I have a custom ML model which produces an embedding of size 512 model.
I wrote a custom script utilizing the model and sending the embedding to the collection (which is empty). script
I am testing the code in the following python notebook notebook and the error is
OperationFailure: PlanExecutor error during aggregation :: caused by :: EuclidianEmbedding_1 is not indexed as knnVector, full error: {'ok': 0.0, 'errmsg': 'PlanExecutor error during aggregation :: caused by :: EuclidianEmbedding_1 is not indexed as knnVector', 'code': 8, 'codeName': 'UnknownError', '$clusterTime': {'clusterTime': Timestamp(1716546450, 2), 'signature': {'hash': b'\xf4B1N\xc2\xffG\x9d$J}\xea\xad\xfe\xdfz\x83Cx\x80', 'keyId': 7345064297216606213}}, 'operationTime': Timestamp(1716546450, 2)}
How would you recommend the atas vector search index be like? I have written one vector search of my own, but I believe it is not working.
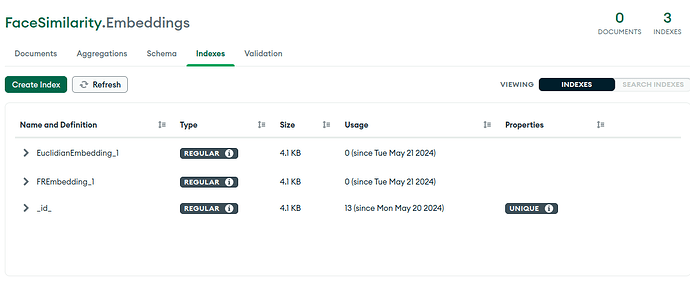
Here are the indexes for it.
Hi @Chaitanya_Kohli! I would verify that the type of RecFace returned in your vectorSearch function is a list of floating point numbers. This error usually appears if there is a type issue during indexing.