Building AI Applications with Microsoft Semantic Kernel and MongoDB Atlas Vector Search



Anaiya Raisinghani, Prakul Agarwal, Tim Kelly8 min read • Published Nov 27, 2023 • Updated Nov 27, 2023





Rate this tutorial


We are excited to announce native support for MongoDB Atlas Vector Search in Microsoft Semantic Kernel. With this integration, users can bring the power of LLMs (large language models) to their proprietary data securely, and build generative AI applications using RAG (retrieval-augmented generation) with programming languages like Python and C#. The accompanying tutorial will walk you through an example.
Semantic Kernel is a polyglot, open-source SDK that lets users combine various AI services with their applications. Semantic Kernel uses connectors to allow you to swap out AI services without rewriting code. Components of Semantic Kernel include:
- AI services: Supports AI services like OpenAI, Azure OpenAI, and Hugging Face.
- Programming languages: Supports conventional programming languages like C# Python, and Java.
- Large language model (LLM) prompts: Supports the latest in LLM AI prompts with prompt templating, chaining, and planning capabilities.
- Memory: Provides different vectorized stores for storing data, including MongoDB.
MongoDB Atlas Vector Search is a fully managed service that simplifies the process of effectively indexing high-dimensional vector embedding data within MongoDB and being able to perform fast vector similarity searches.
Embedding refers to the representation of words, phrases, or other entities as dense vectors in a continuous vector space. It's designed to ensure that words with similar meanings are grouped closer together. This method helps computer models better understand and process language by recognizing patterns and relationships between words and is what allows us to search by semantic meaning.
When data is converted into numeric vector embeddings using encoding models, these embeddings can be stored directly alongside their respective source data within the MongoDB database. This co-location of vector embeddings and the original data not only enhances the efficiency of queries but also eliminates potential synchronization issues. By avoiding the need to maintain separate databases or synchronization processes for the source data and its embeddings, MongoDB provides a seamless and integrated data retrieval experience.
This consolidated approach streamlines database management and allows for intuitive and sophisticated semantic searches, making the integration of AI-powered experiences easier.
This combination enables developers to build AI-powered intelligent applications using MongoDB Atlas Vector Search and large language models from providers like OpenAI, Azure OpenAI, and Hugging Face.
Despite all their incredible capabilities, LLMs have a knowledge cutoff date and often need to be augmented with proprietary, up-to-date information for the particular business that an application is being built for. This “long-term memory for LLM” capability for AI-powered intelligent applications is typically powered by leveraging vector embeddings. Semantic Kernel allows for storing and retrieving this vector context for AI apps using the memory plugin (which now has support for MongoDB Atlas Vector Search).
Atlas Vector Search is integrated in this tutorial to provide a way to interact with our memory store that was created through our MongoDB and Semantic Kernel connector.
This tutorial takes you through how to use Microsoft Semantic Kernel to properly upload and embed documents into your MongoDB Atlas cluster, and then conduct queries using Microsoft Semantic Kernel as well, all in Python!
- IDE of your choice (this tutorial uses Google Colab — please refer to it if you’d like to run the commands directly)
Let’s get started!
Visit the MongoDB Atlas dashboard and set up your cluster. In order to take advantage of the
$vectorSearch operator in an aggregation pipeline, you need to run MongoDB Atlas 6.0.11 or higher. This tutorial can be built using a free cluster.When you’re setting up your deployment, you’ll be prompted to set up a database user and rules for your network connection. Please ensure you save your username and password somewhere safe and have the correct IP address rules in place so your cluster can connect properly.
In order to be successful with our tutorial, let’s ensure we have the most up-to-date version of Semantic Kernel installed in our IDE. As of the creation of this tutorial, the latest version is 0.3.14. Please run this
pip command in your IDE to get started:1 !python -m pip install semantic-kernel==0.3.14.dev
Once it has been successfully run, you will see various packages being downloaded. Please ensure
pymongo is downloaded in this list.Here, include the information about our OpenAI API key and our connection string.
Let’s set up the necessary imports:
1 import openai 2 import semantic_kernel as sk 3 from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion, OpenAITextEmbedding 4 from semantic_kernel.connectors.memory.mongodb_atlas import MongoDBAtlasMemoryStore 5 6 7 8 kernel = sk.Kernel() 9 10 11 openai.api_key = '<your-openai-key' 12 MONGODB_SEARCH_INDEX="defaultRandomFacts" 13 MONGODB_DATABASE="semantic-kernel" 14 MONGODB_COLLECTION="randomFacts" 15 16 17 kernel.add_chat_service("chat-gpt", OpenAIChatCompletion("gpt-3.5-turbo", openai.api_key)) 18 kernel.add_text_embedding_generation_service("ada", OpenAITextEmbedding("text-embedding-ada-002", openai.api_key)) 19 20 21 kernel.register_memory_store(memory_store=MongoDBAtlasMemoryStore(index_name=MONGODB_SEARCH_INDEX, database_name=MONGODB_DATABASE, connection_string="<mongodb-uri>")) 22 kernel.import_skill(sk.core_skills.TextMemorySkill())
Importing in OpenAI is crucial because we are using their data model to embed not only our documents but also our queries. We also want to import their Text Embedding library for this same reason. For this tutorial, we are using the embedding model
ada-002, but please double check that you’re using a model that is compatible with your OpenAI API key.Our
MongoDBAtlasMemoryStore class is very important as it’s the part that enables us to use MongoDB as our memory store. This means we can connect to the Semantic Kernel and have our documents properly saved and formatted in our cluster. For more information on this class, please refer to the repository.This is also where you will need to incorporate your OpenAI API key along with your MongoDB connection string, and other important variables that we will use. The ones above are just a suggestion, but if they are changed while attempting the tutorial, please ensure they are consistent throughout. For help on accessing your OpenAI key, please read the section below.
In order to generate our embeddings, we will use the OpenAI API. First, we’ll need a secret key. To create your OpenAI key, you'll need to create an account. Once you have that, visit the OpenAI API and you should be greeted with a screen like the one below. Click on your profile icon in the top right of the screen to get the dropdown menu and select “View API keys”.
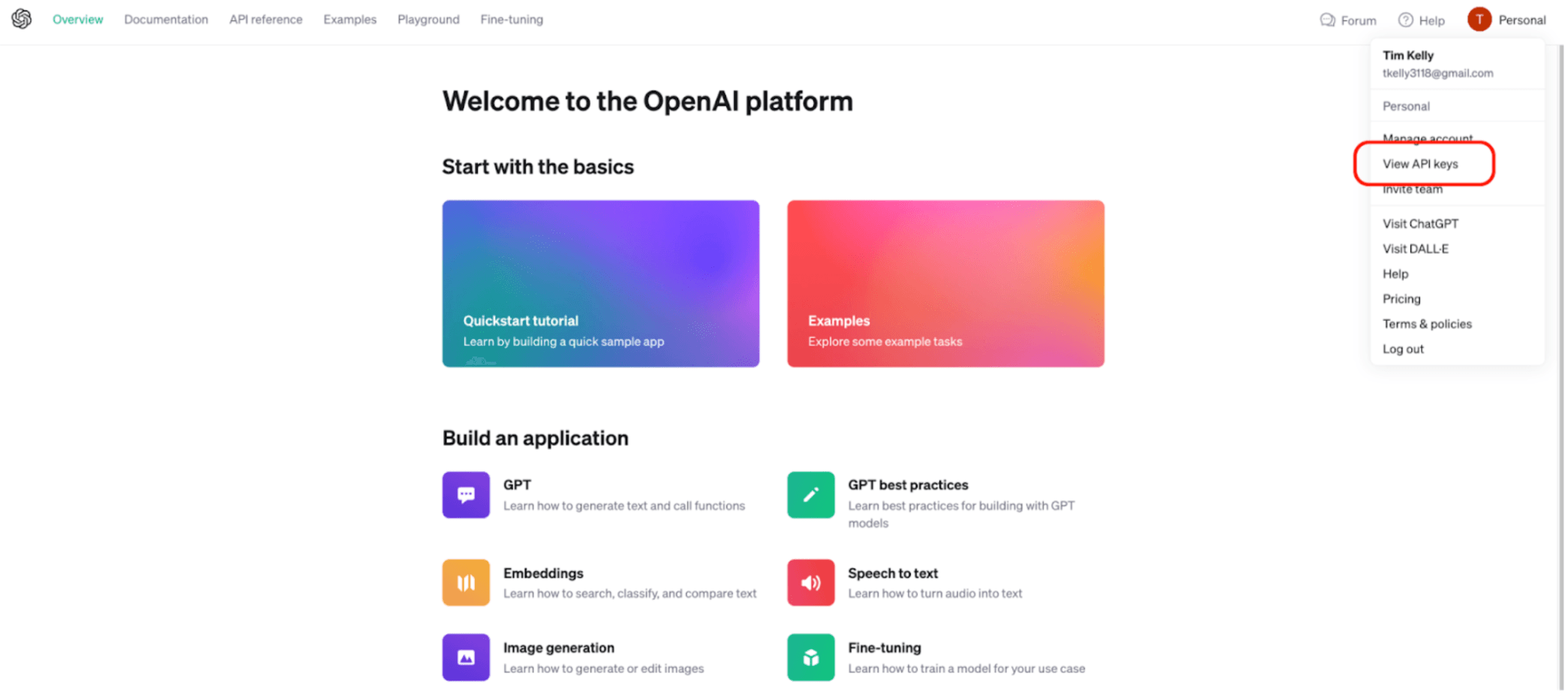
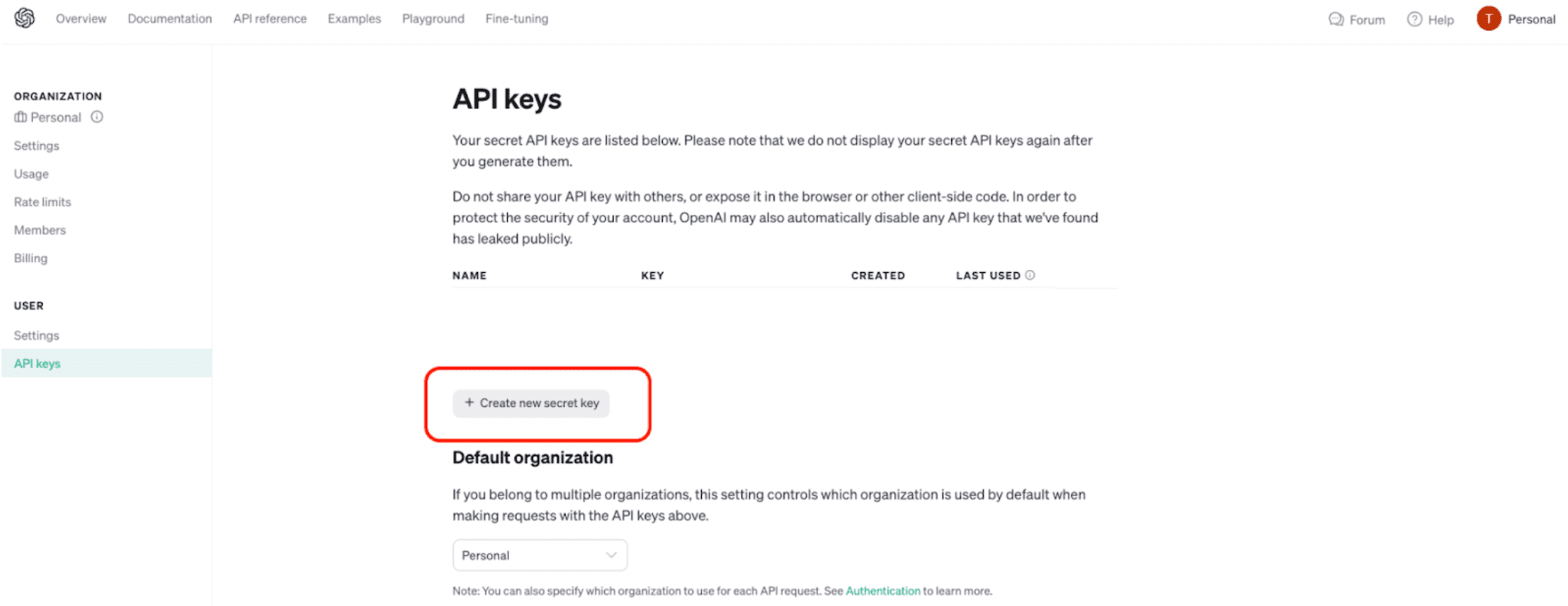
Here, you can generate your own API key by clicking the “Create new secret key” button. Give it a name and store it somewhere safe. This is all you need from OpenAI to use their API to generate your embeddings.
Retrieval-augmented regeneration, also known as RAG, is an NLP technique that can help improve the quality of large language models (LLMs). It’s an artificial intelligence framework for getting data from an external knowledge source. The memory store we are creating using Microsoft Semantic Kernel is an example of this. But why is RAG necessary? Let’s take a look at an example.
LLMs like OpenAI GPT-3.5 exhibit an impressive and wide range of skills. They are trained on the data available on the internet about a wide range of topics and can answer queries accurately. Using Semantic Kernel, let’s ask OpenAI’s LLM if Albert Einstein likes coffee:
1 # Wrap your prompt in a function 2 prompt = kernel.create_semantic_function(""" 3 As a friendly AI Copilot, answer the question: Did Albert Einstein like coffee? 4 """) 5 6 7 print(prompt())
The output received is:
1 Yes, Albert Einstein was known to enjoy coffee. He was often seen with a cup of coffee in his hand and would frequently visit cafes to discuss scientific ideas with his colleagues over a cup of coffee.
Since this information was available on the public internet, the LLM was able to provide the correct answer.
But LLMs have their limitations: They have a knowledge cutoff (September 2021, in the case of OpenAI) and do not know about proprietary and personal data. They also have a tendency to hallucinate — that is, they may confidently make up facts and provide answers that may seem to be accurate but are actually incorrect. Here is an example to demonstrate this knowledge gap:
1 prompt = kernel.create_semantic_function(""" 2 As a friendly AI Copilot, answer the question: Did I like coffee? 3 """) 4 5 6 print(prompt())
The output received is:
1 As an AI, I don't have personal preferences or experiences, so I can't say whether "I" liked coffee or not. However, coffee is a popular beverage enjoyed by many people around the world. It has a distinct taste and aroma that some people find appealing, while others may not enjoy it as much. Ultimately, whether someone likes coffee or not is a subjective matter and varies from person to person.
As you can see, there is a knowledge gap here because we don’t have our personal data loaded in OpenAI that our query can access. So let’s change that. Continue on through the tutorial to learn how to augment the knowledge base of the LLM with proprietary data.
Once we have incorporated our MongoDB connection string and our OpenAI API key, we are ready to add some documents into our MongoDB cluster.
Please ensure you’re specifying the proper collection variable below that we set up above.
1 async def populate_memory(kernel: sk.Kernel) -> None: 2 # Add some documents to the semantic memory 3 await kernel.memory.save_information_async( 4 collection=MONGODB_COLLECTION, id="1", text="We enjoy coffee and Starbucks" 5 ) 6 await kernel.memory.save_information_async( 7 collection=MONGODB_COLLECTION, id="2", text="We are Associate Developer Advocates at MongoDB" 8 ) 9 await kernel.memory.save_information_async( 10 collection=MONGODB_COLLECTION, id="3", text="We have great coworkers and we love our teams!" 11 ) 12 await kernel.memory.save_information_async( 13 collection=MONGODB_COLLECTION, id="4", text="Our names are Anaiya and Tim" 14 ) 15 await kernel.memory.save_information_async( 16 collection=MONGODB_COLLECTION, id="5", text="We have been to New York City and Dublin" 17 )
Here, we are using the
populate_memory function to define five documents with various facts about Anaiya and Tim. As you can see, the name of our collection is called “randomFacts”, we have specified the ID for each document (please ensure each ID is unique, otherwise you will get an error), and then we have included a text phrase we want to embed.Once you have successfully filled in your information and have run this command, let’s add them to our cluster — aka let’s populate our memory! To do this, please run the command:
1 print("Populating memory...aka adding in documents") 2 await populate_memory(kernel)
Once this command has been successfully run, you should see the database, collection, documents, and their embeddings populate in your Atlas cluster. The screenshot below shows how the first document looks after running these commands.

Once the documents added to our memory have their embeddings, let’s set up our search index and ensure we can generate embeddings for our queries.
In order to use the 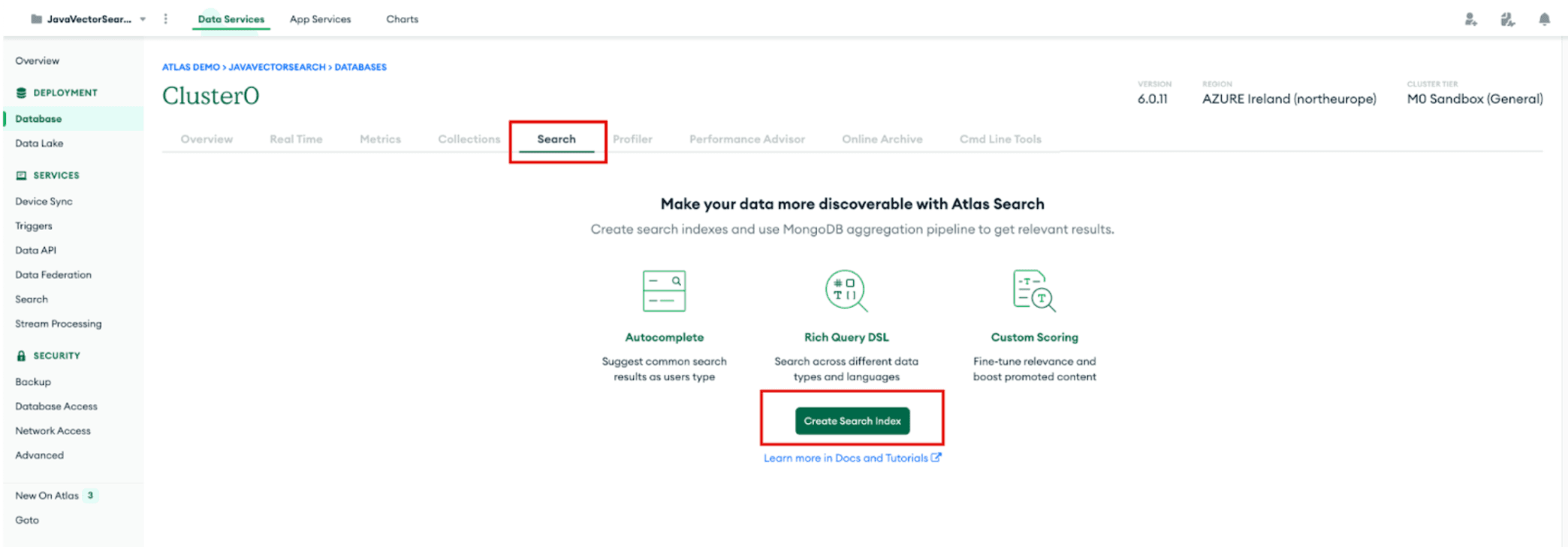
$vectorSearch operator on our data, we need to set up an appropriate search index. We’ll do this in the Atlas UI. Select the “Search" tab on your cluster and click “Create Search Index”.
We want to choose the "JSON Editor Option" and click "Next".
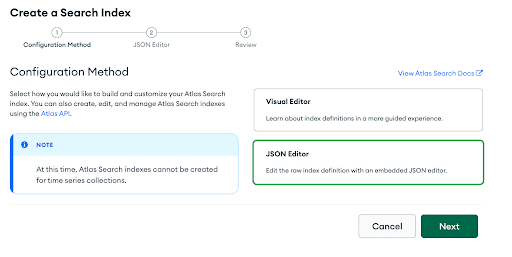
On this page, we're going to select our target database,
semantic-kernel, and collection, randomFacts.For this tutorial, we are naming our index
defaultRandomFacts. The index will look like this:1 { 2 "mappings": { 3 "dynamic": true, 4 "fields": { 5 "embedding": { 6 "dimensions": 1536, 7 "similarity": "dotProduct", 8 "type": "knnVector" 9 } 10 } 11 } 12 }
The fields specify the embedding field name in our documents,
embedding, the dimensions of the model used to embed, 1536, and the similarity function to use to find K-nearest neighbors, dotProduct. It's very important that the dimensions in the index match that of the model used for embedding. This data has been embedded using the same model as the one we'll be using, but other models are available and may use different dimensions.In order to query your new documents hosted in your MongoDB cluster “memory” store, we can use the
memory.search_async function. Run the following commands and watch the magic happen:1 result = await kernel.memory.search_async(MONGODB_COLLECTION, 'What is my job title?') 2 3 4 print(f"Retrieved document: {result[0].text}, {result[0].relevance}")
Now you can ask any question and get an accurate response!
Examples of questions asked and the results:



In this tutorial, you have learned a lot of very useful concepts:
- What Microsoft Semantic Kernel is and why it’s important.
- How to connect Microsoft Semantic Kernel to a MongoDB Atlas cluster.
- How to add in documents to your MongoDB memory store (and embed them, in the process, through Microsoft Semantic Kernel).
- How to query your new documents in your memory store using Microsoft Semantic Kernel.
For more information on MongoDB Vector Search, please visit the documentation, and for more information on Microsoft Semantic Kernel, please visit their repository and resources.
Rate this tutorial