Day 44 of 100daysofcode challenge: Knowledge-Based Agents
Day 44 of 100daysofcode challenge: Knowledge-Based Agents
 What is a Knowledge-Based Agent?
What is a Knowledge-Based Agent?
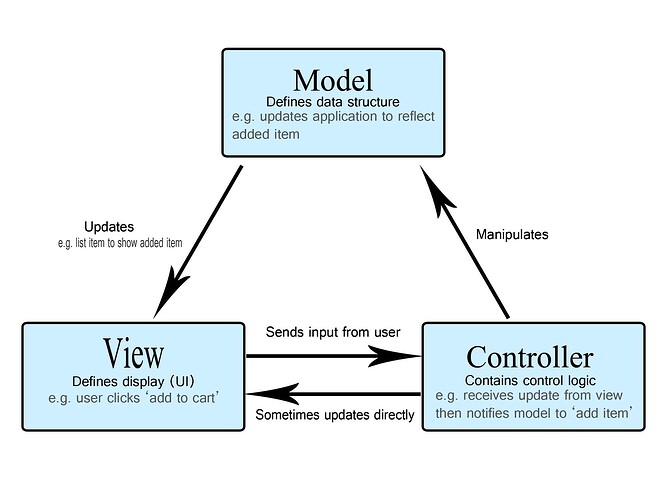
A knowledge-based agent is a type of artificial intelligence (AI) that uses knowledge to reason, make decisions, and take actions. It’s a software program that mimics human-like intelligence by using a knowledge base to guide its behavior.
 Characteristics of Knowledge-Based Agents:
Characteristics of Knowledge-Based Agents:
 Knowledge Representation: A knowledge-based agent represents knowledge in a structured and organized way, using formats like rules, frames, or semantic networks.
Knowledge Representation: A knowledge-based agent represents knowledge in a structured and organized way, using formats like rules, frames, or semantic networks.
Reasoning and Inference:The agent uses reasoning and inference techniques to draw conclusions from the knowledge base, making it possible to make decisions and take actions.
Knowledge Acquisition:The agent can acquire new knowledge through various means, such as learning from experience, being told by humans, or extracting information from data.
Context-Aware:Knowledge-based agents can understand the context in which they operate, allowing them to adapt to changing situations.
Types of Knowledge-Based Agents:
Simple Reflex Agent: Reacts to the current state of the environment without considering future consequences.
Model-Based Reflex Agent: Maintains an internal model of the environment and uses this model to make decisions.
Goal-Based Agent:Has specific goals and uses planning and decision-making to achieve those goals.
Unity-Based Agent:Combines multiple agents to achieve a common goal.