Given the ever-increasing big data assets organizations possess, and the rapidly increasing demands for optimized data analytics productivity and efficiency by organizational stakeholders, it's not surprising that data lakes are a key growth enabler across all industries. And, with the transition of data lakes from primarily solution-based resources to service-and-solution-based resources, data scientists, engineers, and other STEM professionals are gaining access to data lakes in greater numbers than ever before.
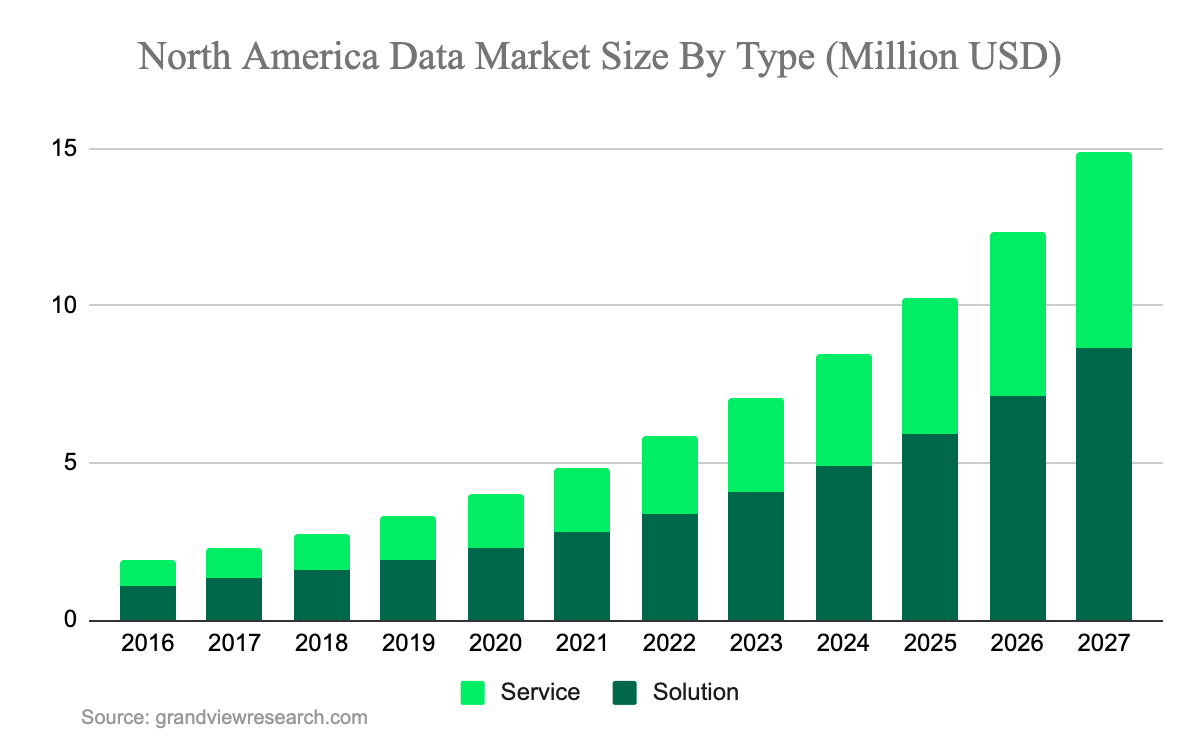
(Source: Grand View Research, 2023)
The ability of data lakes to ingest huge amounts of structured data, semi-structured data, and unstructured data, as well as their growing role in fueling machine learning and advanced data science, are just some of the reasons that the data lake market is anticipated to grow at a compound annual growth rate (CAGR) of 20.6% from 2020 to 2027.
With all that said, how can businesses and STEM professionals alike leverage data lakes in their day-to-day activities and take advantage of the many benefits cloud data lakes provide? Read on to learn what data lakes are, how they are used, the differences between a data lake vs a data warehouse, and how to choose the right data lake solution or service for your organization.
What is a data lake?
A data lake is simply a centralized repository to store vast amounts of data in its original (raw data) format. This means that data ingestion into a data lake is possible without any type of preformatting required. It also means that a variety of structured data, semi-structured data, and unstructured data types (e.g., relational files, text files, PDFs, audio files, JSON documents) can also be stored in the same data lake.
Data lake characteristics
In addition to this data format agnosticism, some additional characteristics of data lakes include:
- Multiple data sources: Data lakes can easily ingest a variety of data types from a variety of data sources.

Bulk loading: Rather than loading data incrementally, or serially, many data lakes are able to bulk load vast amounts of data, which not only speeds up the ingestion process but also improves performance.
Store now, analyze later: Data lakes are primarily concerned with storing data in its native format for future data discovery and business intelligence purposes. This means that the assignment of data hierarchy and labeling that usually accompanies data ingestion in a data warehouse doesn't take place initially in a data lake. However, to avoid creating a data swamp (e.g., where users have no visibility into the types of data within the data lake), data is stored in a flat, non-hierarchical format as objects with metadata that users can access at a later date. Avoiding the creation of a data swamp is also important so that appropriate data security can be maintained in the data lake as well.
Schema flexibility: Data lake storage systems are able to infer the schemas from previously ingested data stored within the data lake. This is sometimes referred to as schema-on-read. This differs significantly from how data warehouses ingest data into a predefined format and hierarchy, sometimes referred to as schema-on-write.
Data lake architecture
Contrary to the predefined nature of data warehouse architecture and associated platforms, data lake architecture can be described as an architecture pattern, or set of tools (supporting the schema-on-read approach), surrounding a vast repository of native-format data. As such, data lake architecture often varies from organization to organization depending on their specific data usage and analytics needs.
The data repository
Data lakes have three basic elements relating to their data repository which include:
Data storage: In a data lake, all data is stored in a flat, non-hierarchical format as objects with associated metadata. The ability to store data in this fashion is a key differentiator between data lakes and data warehouses.
Data lake file format: File formatting compresses data into column-oriented formats (while preserving the raw data's native state) which enables data queries and analysis at a later date.
Data lake table format: The data lake table format aggregates all data sources into a single table, so that when one data source is updated, all others will update as well.
One common data lake storage approach is to use the Hadoop Distributed File System (HDFS). Hadoop data lakes store data across a set of clustered compute nodes based on commodity server hardware (EDUCBA, 2023). And while data stores using object storage technology with non-HDFS ecosystem components have been gaining in popularity, it's important to note that these non-HDFS data lake solutions are usually part of an enterprise data lake implementation.
Data lake architecture layers
Organizations assemble various assortments of data lake tools to best operationalize their schema-on-read process. It's sometimes helpful to think of these groups of tools in layers, by common function. The basic five layers in data lake architecture include:
Ingestion layer: In this layer, raw data is ingested into the data lake in either real-time or batches. The raw data is then organized into a logical folder structure. It's important to note that the ingestion layer is where data lake stream analysis (e.g., as data is collected, it’s analyzed [in real-time] and then reduced to important data for processing and commitment to storage) occurs. This is slightly different than schema-on-read where all data is ingested into the data lake for later analysis.
Distillation layer: The raw data from the ingestion layer is then converted into a format in readiness for analysis that includes column-oriented files and tables. Data encoding, typing, derivation, and cleansing also occur in this layer.
- Processing layer: This is the layer where analytical algorithms and advanced analytical tools are found. Some of the activities conducted here include data anomaly detection, association rule learning, data clustering, data classification, data regression, and dataset summarization.
Insights layer: Sometimes referred to as the research layer, this is where insights from the processing layer patterns and output are explored and analyzed. Some of the most common data-access languages used to explore these patterns are SQL and NoSQL, but many other programming languages — including Python — can be used depending on the type of research and analytics required. Data scientists are an integral part of the work that occurs in this layer which is a necessity for effective big data analytics.
Operations layer: The operations layer governs system management and monitoring. Such activities as workflow management, data management, data governance, and auditing occur in this layer.
In addition to these common layers, additional elements often include cybersecurity, governance, and compliance tailored to each specific organization and its unique needs.
Data lakes vs data warehouses
The differences between a data lake vs data warehouse are significant. However, these differences are not easily discernible to the end user. Rather, the differences are highlighted in terms of how data integration, data structure, and data storage are approached, as well as how a data lake vs a data warehouse will access data, query data, and process data.

The table below summarizes some of the key differences between data lakes and data warehouses.
The impact of technology and data evolution on data storage
While both a data warehouse and a data lake can support the data storage needs of big data in terms of capacity, data warehouse solutions are not effective in processing, storing, and analyzing unstructured data. This is due to the fact that data warehouses follow the rules of relational databases which require strict adherence to predefined data formats and guiding hierarchies (e.g., structured data, semi-structured data). However, the amount of unstructured data generated is much greater than the amount of structured data generated. In fact, unstructured data comprises roughly 80% or more of all current enterprise data.
In addition, non-alpha-numeric, highly granular data is often found in scientific research, advanced mathematics, healthcare, and more. And, it's in these fields that artificial intelligence (AI) and machine learning (ML) are being actively employed by data scientists and data engineers in order to perform data mining, train ML algorithms, and efficiently analyze vast amounts of unstructured data in minutes instead of days.
Machine learning and unstructured data
Additional examples of AI/ML activities that rely on unstructured data and machine learning data lakes include:
Image analysis: Machine learning is actively employed in reviewing vast numbers of images to quickly identify possible patient issues in MRIs/X-rays, identify manufacturing defects on an assembly line in real-time, or to segment large numbers of meteorological images for climate change studies.
Audio analysis: Machine learning is frequently used to analyze sound files in order to proactively detect possible maintenance issues with manufacturing equipment, complete voice recognition and analysis for both security and law enforcement purposes, and segment audio files (e.g., genres of music, artist).
Video analysis: Using machine learning to analyze driver activities and safety in both commercial passenger transportation and supply chain transportation is now a daily occurrence. Further, ML is even used to help athletes enhance their performance by tracking body position and object trajectory during games. In addition, rapid identification and segmentation of video files is now possible through machine learning.
Text analysis: Natural language processing (NLP) is a form of AI that analyzes text files to do everything from identify the data source to distill the content sentiment (e.g., dissatisfied vs satisfied customer), or extract desired content from digitized documents. In addition, text analysis is a key part of social media strategy for any organization.
These are just a few of the reasons that cloud-based data lakes have become key in big data storage and associated big data analytics.
How to select the right data lake tools
When considering potential cloud data lake options, it's certainly important to conduct extensive research. However, before beginning your research, take a moment to refine your organization's use case(s)/requirements by considering the following.
Key data lake solution questions
Primary use case: How do you anticipate your organization will most often use cloud data lake(s)? Is it primarily to serve as a lower-cost data storage option to feed commercial software, replace an enterprise data warehouse in the long-term, or will your data stream and data lake be additive to an existing enterprise data warehouse, used both to store unstructured data that a data scientist will access along with removing data silos for business analysts' benefit?
Coexistence with a data warehouse: When entering into the world of cloud data lakes, many organizations do so while retaining their existing data warehouse. If that is a possibility, consider how the data warehouse technology will be expected to function alongside the data lake, how data relevant to day-to-day operations will be stored in multiple warehouses and data lakes, and how curated data will be managed. Ideally, data analytics workflows and access will be well-planned elements of an organization's data analytics strategy if using both data warehouses and data lakes.
Scale and agility: While the good news is that data lakes are more easily scalable than data warehouses, it's still important to understand likely changes in your data requirements in the near- and mid-term. What data assets do you anticipate ingesting into your data lake solution at launch, in 18 to 24 months, and beyond?
User types: While it's certainly true that data lakes are excellent at ingesting and storing social media data (e.g., text files, videos, images), it's important to remember that, stand-alone, they don't have the capabilities of an OLAP campaign management or CMR tool. As your organization builds out requirements, remember that business marketing professionals will likely require additional software to access your data lake insights, while data scientists will likely be able to access the unstructured data directly.
Data management and governance strategy: Data warehouses and data lakes differ in best practices relating to data management and governance. In data warehouses, the challenge is formatting, labeling, and cleansing data before it's ingested, whereas the challenge with data lakes is to maintain data quality once ingested to avoid creating data swamps. For organizations new to cloud data lakes, this will require a data management and governance strategy shift. How will your data management and data governance strategy have to shift with the implementation of your data lake solutions?
Internal skill sets: If your organization doesn't have a data lake, it's important to evaluate internal bench strength relating to this type of storage. DBAs and data lake engineers do not commonly possess the same skill set. In addition, big data engineers who manage data lakes are in high demand and can be difficult to find. For some, it makes sense to engage a data lake service provider or contractors until internal skill sets are fully developed.
Additional research
Once your organizational requirements and use case(s) are further refined, it's time to conduct some vendor and tool research. Things to consider include:
Provider/tool reliability and performance ratings.
Provider/tool cybersecurity posture.
Ease of tool integration with other platforms or tools selected.
The product's alignment with required features and functionality.
The product's and provider's alignment with required compliance standards.
In addition, it may be helpful to consult ratings reports — such as Gartner, Forrester, and G2 — to better understand provider and tool rankings within the data lake market as well as your own industry.
Checking expert blogs specific to your industry and reviewing webinars hosted by influential cloud management organizations within your industry vertical can be helpful in understanding the experiences of others who have implemented the platforms and tools being considered. This can also refresh your knowledge of current technology trends in technology relating to your specific discipline.
Top data lake tools
One of the benefits of data lake solutions is that they are highly customizable depending upon an organization's requirements. The following are examples of technology that provide flexible and scalable storage for building data lakes:
Technology for building data lakes
AWS Data Lake Formation/Amazon Simple Storage Service (AWS S3)
Azure Data Lake Storage Gen2
Google Cloud Storage
Snowflake
Tools to organize and query data in data lakes
AWS Athena
Databricks SQL Analytics
MongoDB Atlas Data Federation
Presto
Starburst
Big data analytics tools that work with data lakes
Alteryx
Azure Databricks
Databricks Lakehouse Platform
Google Cloud
MATLAB
Qubole
Starburst
FAQs
What is a data lake?
A data lake is a centralized repository to store vast amounts of data in its original (raw data) format. This means that data ingestion into a data lake is possible without any type of preformatting required.
What are the key characteristics of a data lake?
Some key characteristics of data lakes include:
Multitenancy (where a single software instance serves multiple customers).
Schema-on-read data ingestion.
Storage of unstructured data in its native state.
A "store now, analyze later" focus.
What are the main layers in data lake architecture?
The main data lake architecture layers include:
Ingestion layer: In this layer, raw data is ingested into the data lake in either real-time or batches.
Distillation layer: The raw data from the ingestion layer is then converted into a format in readiness for analysis that includes column-oriented files and tables.
Processing layer: This is the layer where analytical algorithms and advanced analytical tools are found.
Insights layer: Sometimes referred to as the research layer, this is where insights from where patterns and output from the processing layer are explored and analyzed.
Operations layer: The operations layer governs system management and monitoring.
What are the key differences between a data lake and a data warehouse?
There are many differences between a data lake and a data warehouse. Two of the main differences include:
Schema flexibility: In data lakes, an approach called schema-on-read is used to determine the structure of the data schema. This means that the actual data being ingested, as well as the existing data in the data lake, determines the schema used at any given time. With a data warehouse, an approach called schema-on-write is used — which means a pre-defined schema, hierarchy, etc. must be used for all data being ingested.
Data types stored: Data lakes are able to store all types of structured data, semi-structured data, and unstructured data in their respective native states. However, data warehouses are only able to store structured and semi-structured data after processing it into a predefined format and hierarchy prior to ingestion.