I have documents, each with an array field “tags”, as illustrated below. Each tag is a pair of (ns, name).
I want to efficiently find all the tags belonging to a certain userId — aka all the unique pairs of (ns, name). Therefore I create a index on (userId, tags.ns, tags.name). It’s a MultiKey index because it indexes array fields.
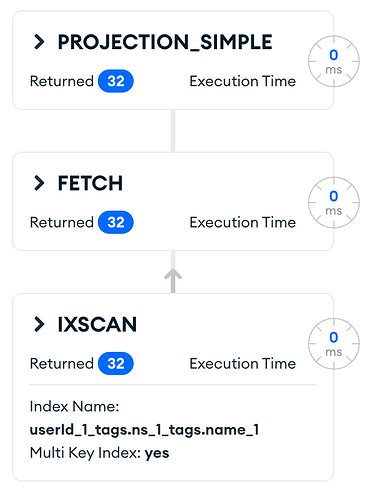
Then, I ran the following aggregation pipeline using “$unwind” and “$group”, hoping that my index will cover this query. However, according to explain(), it doesn’t . What MongoDB did was to IXSCAN on this index to find ALL the documents belonging to the userId, and then fetch the documents, and then run the rest of grouping. This is very inefficient . I think all the information are already in the index. How can I force MongoDB to only use that index?
As illustration, my collection contains these documents:
[{
"_id": {
"$oid": "6611a306cd377c1f9ef54538"
},
"userId": "1",
"tags": [
{
"ns": "UserTags",
"name": "tag1"
},
{
"ns": "SystemTags",
"name": "tag1"
}
]
},
{
"_id": {
"$oid": "661232f86e2b72aae0b39cad"
},
"userId": "1",
"tags": [
{
"ns": "UserTags",
"name": "tag2"
}
]
}]
The aggregation pipeline I used is:
[ { $sort: { "userId": 1, "tags.ns": 1, "tags.name": 1 } }, { $match: { userId: "690a5c13-0b4b-4464-8716-361c04b81923" } }, { $unwind: "$tags" }, { $group: { _id: {ns: "$tags.ns", name: "$tags.name"} } }, { $project: { _id: 0, ns: "$_id.ns", name: "$_id.name" } } ]
The execution plan is: