AWS Glue Visual ETL for Your Data in MongoDB Atlas



Venkatesh Shanbhag, Igor Alekseev, Anuj Panchal3 min read • Published Nov 22, 2024 • Updated Nov 22, 2024




.png&w=3840&q=75)
Rate this tutorial


AWS Glue is a serverless data integration service. It simplifies data processing for customers. Migrating data between MongoDB Atlas and AWS becomes efficient with AWS Glue's visual ETL (Extract, Transform, and Load) capabilities. The visual interface and built-in features allow data extraction and insertion to and from MongoDB Atlas collections, with optional transformations, before loading it to the target location. This serverless and scalable approach ensures cost-effective data movement while maintaining security through IAM roles. In this post, we will go through a visual approach to utilize MongoDB Atlas and AWS Glue for building pipelines between the two platforms.
To follow this post and test out AWS Glue’s capabilities with MongoDB Atlas, we need an AWS account and a subscription to MongoDB Atlas. You can subscribe to MongoDB Atlas from the AWS marketplace.
The post describes a process for transferring data between MongoDB Atlas and AWS S3 using AWS Glue's visual ETL capabilities. These capabilities allow developers to create ETL pipelines without the knowledge of Spark or SQL by leveraging AWS Glue Studio. This post highlights the benefits of using AWS Glue for data transformation and integration with other AWS services. AWS S3—being highly scalable, durable, and cost-effective object storage—can be used as data lakes, a data warehousing solution, machine learning, media streaming, backup and recovery, and web hosting.
- Configure PrivateLink by following the steps described in Connecting Applications Securely to a MongoDB Atlas Data Plane with AWS PrivateLink. With AWS PrivateLink, we will simplify our networking architecture and make sure the traffic stays on the AWS network.
- To obtain your MongoDB cluster connection string from the Connect UI on the MongoDB Atlas console, navigate to your Atlas home screen and click on Connect for the AWS cluster you want to connect. Select the Private Endpoint and Connection Method.
- Copy the SRV connection string. We use this SRV connection string in the subsequent steps.
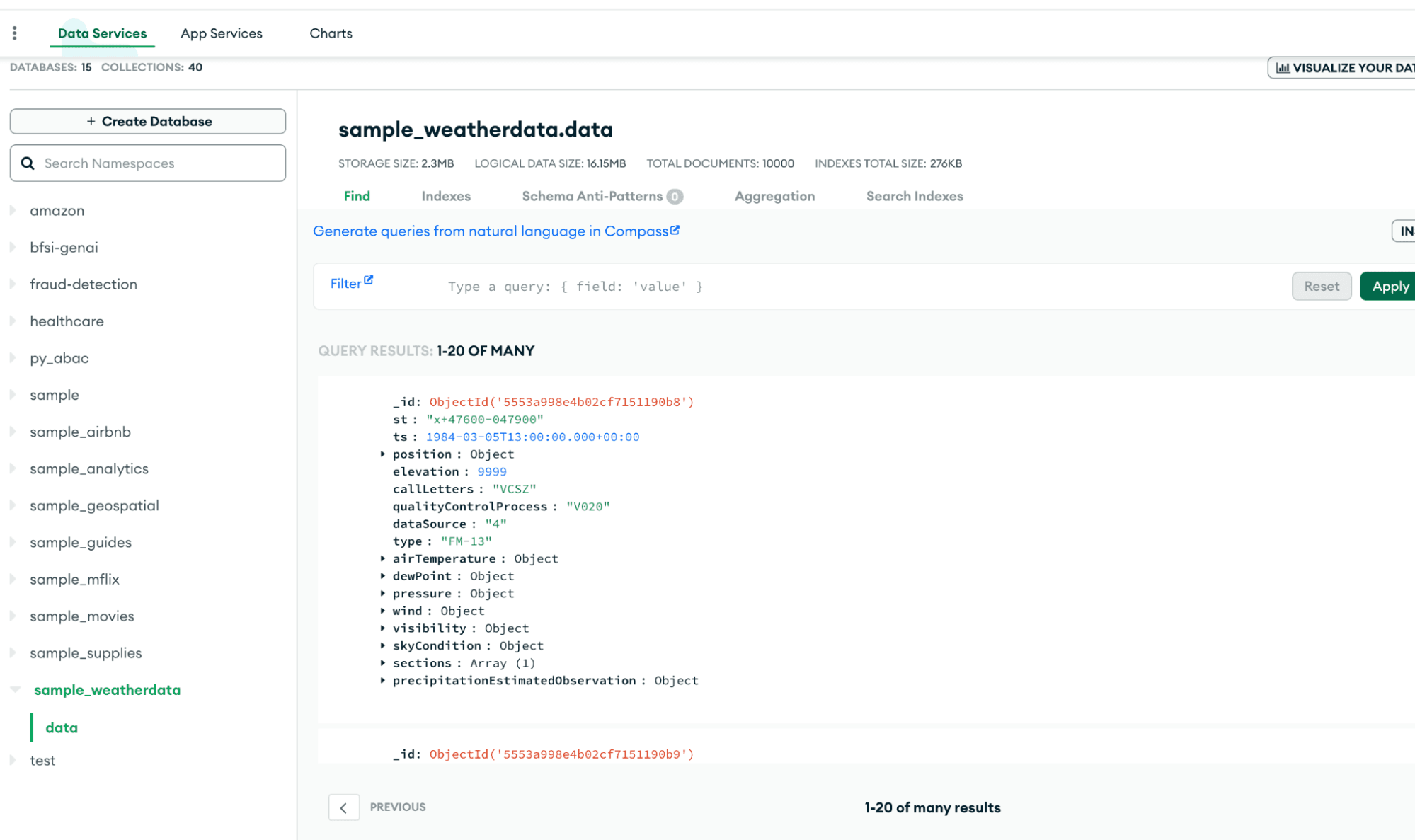
The following screenshot shows that we have loaded a sample collection (in this case, sample weather data) in MongoDB Atlas, which we will connect to in the next steps. Note: The records in this collection include several arrays as well as nested data.
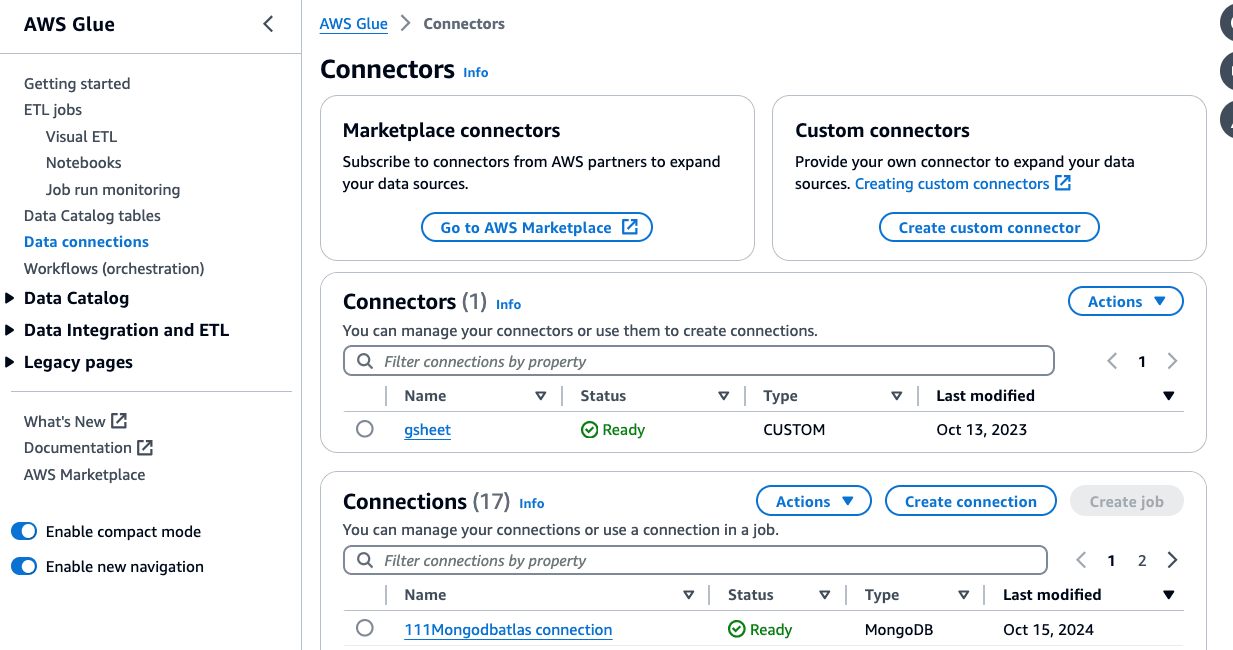
Before we can configure the AWS Glue crawler, we need to create the MongoDB Atlas connection in AWS Glue.
- On the AWS Glue Studio console, choose Connectors in the navigation pane.
- Choose Create connection.
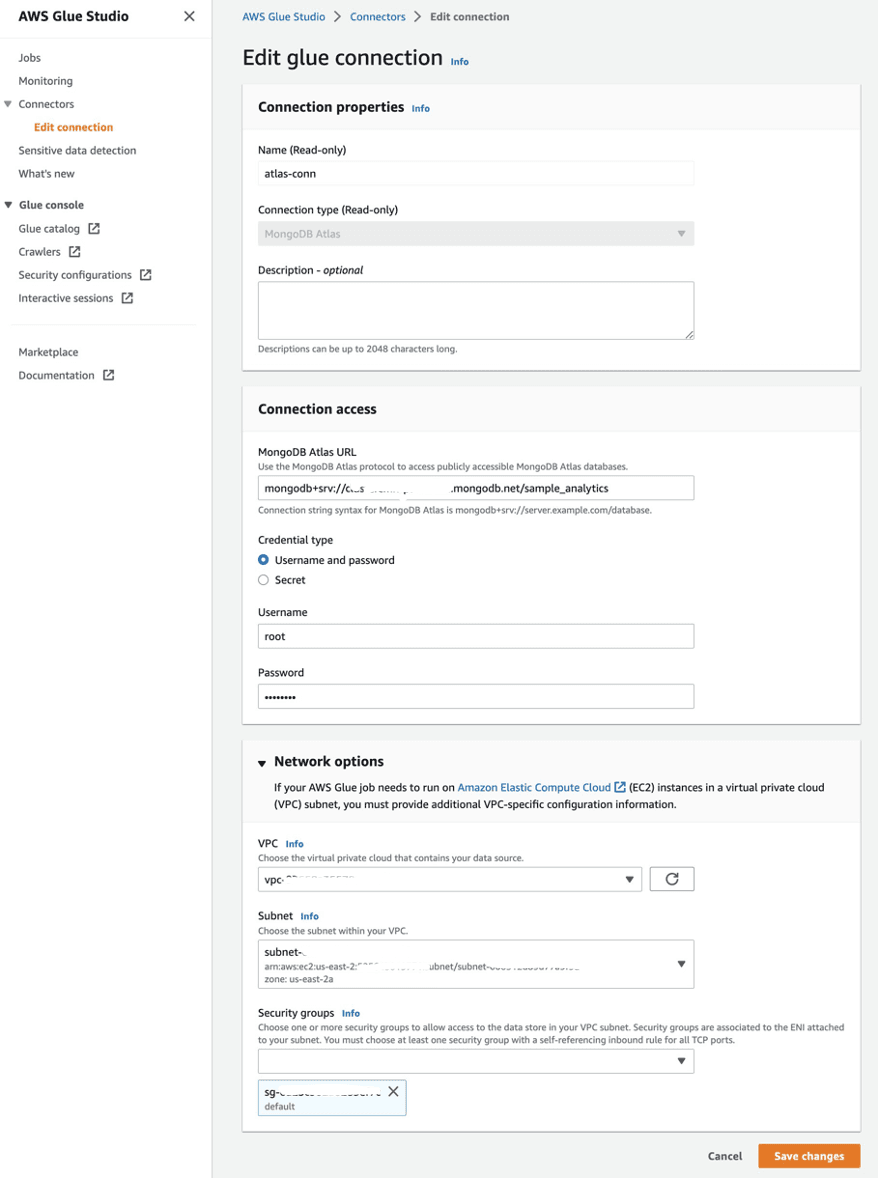
- When filling out the connection details, use the SRV connection string we obtained earlier in MongoDB Atlas.
- In the Network options section, add the VPC and subnet. Important: The VPC and the subnet must correspond to the PrivateLink settings you configured earlier.
Once the connection is configured, Navigate to the Glue | ETL jobs | Visual ETL to create the ETL job.
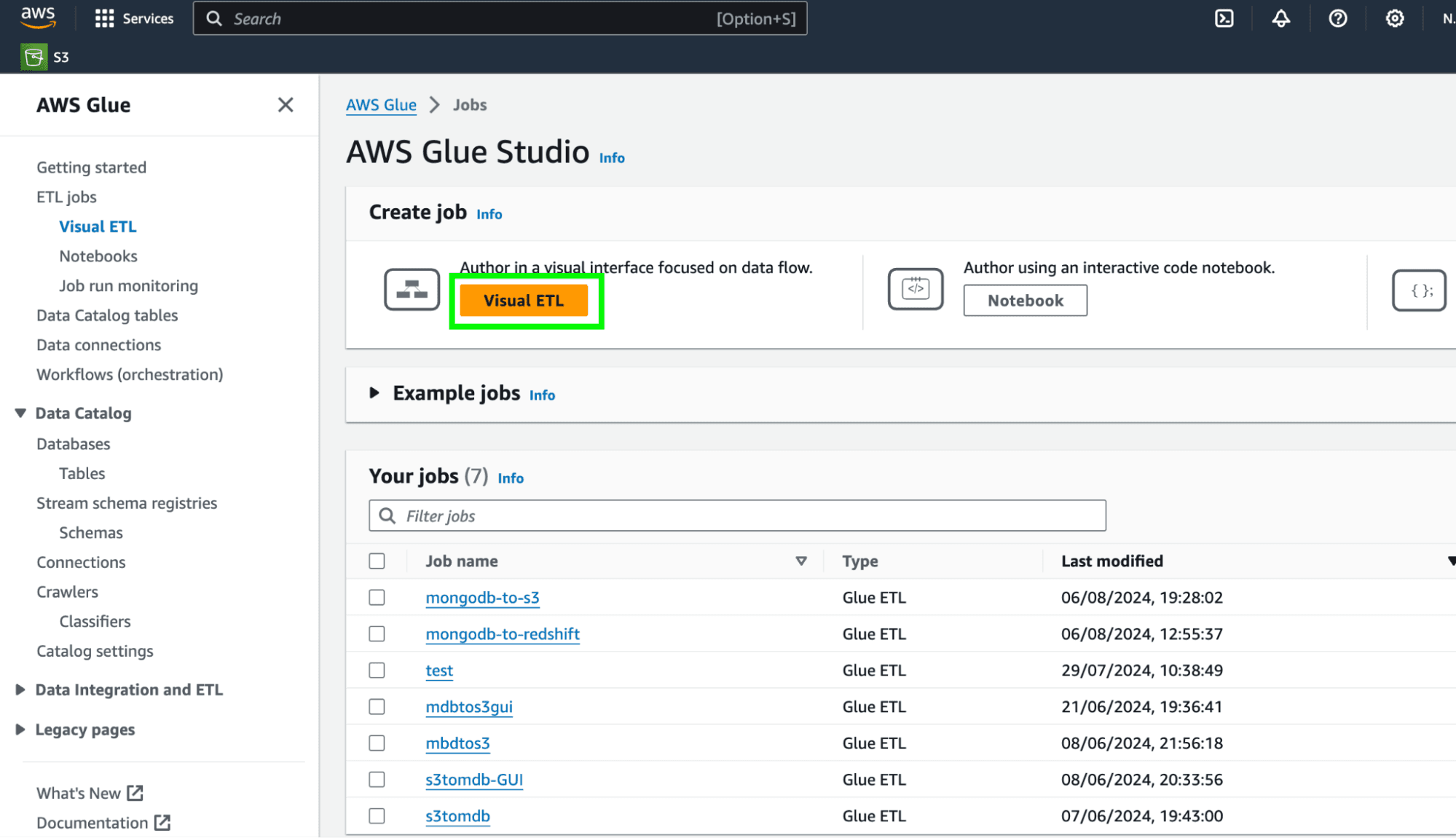
To open the Glue visual editor, either click on Visual ETL or Author and edit ETL jobs, and then click on visual ETL on the next screen.
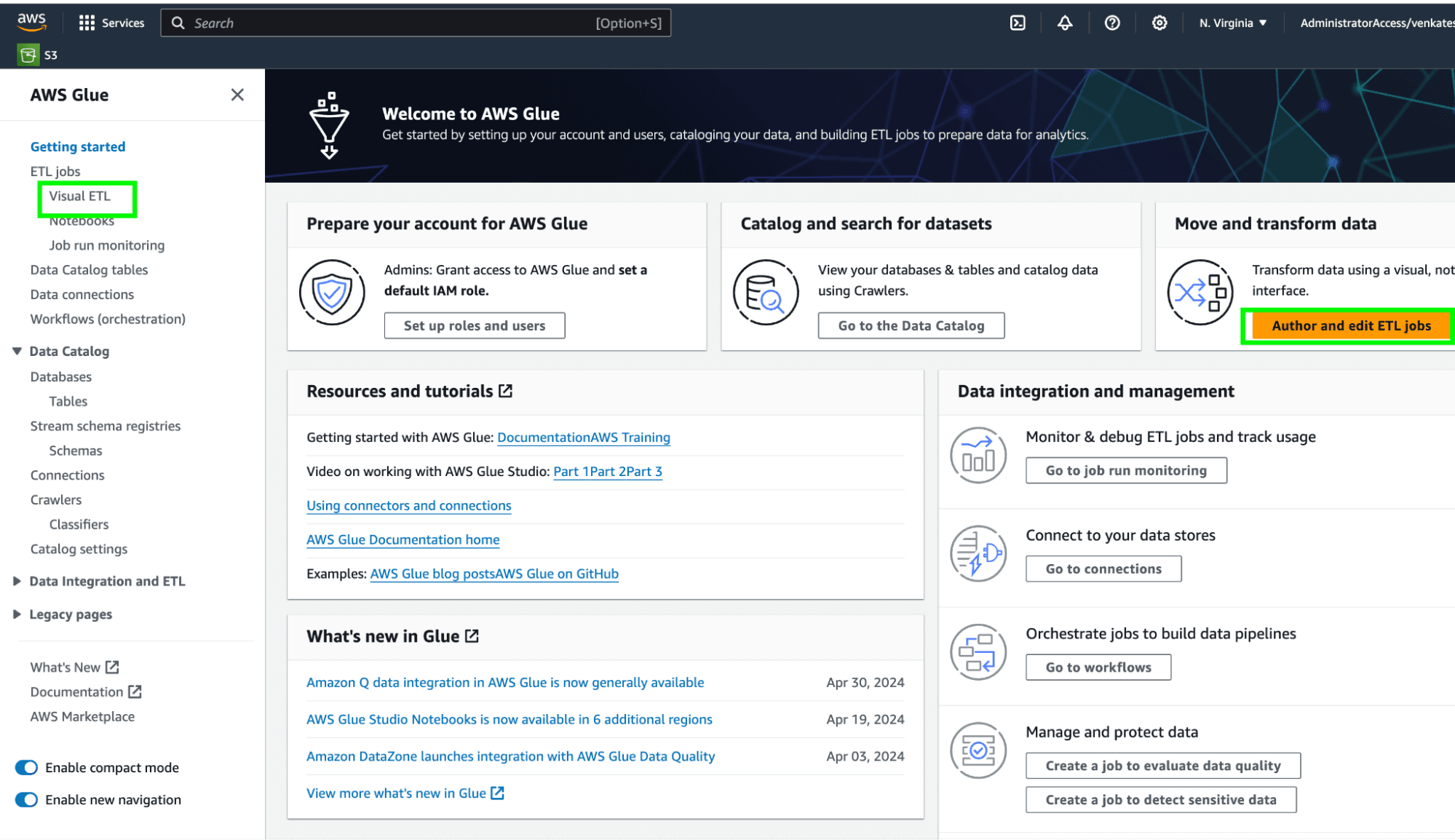
If you have saved jobs, you can access them from the AWS Glue studio, as well.
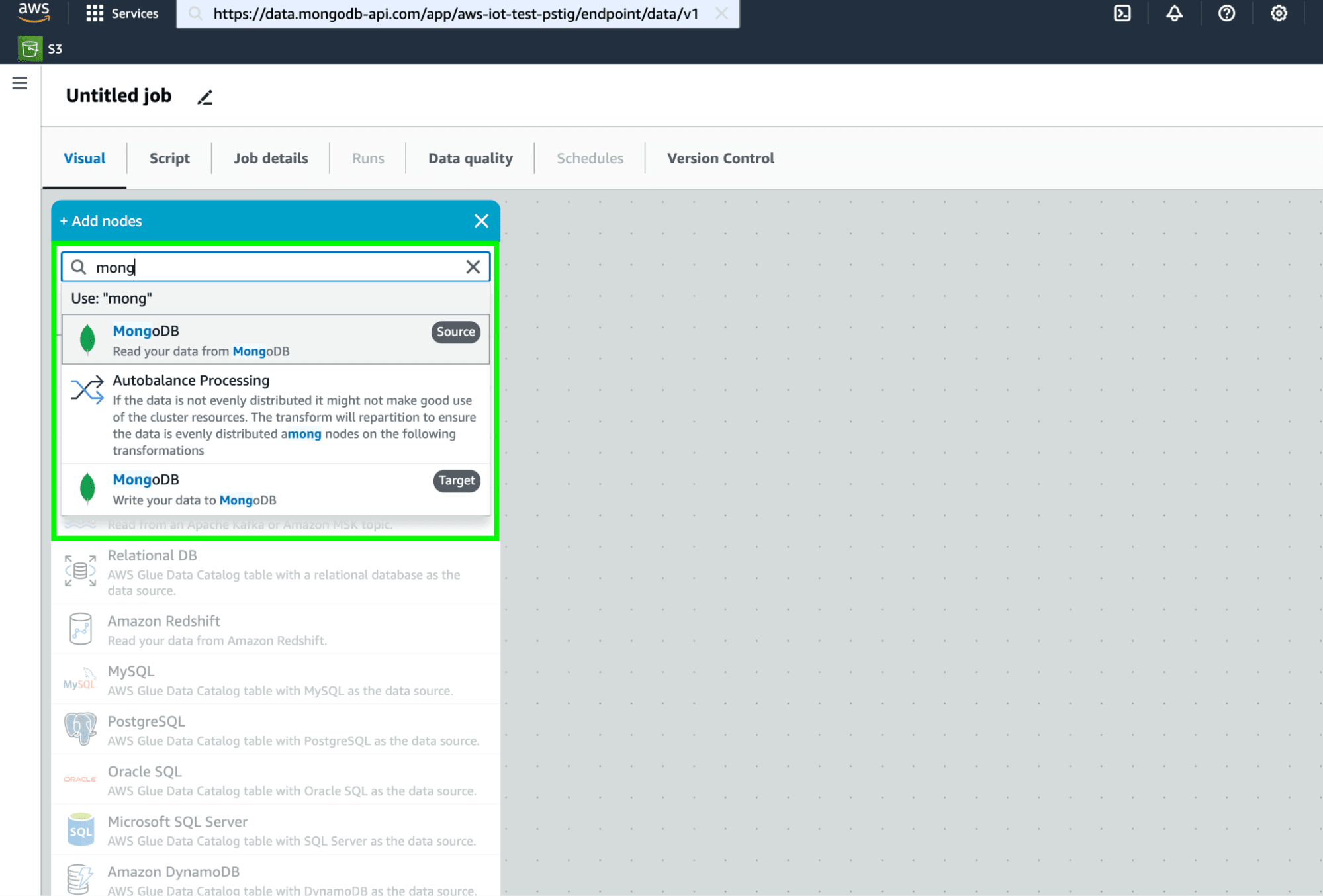
Click on (+) on the home screen of the Glue visual editor to add nodes. Search for MongoDB and select MongoDB as the source to read from the previously created connection.
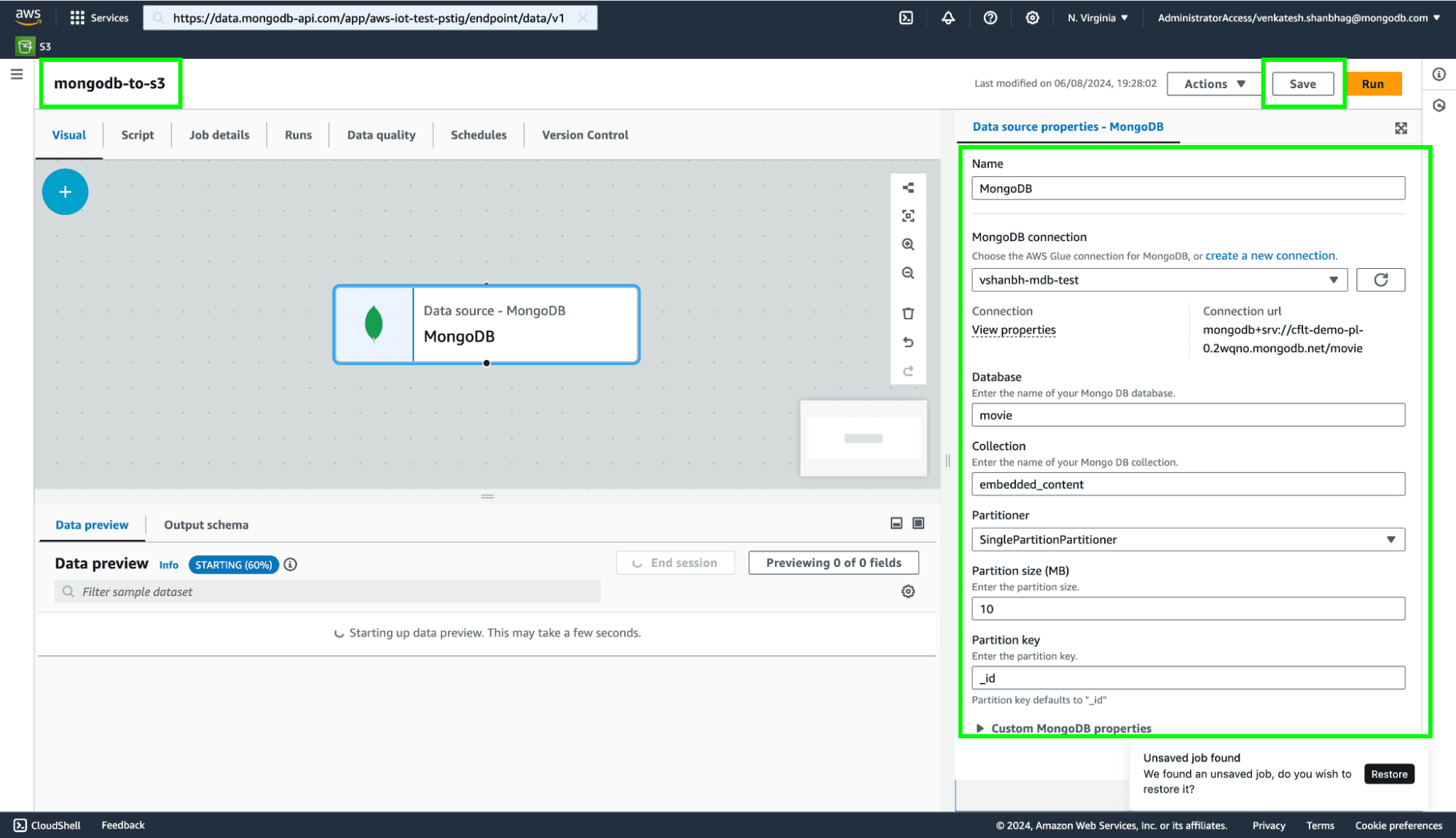
Select the MongoDB connection and provide the database and collection name. Save the pipeline.
Click on (+) to add one more node and search for S3. Select Amazon S3 as Target. Select MongoDB as Node parent.
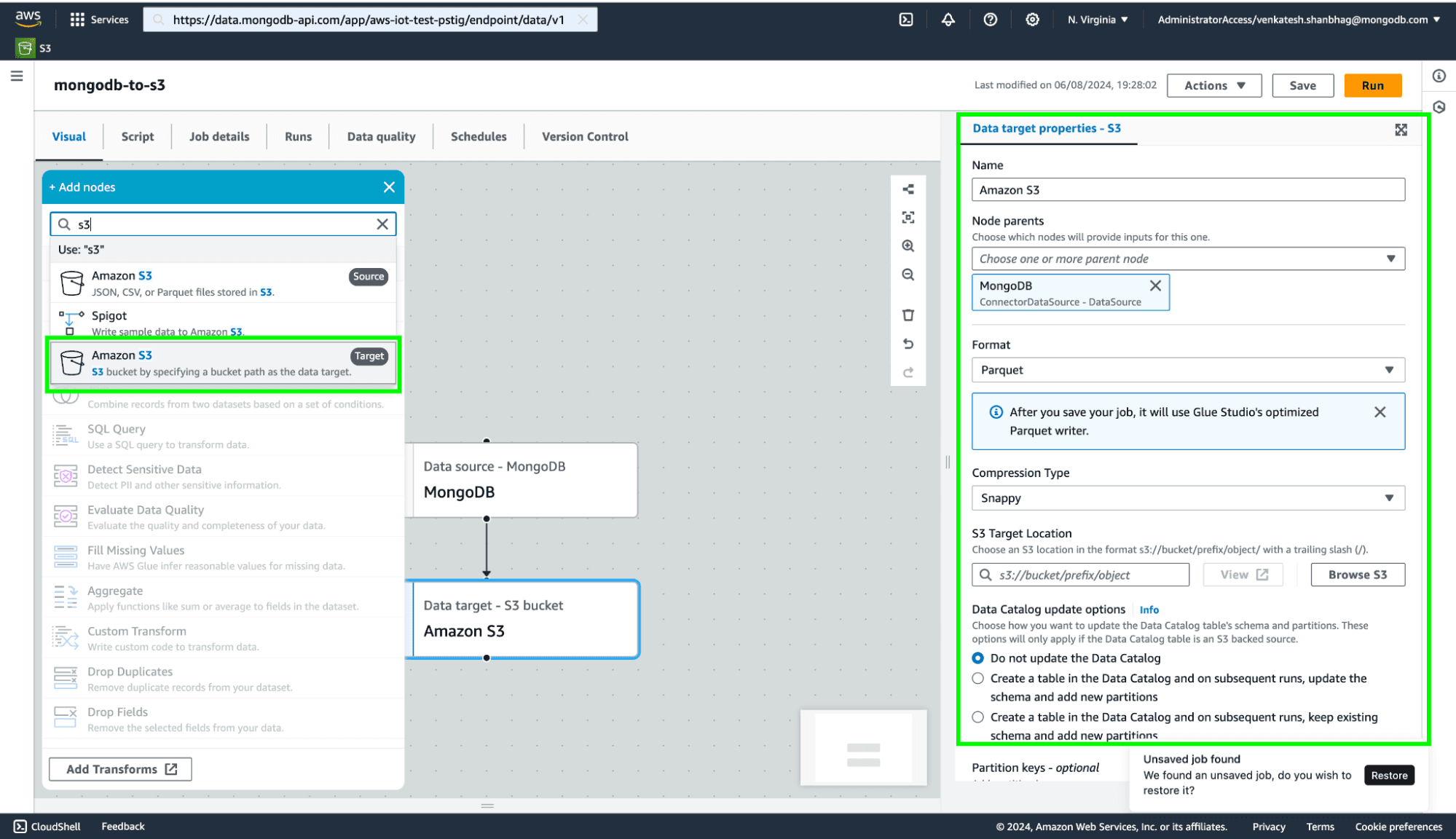
Select the data format for your destination data file. Select the S3 bucket where you want to write the data and click on Save.
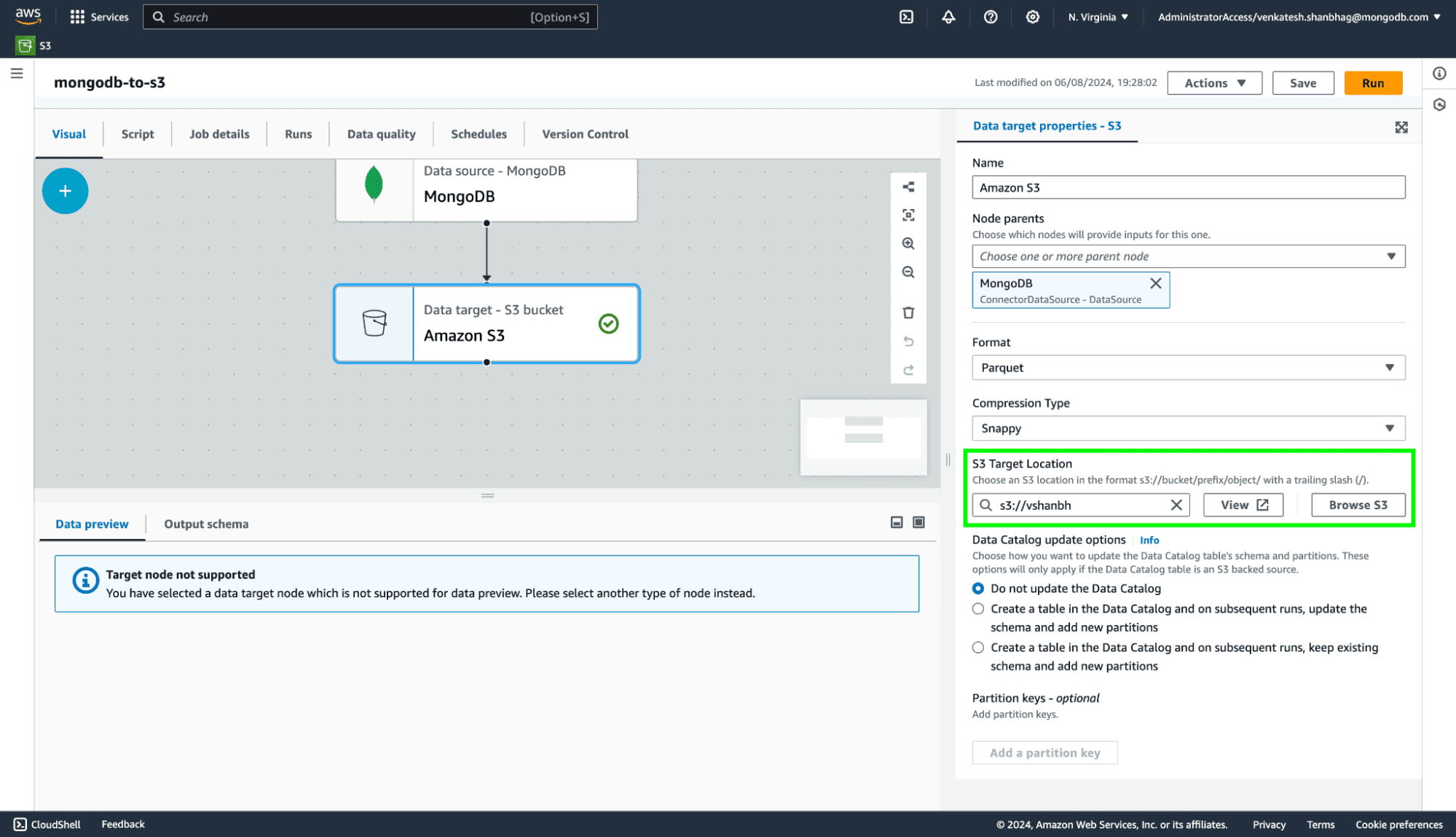
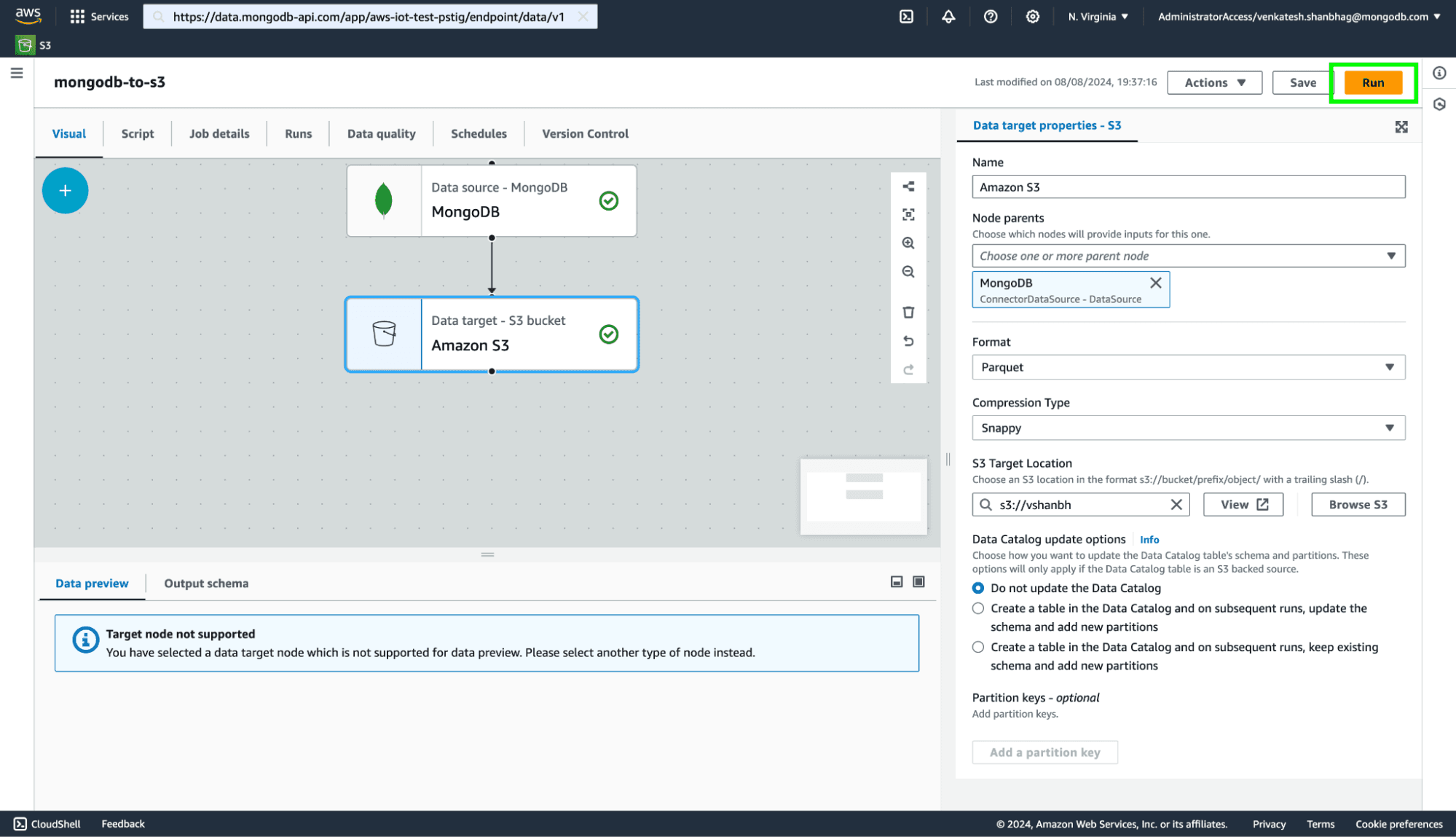
Run the job by clicking the button in the top right corner.
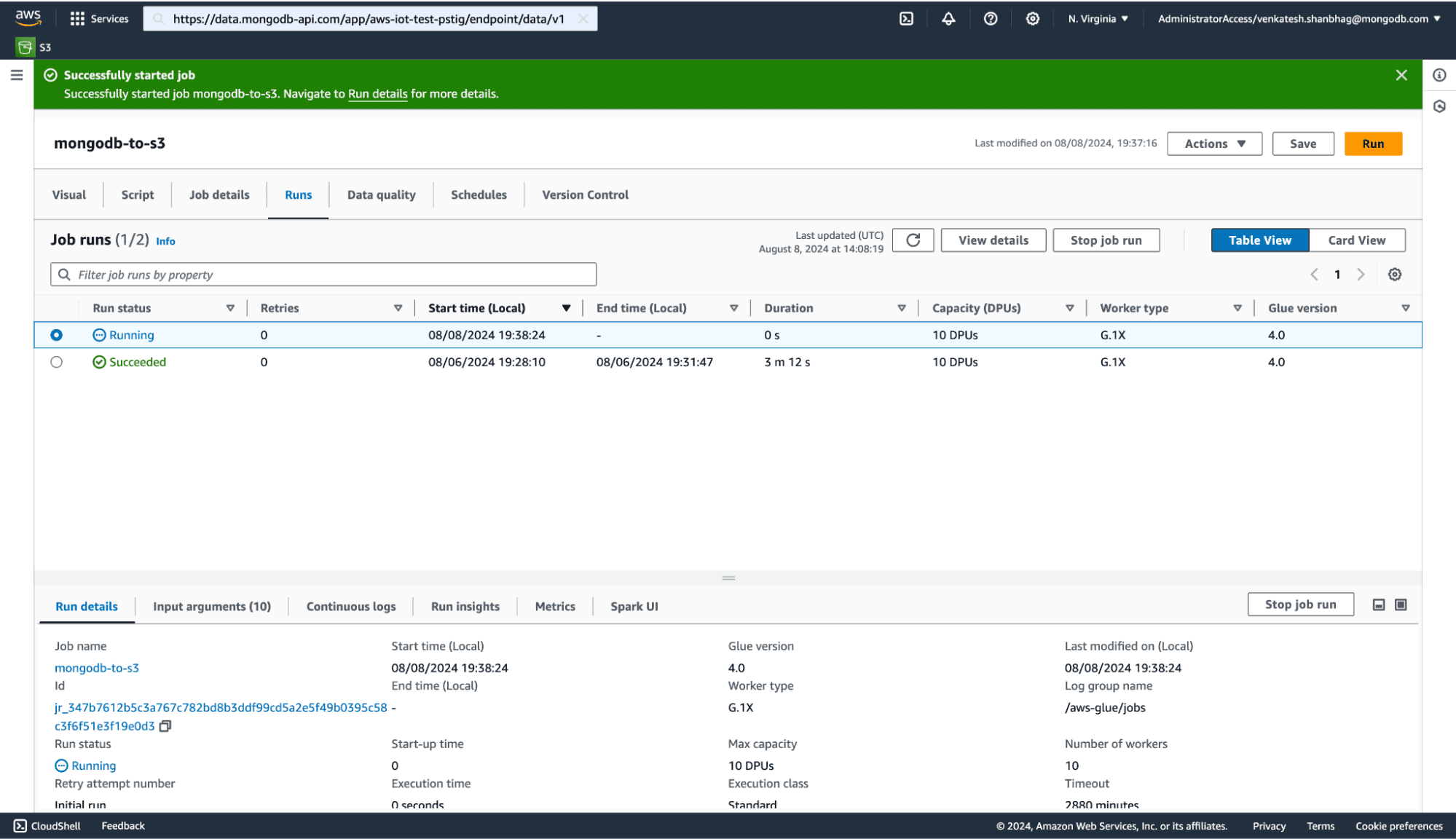
The job will take a few minutes to complete. You can monitor your job on the Runs tab, as shown below.
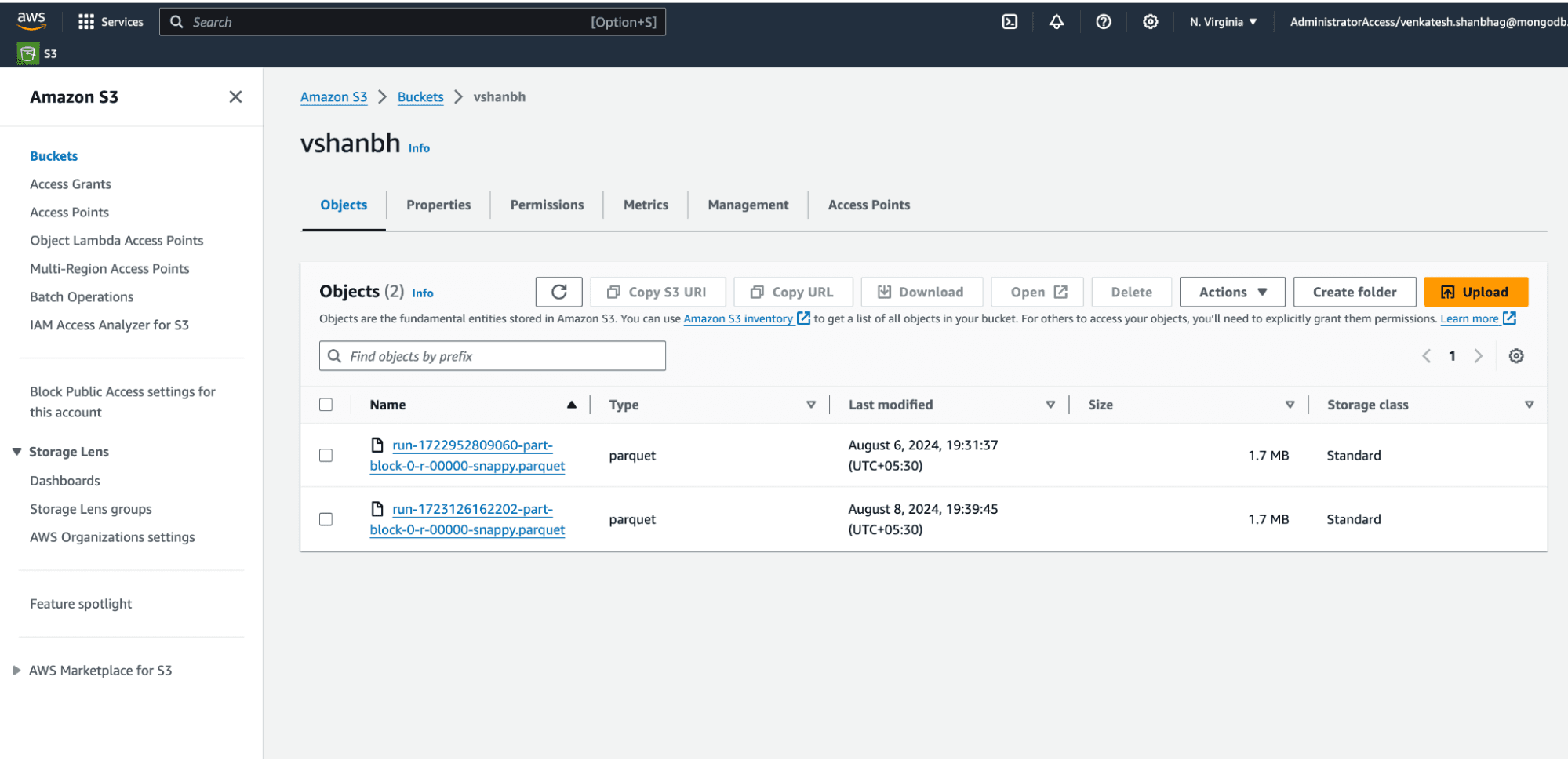
You can verify your data written to S3 by navigating to your S3 bucket.
Watch this Video to see the steps in action
AWS Glue Visual ETL simplifies creating and managing data transformations, allowing developers to create ETL pipelines without the specialized knowledge of data engineering tools. It offers connectors to numerous third-party and AWS-native products and services. This enables you to enrich data from various sources for analysis in data warehousing, while building efficient pipelines effortlessly with Glue Visual ETL. For advanced data transformations involving MongoDB Atlas, refer to the AWS Glue documentation.
Top Comments in Forums
There are no comments on this article yet.