Peek at your MongoDB Clusters like a Pro with Keyhole: Part 3
In part 3 of this blog post, you will learn about Keyhole's new Full Time Diagnostic Data Capture (FTDC) Assessment panel and how FTDC scoring works. In the previous two parts of this blog, part 1 and 2, we discussed how to use Keyhole and Maobi to analyze MongoDB clusters. One of the most exciting features is the visualized presentation of FTDC data. Understanding these charts is similar to following the shadow of the moon, which has 30 different shapes and even more different shades of gray. Interpretations of these FTDC charts could also be subjective and relatively time-consuming, and thus I added a scoring feature to help identify potential problems quickly.
I split the FTDC analytics feature from Keyhole in another GitHub repository, mongo-ftdc, to better support people who opt to skip the Grafana installation. As you might expect, Keyhole imports the mongo-ftdc package.
Five Boldest Strokes
There are many software options available to display MongoDB metrics. Most focus on reflecting server status in charts, but none of them provide the additional information required to flag problems. There is no simple answer because there are many factors to consider, including resource availability and quality, transaction rates, and configuration specifics.
I recall a movie line, “The difference between a good painting and a great painting is the five boldest strokes.” This inspired me to add a few bold strokes to Keyhole by applying scoring algorithms to metrics in an assessment panel.
How Scoring Works
In order to remove any anomalies in the data, only data points between the 5th and 95th percentile are evaluated. A metric can score from 0 to 100 and the higher the score, the better. The color codes are defined in the Grafana configurations. By default, scoring under 20 is highlighted in red and over 50 is in green. A score between 20 and 50 is flagged in orange color. Below is an example:
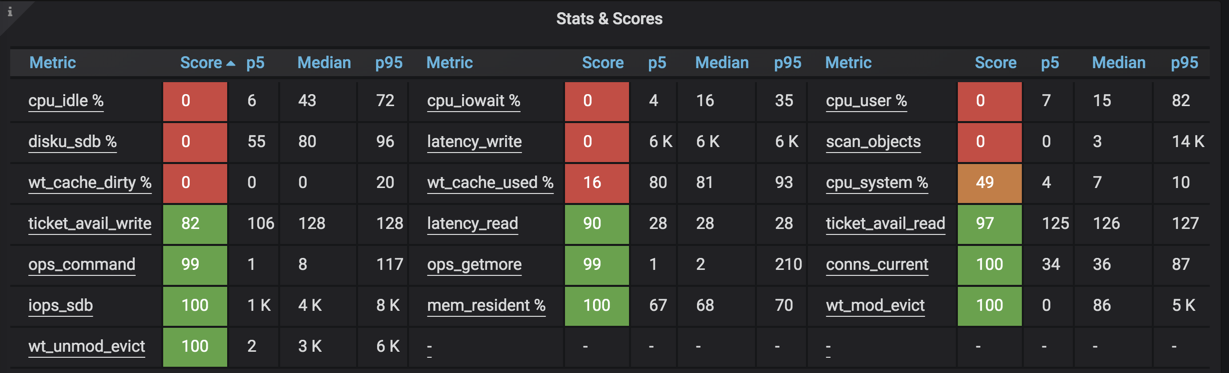
The formula to determine the score of a metric varies depending on the nature of that metric. In the initial release of this new feature, formulas are defined from my experience. I am open to feedback and will fine-tune the metrics as we go. In the meantime, let’s discuss a few details of the formulas available by clicking on the metrics’ links.
Low and High Watermarks
All formulas have low and high usage watermarks. If the usage is below the low watermark, a score of 100 is given. On the other hand, if the usage is above the high watermark, a score of 0 is assigned. For example, the score of ticket_avail_read is scored with a formula of:
100 * (p5 of ticket_avail_read) / 128
, where p5 indicates the fifth percentile of the data points.
Another example is cpu_iowait; in that case the score is bounded as follows:
value := (p95 of cpu_iowait)
if value < low_wm {
score = 100
} else if value > high_wm {
score = 0
} else {
score = 100 * (1 - (value - low_wm) / (high_wm - low_wm))
}
, where p95 indicates 95th percentile of the data points.
Metrics with Known Behavior
For metrics with known behavior, I use the given thresholds as low and high watermarks to calculate scores. For example, when WiredTiger cache used (wt_cache_used) is over 80%, it triggers evictions using background threads. If the cache used is over 95%, application threads are used for active evictions. Therefore, to calculate the score, Keyhole uses 80% as the low watermark and 95% for the high watermark.
Metrics Calculated with Derived Values
The scores of a few metrics depend on the derived values, for example, the total number of connections (conn_current). It is less than ideal to provide a score simply based on the number of connections. We instead evaluate it by calculating how much memory is used by all connections. Each connection will account for roughly 1MB of memory. Keyhole first calculates the percentage of memory allocated to connections and uses 5% as the low watermark and 20% for the high watermark to calculate its score.
Bottleneck Patterns
MongoDB is like a coworker you can only dream of. One who is smart, friendly, stylish but not flashy, and speaks multiple languages. Does one have a happy life? That’s on Instagram. Under stress, one shows a few syntactic patterns. Below are a few patterns for discussions and you can find charts and examples in the Keyhole Wiki page.
Lost in Space
You didn’t have expected performance results from properly provisioned resources even if the provisioned memory was enough to contain the working set data. In this pattern, all metrics were in healthy states except a large number of scanned objects. This could be a textbook case of using improper or even missing indexes. Even when the entire working set fits in memory, without proper indexes there could be an excessive number of object scans. Imagine a spaceship roaming in space without a navigation system; there will be more space to cover, thus resulting in a much slower response from a query.
Dream Weaver
Another commonly experienced underperforming read operation was caused by less than ideal data access use cases. Most read related metrics were flagged, such as low WiredTiger available read tickets, high WiredTiger cache used, and a large number of scanned objects.
Architects and developers are attracted to MongoDB because of its modern and flexible technologies. With simple transformations, one can quickly turn XML into JSON data or to directly map relational database tables to MongoDB collections. It's like a dream come true, and Dream Weavers love to use the $lookup operator and allow many collections to get carelessly intertwined. Such implementations do not work efficiently. An important principle of using MongoDB is to have a proper schema to support your use cases. MongoDB is not "schema-less"; rather, it allows for multiple concurrent schemas to be present. These schemas, however, need to be designed appropriately.
Vikings Attack
Everything worked mostly during the day except for a short period of time. During the time, the cluster experienced high CPU utilization on I/O wait, WiredTiger dirty data ratio, and disk IOPS. Resources provisioning should be based on loads during peak hours. Many businesses must process a large number of transactions within a limited time. As such, the database operations burst in like a sudden Viking attack -- arriving in fast dragon ships and flooding in on the crest of morning tides. Vikings were huge and enormous, and they charged fearlessly with long swords, axes, and round wooden shields. In this case, these short 'attacks' raided the village, burning up disk IOPS, and brought oplog collection to the ground before retrieval was complete.
New York, New York
Many people rush to New York to melt away little town blues, so the City can use a little bit of breathing room at times. Similarly, hosting an excessive number of collections and indexes in a MongoDB cluster creates additional overhead in WiredTiger. We often see this in multi-tenant implementations. The large number of tables maintained to support collections and indexes in the WiredTiger results in the high number of WiredTiger data handles, which cause extremely long checkpoints and block all the running operations.
Angel Has Fallen
Almost all metrics reveal that resources were all under stress. The number of queued operations was high and the cluster was restlessly catching up. All resources might be simply pegged out from many charts showing high flying plateau lines. If there is no room for tuning, consider scaling up resources or sharding.