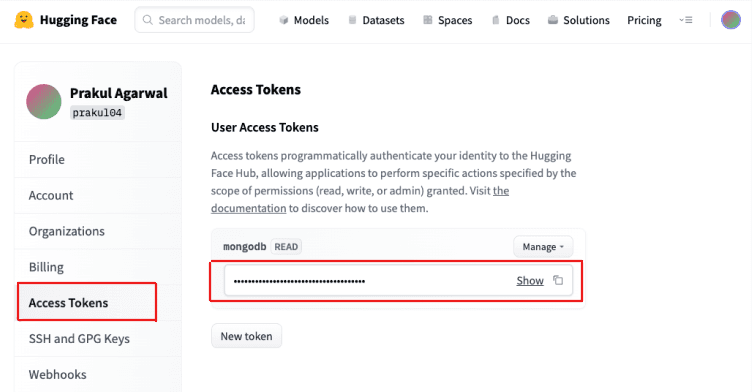
To use open-source models on Hugging Face, go to https://huggingface.co/. Create a new account if you don’t have one already. Then, to retrieve your Access token, go to Settings > “Access Tokens.” Once in the “Access Tokens” section, create a new token by clicking on “New Token” and give it a “read” right. Then, you can get the token to authenticate to the Hugging Face inference API:
You can now define a function that will be able to generate embeddings. Note that this is just a setup and we are not running anything yet.
1 import requests 2 3 hf_token = "<your_huggingface_token>" 4 embedding_url = "https://api-inference.huggingface.co/pipeline/feature-extraction/sentence-transformers/all-MiniLM-L6-v2" 5 6 def generate_embedding(text: str) -> list[float]: 7 8 response = requests.post( 9 embedding_url, 10 headers={"Authorization": f"Bearer {hf_token}"}, 11 json={"inputs": text}) 12 13 if response.status_code != 200: 14 raise ValueError(f"Request failed with status code {response.status_code}: {response.text}") 15 16 return response.json()
Now you can test out generating embeddings using the function we defined above.
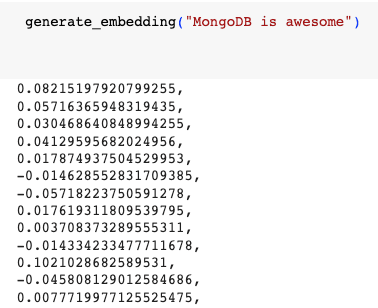
1 generate_embedding("MongoDB is awesome")
The output of this function will look like this:

Note: HuggingFace Inference API is free (to begin with) and is meant for quick prototyping with strict rate limits. You can consider setting up a paid “HuggingFace Inference Endpoints” using the steps described in the Bonus Suggestions. This will create a private deployment of the model for you.
Now, we will execute an operation to create a vector embedding for the data in the "plot" field in our movie documents and store it in the database. As described in the introduction, creating vector embeddings using a machine learning model is necessary for performing a similarity search based on intent.
In the code snippet below, we are creating vector embeddings for 50 documents in our dataset, that have the field “plot.” We will be storing the newly created vector embeddings in a field called "plot_embedding_hf," but you can name this anything you want.
When you are ready, you can execute the code below.
1 for doc in collection.find({'plot':{"$exists": True}}).limit(50): 2 doc['plot_embedding_hf'] = generate_embedding(doc['plot']) 3 collection.replace_one({'_id': doc['_id']}, doc)
Note: In this case, we are storing the vector embedding in the original collection (that is alongside the application data). This could also be done in a separate collection.
Once this step completes, you can verify in your database that a new field “plot_embedding_hf” has been created for some of the collections.
Note: We are restricting this to just 50 documents to avoid running into rate-limits on the HuggingFace inference API. If you want to do this over the entire dataset of 23,000 documents in our sample_mflix database, it will take a while, and you may need to create a paid “Inference Endpoint” as described in the optional setup above.
Now, we will head over to Atlas Search and create an index. First, click the “search” tab on your cluster and click on “Create Search Index.”
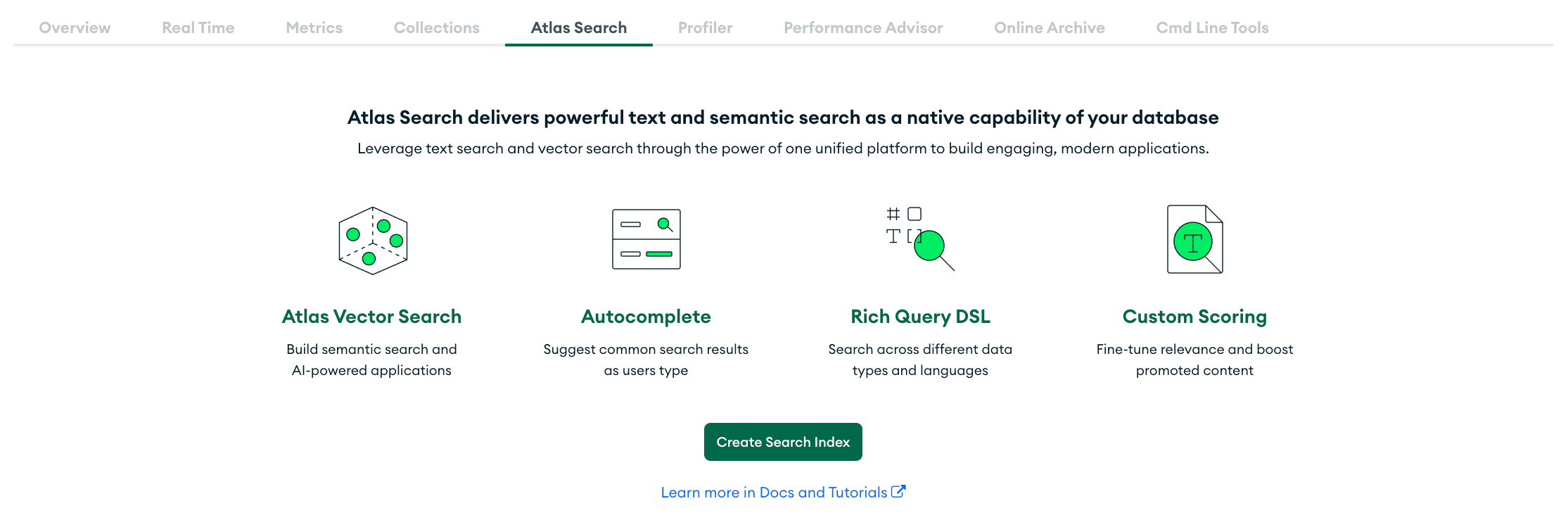
This will lead to the “Create a Search Index” configuration page. Select the “JSON Editor” and click “Next.”

Now, perform the following three steps on the "JSON Editor" page:
- Select the database and collection on the left. For this tutorial, it should be sample_mflix/movies.
- Enter the Index Name. For this tutorial, we are choosing to call it
PlotSemanticSearch. - Enter the configuration JSON (given below) into the text editor. The field name should match the name of the embedding field created in Step 3 (for this tutorial it should be
plot_embedding_hf), and the dimensions match those of the chosen model (for this tutorial it should be 384). The chosen value for the "similarity" field (of “dotProduct”) represents cosine similarity, in our case.
For a description of the other fields in this configuration, you can check out our Vector Search documentation.
Then, click “Next” and click “Create Search Index” button on the review page.
1 { 2 "type": "vectorSearch, 3 "fields": [{ 4 "path": "plot_embedding_hf", 5 "dimensions": 384, 6 "similarity": "dotProduct", 7 "type": "vector" 8 }] 9 }

Once the index is created, you can query it using the “$vectorSearch” stage in the MQL workflow.
Support for the '$vectorSearch' aggregation pipeline stage is available with MongoDB Atlas 6.0.11 and 7.0.2.
In the query below, we will search for four recommendations of movies whose plots matches the intent behind the query “imaginary characters from outer space at war”.
Execute the Python code block described below, in your chosen IDE or notebook.
1 query = "imaginary characters from outer space at war" 2 3 results = collection.aggregate([ 4 {"$vectorSearch": { 5 "queryVector": generate_embedding(query), 6 "path": "plot_embedding_hf", 7 "numCandidates": 100, 8 "limit": 4, 9 "index": "PlotSemanticSearch", 10 }} 11 }); 12 13 for document in results: 14 print(f'Movie Name: {document["title"]},\nMovie Plot: {document["plot"]}\n')
The output will look like this:

Note: To find out more about the various parameters (like ‘$vectorSearch’, ‘numCandidates’, and ‘k’), you can check out the Atlas Vector Search documentation.
This will return the movies whose plots most closely match the intent behind the query “imaginary characters from outer space at war.”
Note: As you can see, the results above need to be more accurate since we only embedded 50 movie documents. If the entire movie dataset of 23,000+ documents were embedded, the query “imaginary characters from outer space at war” would result in the below. The formatted results below show the title, plot, and rendering of the image for the movie poster.

In this tutorial, we demonstrated how to use HuggingFace Inference APIs, how to generate embeddings, and how to use Atlas Vector search. We also learned how to build a semantic search application to find movies whose plots most closely matched the intent behind a natural language query, rather than searching based on the existing keywords in the dataset. We also demonstrated how efficient it is to bring the power of machine learning models to your data using the Atlas Developer Data Platform.
If you prefer learning by watching, check out the video version of this article!
“HuggingFace Inference Endpoints” is the recommended way to easily create a private deployment of the model and use it for production use case. As we discussed before ‘HuggingFace Inference API’ is meant for quick prototyping and has strict rate limits.
To create an ‘Inference Endpoint’ for a model on HuggingFace, follow these steps:
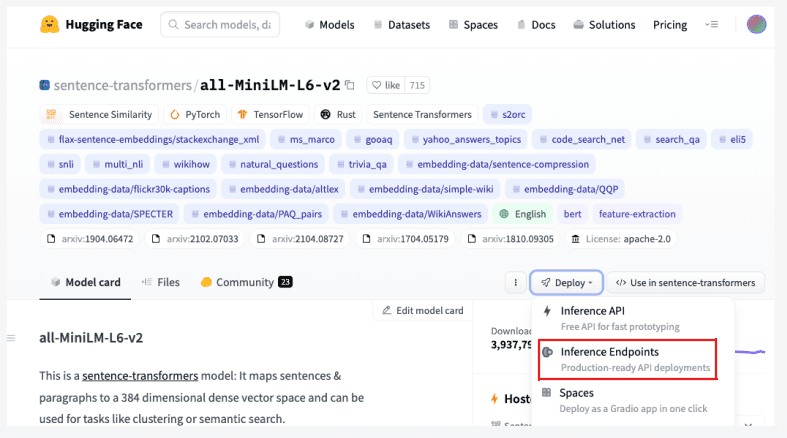
- Select the Cloud Provider of choice and the instance type on the "Create a new Endpoint" page. For this tutorial, you can choose the default of AWS and Instance type of CPU [small]. This would cost about $0.06/hour.

- Now click on the "Advanced configuration" and choose the task type to "Sentence Embedding." This configuration is necessary to ensure that the endpoint returns the response from the model that is suitable for the embedding creation task.
[Optional] you can set the “Automatic Scale-to-Zero” to “After 15 minutes with no activity” to ensure your endpoint is paused after a period of inactivity and you are not charged. Setting this configuration will, however, mean that the endpoint will be unresponsive after it’s been paused. It will take some time to return online after you send requests to it again.
- After this, you can click on “Create endpoint" and you can see the status as "Initializing."
- Use the following Python function to generate embeddings. Notice the difference in response format from the previous usage of “HuggingFace Inference API.”
1 import requests 2 3 hf_token = "<your_huggingface_token>" 4 embedding_url = "<Your Inference Endpoint URL>" 5 6 def generate_embedding(text: str) -> list[float]: 7 8 response = requests.post( 9 embedding_url, 10 headers={"Authorization": f"Bearer {hf_token}"}, 11 json={"inputs": text}) 12 13 if response.status_code != 200: 14 raise ValueError(f"Request failed with status code {response.status_code}: {response.text}") 15 16 return response.json()["embeddings"]
To use OpenAI for embedding generation, you can use the package (install using
pip install openai).You’ll need your OpenAI API key, which you can create on their website. Click on the account icon on the top right and select “View API keys” from the dropdown. Then, from the API keys, click on "Create new secret key."
To generate the embeddings in Python, install the openAI package (
pip install openai) and use the following code.1 openai.api_key = os.getenv("OPENAI_API_KEY") 2 3 model = "text-embedding-ada-002" 4 5 def generate_embedding(text: str) -> list[float]: 6 resp = openai.Embedding.create( 7 input=[text], 8 model=model) 9 10 return resp["data"][0]["embedding"]
You can use Azure OpenAI endpoints by creating a deployment in your Azure account and using:
1 def generate_embedding(text: str) -> list[float]: 2 3 embeddings = 4 resp = openai.Embedding.create 5 (deployment_id=deployment_id, 6 input=[text]) 7 8 return resp["data"][0]["embedding"]
Models have a limitation on the number of input tokens that they can handle. The limitation for OpenAI's
text-embedding-ada-002 model is 8,192 tokens. Splitting the original text into smaller chunks becomes necessary when creating embeddings for the data that exceeds the model's limit.Get started by creating a MongoDB Atlas account if you don't already have one. Just click on “Register.” MongoDB offers a free-forever Atlas cluster in the public cloud service of your choice.
To learn more about Atlas Vector Search, visit the product page or the documentation for creating a vector search index or running vector search queries.

