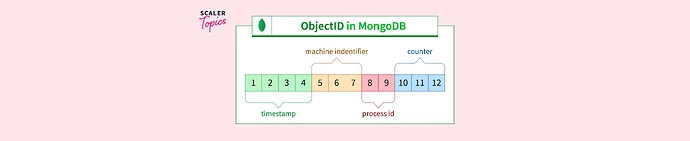
If using server generated IDs you can generate an artificial ObjectID to cover the range that you want to filter on. We’ve actually done this recently when we needed to extract data on a day to day basis.
Something like this:
- Get start and end dates
- Convert each date to a unix timestamp and then to base 16, padded to 24 chars with trailing “0”
- In the query compare the _id field against the generated object IDs
This obviously depends on you using default IDs for timestamps, needing to scan each collection (but this should be a fast check). Long term is also locks you into using _id as ObjectID and that Mongo do not change the ordering of the field which should hopefully not happen anyway.
You can use replication log on a single node instance, just setup it up as a replicaset with one node, of source there are limits you can set and update to determine the window of operations that are available.
You could always make use of a change stream at a database level or something to track documents created / day with the _id and date but if using ObjectIDs you’d be basically duplicating data.
Now updated documents…that would be different!