Digitization was supposed to solve the archive problem. Scan the pages, run Optical Character Recognition (OCR), enable keyword search—done. Yet decades and millions of dollars later, most newspaper archives remain essentially unusable for serious research.
Consider a major U.S. newspaper with every print edition scanned and available to subscribers. For researchers looking for historical commodity price trends, digitization has changed almost nothing—they're still paging through thousands of editions manually. The bottleneck isn't preservation—it's retrieval.
OCR struggles predictably with century-old newsprint: degraded paper, unusual typefaces, complex layouts. But the deeper issue is what OCR was never designed to handle: the meaning embedded in charts, graphs, and data visualizations. These visual artifacts—often the most analytically valuable content—remain completely invisible to search systems.
Museums and archives worldwide report similar patterns. One institution achieved near-perfect OCR accuracy through flatbed scanners, specialized cradles, and exhaustive QA processes. Yet the fundamental problem persists: keyword search cannot deliver the semantic richness required for longitudinal analysis, trend identification, or comparative research across decades.
The multimodal AI breakthrough
The shift from OCR-plus-search to multimodal vector embeddings represents something more fundamental than improved accuracy. It's a different model of what "searchable" means.
voyage-multimodal-3.5 (which was released last week!) interprets text and imagery directly from scans, mapping entire pages into dense semantic vectors. For example, voyage-multimodal-3.5 effectively vectorizes multimodal data to best capture key semantic features from tables, graphics, figures, slides, PDFs, and more. This enables queries by meaning, context, or visual concept—not just exact keyword matches. Critically, these models understand the semantic content of statistical visualizations, surfacing economic charts for queries like "inflation trends in the 1970s" even when no explanatory text exists.
The implications extend beyond retrieval. For the first time, archives become datasets you can actually analyze. Researchers can measure how coverage of nuclear energy evolved from political debate to scientific consensus—and pinpoint whether these shifts appeared first in editorials or investigative features. They can track how the use of economic charts changed decade by decade, or how renewable energy moved from fringe mentions to front-page dominance.
This isn't just better search. It's the difference between a static collection and a research infrastructure.
Semantic search at scale
MongoDB Atlas Vector Search with Voyage AI's multimodal-3 model enables research questions that traditional keyword search cannot answer. Instead of finding where "renewable energy" appears, researchers can discover how the topic's visual and textual treatment evolved over decades. They can compare front-page coverage against editorial commentary, track the introduction of data visualizations, and identify shifts in framing.
Figure 1. Reference architecture for search in historical archives.
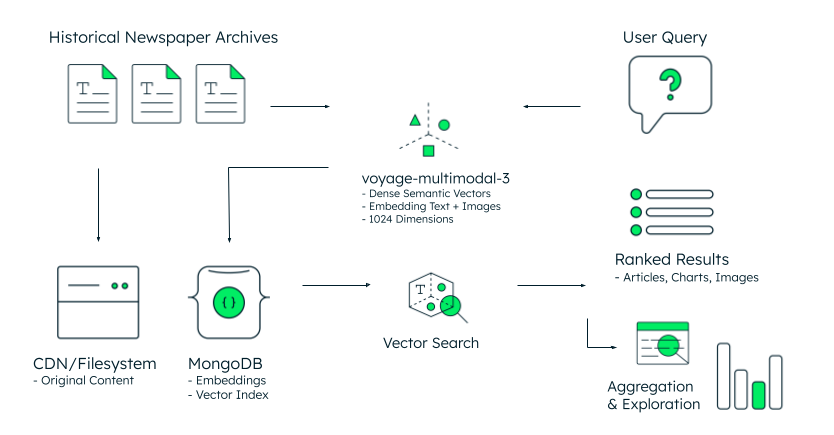
The architecture follows a straightforward workflow, as illustrated in Figure 1. Historical newspaper archives—stored as original content in a CDN or filesystem—get processed through Voyage AI's latest multimodal model, which generates 1024-dimensional vector embeddings from both text and images. MongoDB stores these embeddings alongside metadata in a unified document model, eliminating the synchronization complexity of separate vector stores.
When a researcher queries "public transport debates from the 1970s through the 1990s," the system processes that question into a semantic vector using the same voyage-multimodal-3.5 model. MongoDB's vector search compares this query vector against millions of archived embeddings, retrieving relevant articles, charts, and images based on conceptual similarity in high-dimensional space—not keyword matching. Results return ranked by semantic relevance, surfacing content that shares meaning even when exact terms differ.
The final stage enables aggregation and exploration: researchers can analyze frequency patterns over time, segment results by publication date or section type, and build statistical visualizations from the ranked results. MongoDB's aggregation framework can help handle this analytical layer – easy and intuitive to implement, powerful in adding incremental value to the data retrieved.
MongoDB's dedicated search nodes provide workload isolation, scaling vector search infrastructure independently from operational database loads. When structured metadata exists—publication dates, section labels, or other cataloged attributes—MongoDB's hybrid search combines semantic similarity with traditional filters in a single query, refining results without sacrificing semantic power.
Roadmap for IT leaders
Starting with a pilot collection of 10,000 to 20,000 pages makes sense—but the selection criteria matter more than the volume. Collections should span diverse content types: articles, advertisements, charts, infographics, and potentially video. The goal is to validate whether multimodal models and vector search can accurately surface both textual and visual content through semantic queries.
Success metrics worth tracking: retrieval recall above 90% across content types, reduction in manual labor costs, acceleration of research workflows, and measurable increases in archive engagement. Revenue opportunities through API licensing and monetization of visual assets are secondary indicators—they depend on first proving the research value.
The strategic question isn't whether to modernize archives. It's whether your organization sees archives as static collections to be preserved, or as dynamic knowledge systems that can generate ongoing value. Multimodal AI and vector search enable the latter—but only if the surrounding infrastructure supports analytical workflows, not just retrieval.
This isn't an incremental improvement. It's a category shift in what digitized archives can do.
Next Steps
Visit the Media and Entertainment webpage and learn more about MongoDB’s role in the Media Industry.
Read the Voyage-multimodal-3 blog to learn how Voyage AI enables embeddings for text, images, and screenshots.
Explore the MongoDB Solutions Library to discover best practices, ready-to-use templates, and expert guidance for building powerful applications.
Learn how companies have innovated with MongoDB with these customer success stories.