Artificial intelligence (AI) is the capability of machines to think rationally, solve problems, and make decisions without the supervision of a human mind. With the advent of machine learning and deep learning technologies, machines are able to “think” and “learn” based on the data fed to them and perform tasks that could previously only be done by humans. In this article, we will explore more about artificial intelligence, generative AI, and how MongoDB is changing the face of generative AI by simplifying AI processing, enabling context-based searches, and enhancing the accuracy of large language models (LLMs).
Table of contents
- Artificial intelligence explained
- How AI is similar to human intelligence
- AI vs. machine learning
- Deep learning
- History of artificial intelligence
- Types of AI
- Foundation models
- Generative AI
- Large language model (LLM)
- Retrieval-augmented generation (RAG)
- Vector search
- MongoDB Atlas Vector Search
- How does Atlas Vector search work?
- Important AI use cases
- Ethical use of AI, AI governance, and regulations
- AI tools and services
- FAQs
Artificial intelligence explained
Artificial intelligence is a field of computer science that empowers machines to engage in reasoning, intelligent decision-making, and data analysis, on a scale that is perceived to surpass human comprehension and capabilities. It includes fields like data science, statistics, neuroscience, and machine learning, which further includes deep learning techniques, on which our modern algorithms are based. These algorithms are the foundation for AI to make human-like decisions by comprehending data into patterns, and performing difficult tasks with ease and accuracy.
Some popular examples of artificial intelligence systems include ChatGPT, virtual assistants like Alexa and Siri, self-driving cars, and recommendation engines.
How AI is similar to human intelligence
The human brain works in a complex way. We think, act, and make decisions based on our past experiences and memories, deriving patterns based on surroundings and situations. Over a period of time, what we observe is what the brain perceives to be true. For example, if we consistently see a red rose, our brain processes that a rose is red in color and has a certain shape and size. If we read or hear that roses can also be yellow or pink, based on our previous knowledge of a red rose, we imagine a yellow or pink rose to, in a certain way, closely resemble a red rose.
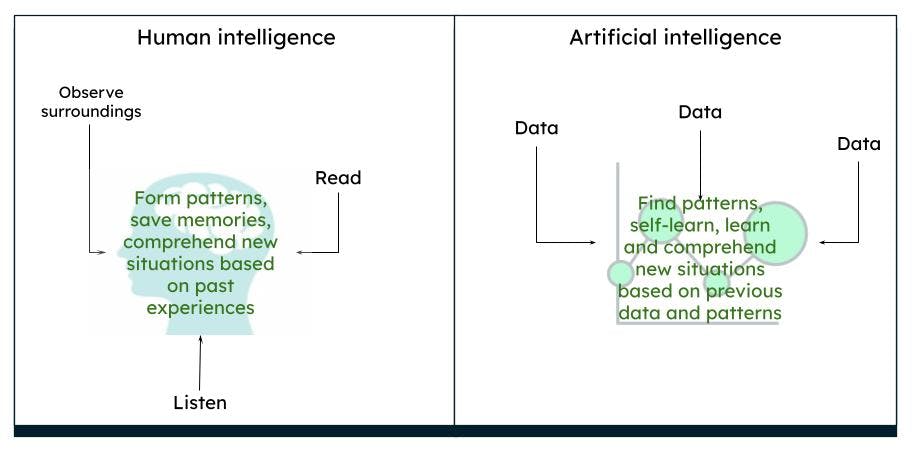 Representation of human intelligence vs artificial intelligence
Representation of human intelligence vs artificial intelligence
AI works in the same way. When a computer is fed with enough data, it is capable of deriving certain outcomes, based on the data patterns, through algorithms. For example, if you feed data about roses and colors, the next time the computer sees a similar object, it can identify the object as a rose of a particular color.
AI vs. machine learning
AI is a broader term that consists of theories and systems to build machines that perform tasks requiring intelligence. Machine learning is a branch of AI that focuses on the analysis of data, to find patterns and drive decisions using various algorithms, without the need for explicit programming. Machine learning techniques consist of supervised and unsupervised learning and reinforcement learning methods.
Deep learning
Deep learning is a subset of machine learning that resembles human intelligence. Deep learning models consist of artificial deep neural networks—i.e., interconnected neurons (or nodes)—and have many layers, enabling them to process more complex data patterns than machine learning algorithms. LLMs and generative AIs are subsets of deep learning. There are many artificial neural networks that can be used for specific tasks.
All these neural networks are based on a “perceptron,” which is the most basic neural network used for binary classification. A perceptron consists of a single layer of neurons that takes an input layer, applies weights, and feeds it to the output layer.
Below are several common types of deep learning:
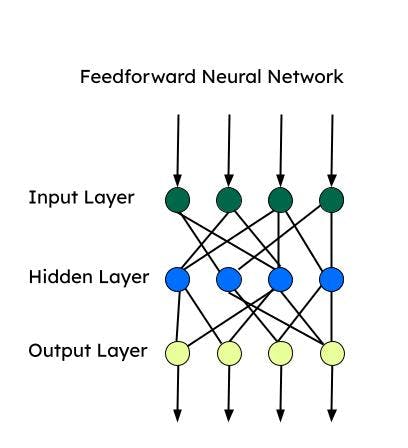
Feedforward neural network (FNN)
Feedforward is one of the first artificial neural networks developed and consists of a group of multiple perceptrons in each layer. It is also known as the multi-layer perceptron (MLP). It only feeds information in one direction—i.e., the forward direction—and there are no loops. Feedforward neural networks have input, output, and a hidden layer that processes the input. FNNs are used for supervised learning, when the data is not time-dependent or sequential.
Convolutional neural networks (CNN)
CNNs are a type of FNN used for complex image classification tasks, computer vision, image analysis, and natural language processing. A CNN looks at one patch of image at a time, and moves forward with a lesser number of parameters at a time to learn or extract the most important features. The feature extraction is done using kernels during a convolution operation.
Recurrent neural networks (RNN)
RNNs are more suitable for sequential data, where the order of input is crucial. The sequential information is captured via a loop in the input layer. RNNs are more suitable for time-series data and natural language processing. Long short-term memory (LSTM) is a type of RNN, which has memory cells to store dependencies of the sequential data. LSTMs are quite good in speech recognition, sentiment analysis, and translation.
Autoencoder
Autoencoders consist of an encoder and decoder. Encoders compress the dimensions of the data to lower dimensional space (latent space). Decoders reconstruct the input data using the latent space. Autoencoders can be used for denoising, dimensionality reduction, and feature learning.
Self-attention networks (SANs)
The encoder-decoder architecture can remember shorter sequences. However, it can forget some of the information (particularly, information that is received first) in a long sequence. With an attention mechanism, the decoder can attend to the entire sequence and use the context of the entire sequence to produce the output. The self-attention allows all the input text to be processed at once and creates relationships between all the words in the entire sequence. With this feature, self-attention works faster than an RNN or CNN for long-range dependencies.
History of artificial intelligence
Although the early imaginings started as far back as 750 BC through books and ideas based on science fiction and thinking machines, the first groundwork for neural networks was laid in 1947 by Walter Pitts and Warren McCulloch, who created a computational model for neural network architecture.
In 1950, Alan Turing introduced the Turing test, to define machine intelligence.
The term artificial intelligence was coined in 1956, when John McCarthy organized an AI workshop and defined the term as the science and engineering of making machines intelligent. Around the early 1960s, Frank Rosenblatt developed the first computer program—Perceptron—-that an AI program would learn from trial and error. Later, in 1963, John McCarthy founded the AI lab.
The next major breakthrough in AI came through the expert systems, knowledge-based computer systems that require human intelligence but could emulate decision-making capabilities of a human expert. These systems were quite successful forms of AI and were used as AI technology, in healthcare, combat and training simulators, and mission management aids. During the 1980s, artificial intelligence became an industry where billions of dollars were invested on expert systems, vision systems, and robotics.
In 1997, the development of Deep Blue, IBM’s chess-playing computer that defeated the then- world chess champion, created further interest in artificial intelligence. Rapid developments have been seen in the field since then.
Around 2010, researchers working on natural language translation found that, compared to models with rule-based systems, models that were fed with huge amounts of diverse text data produced far better results. In 2011, personal assistants like Cortana, Siri, and Alexa, which could answer questions through natural language processing and perform tasks, entered the picture.
By 2014, language models started to understand the context in which a word appeared. Further works resulted in general language models that provided base or foundation models that could be tailored for a specific use case or domain.
These foundation models have led us toward generative AI and large language models (LLMs) like ChatGPT. Alongside this, agentic AI is emerging as a related technology—a type of artificial intelligence system that can autonomously make decisions, take actions, and adapt to changing environments to achieve a specific goal.
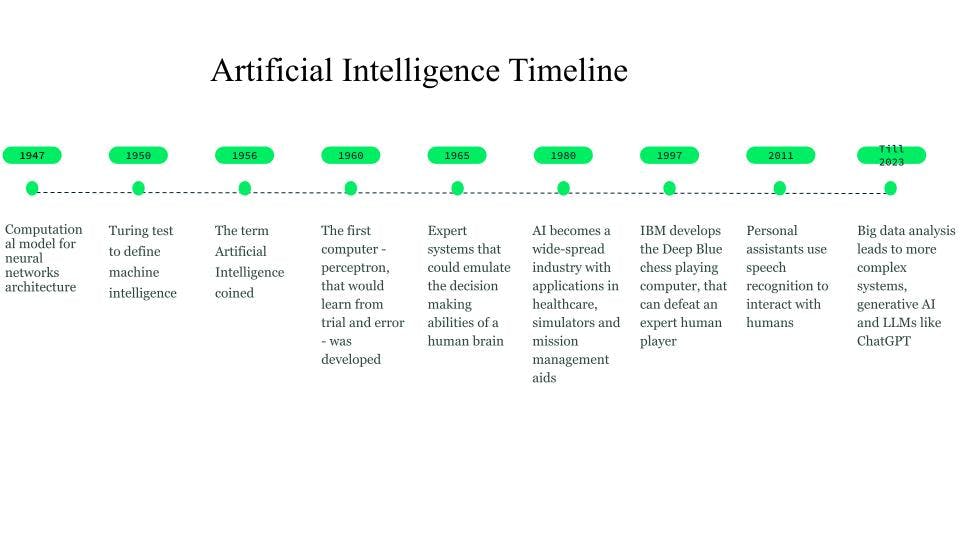 History and timeline of AI
History and timeline of AI
Types of AI
A broad classification of artificial intelligence, based on its capability, is narrow (or weak) AI and strong AI. Through research and advancements in the field of machine learning and deep learning algorithms, we are moving from weak AI to strong AI.
Narrow AI
Weak AI/narrow AI, or artificial narrow intelligence (ANI), systems are trained to perform specific tasks and have limited capabilities based on the data they are trained on. They are also known as traditional AI systems, where the system can respond intelligently based on a certain set of inputs and rules. However, it cannot create anything new.
Traditional or weak AIs are further classified into two categories: reactive machines and limited memory.
Reactive machines
The oldest form of artificial intelligence was the reactive machines that did not have a memory but could emulate a human’s ability to respond to different stimuli. They cannot learn from their experience (no memory) and base their response on a limited combination of inputs. IBM’s Deep Blue machine is a reactive machine.
Limited memory AI
Limited memory systems have memory and can learn and make decisions based on the input data provided. Most of the AI we see—self-driving cars, chatbots, personal assistants like Alexa, and recommendation systems like that of Netflix—are all examples of limited memory AIs.
Strong AI
With the innovation of ChatGPT and other similar generative AI models, we are slowly entering the strong AI phase. Generative AI is a sort of next-gen AI, which can create something new based on user inputs. ChatGPT is an example of generative AI based on the large language model (LLM). Much more work needs to be done in strong AI, which can be categorized as follows:
Theory of mind (ToM)
ToM is a cognitive skill to understand the different mental states—like beliefs, thoughts, and the feelings of others—to explain their behavior and actions. Researchers are working on applying ToM to AI with the goal of enabling AI systems to understand human beings' emotions and states of mind. ChatGPT, the new AI system that can interact with humans in natural language and produce new content, has demonstrated some form of theory of mind during testing. However, it still does not possess the ability to comprehend desires, beliefs, or emotions. The responses of ChatGPT are based on data and common patterns.
Artificial general intelligence (AGI)
Artificial general intelligence is the next stage of AI development, where an AI system or agent will behave exactly like a human, including independently building multiple competencies and functionalities as well as forming connections and generalizations, with little or no training.
Self-aware
The next stage is a point of AI singularity, where machines will be aware of self. They will have their own desires, beliefs, and emotions, in addition to understanding human emotions, desires, and beliefs. Self-aware agents can be used in healthcare and robotics.
Artificial super intelligence (ASI)
Self-aware AI may lead to ASI, where AI agents might become super artificially intelligent systems and overpower humans in values and motives. Self-aware AIs and ASIs could raise problems with employment and ethics, for which researchers and governments need to be alert and form rules and guidelines.
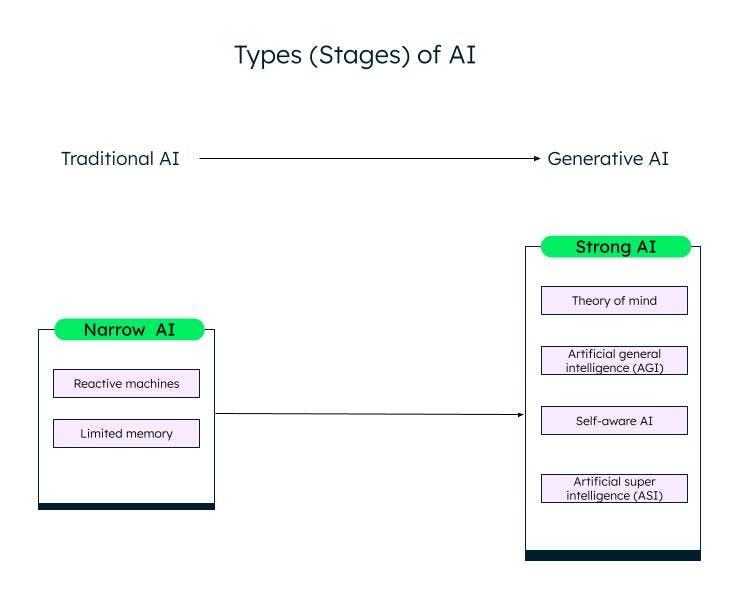 Different stages (types) of AI
Different stages (types) of AI
Foundation models
Foundation models are generalized artificial deep neural networks trained on huge amounts of unstructured data. They are built to serve as general purpose models. We can build more specific models for AI and machine learning tasks by customizing these pre-trained base (foundation) models.
For example, a foundation model like the large language model trained on text data can be used for a variety of tasks, such as information retrieval and question-answers. Generative pre-trained transformer or GPT (on which the famous ChatGPT is based) and BERT (bidirectional encoder representations from transformers) are examples of LLM foundation models. ResNet (residual network) is a popular computer vision type of foundation model for image classification and computer vision tasks. Foundation models are very adaptable and can self-supervise and improvise through prompts and fine-tuning.
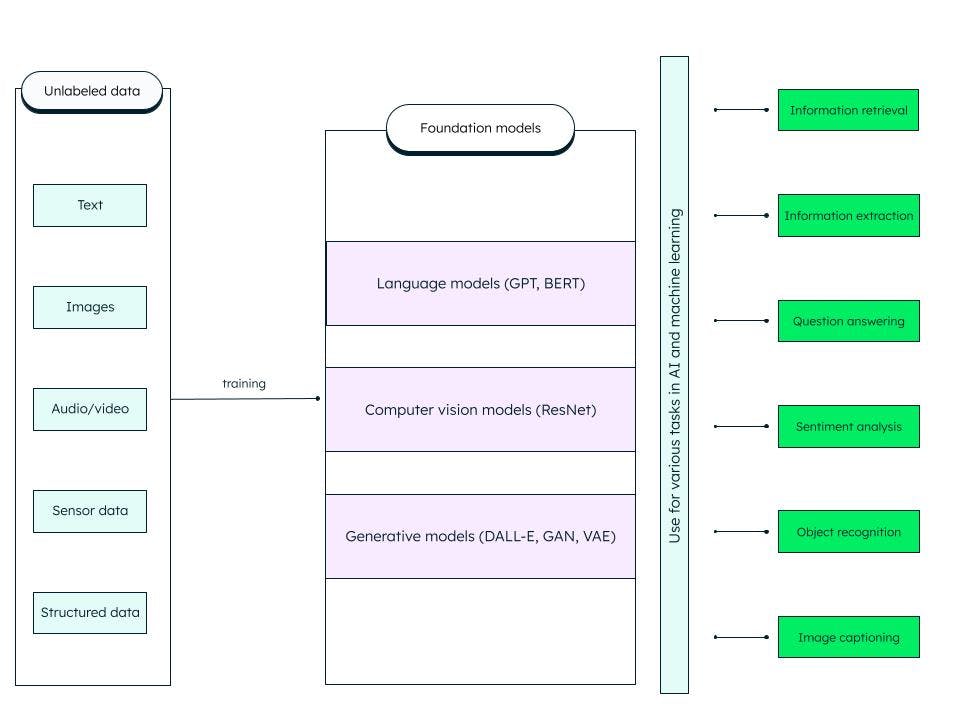
What does the foundation model include?
Generative AI
Generative AI is based on foundation models that can perform tasks like classification, sentence completion, generation of image or voice, and synthetic (artificially generated) data. Foundation models are fine-tuned to suit the specific generative task at hand. The success of a generative AI model depends on the quality and diversity of data, and the speed of generation.
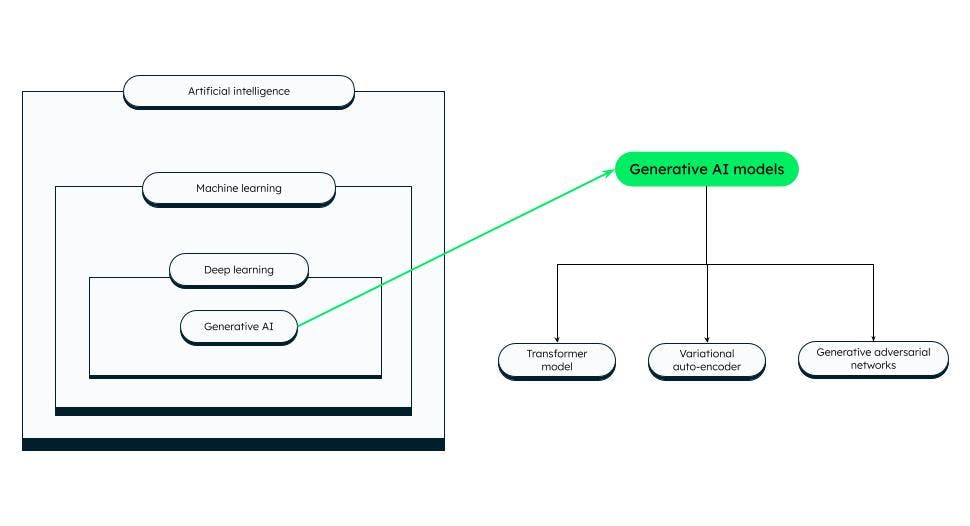 Generative AI models
Generative AI models
There are different categories of generative AI models, of which some prominent ones are:
Transformer model
Transformer-based architecture is quite accurate in identifying contextual relationships between words (data). Text generation, machine translation, and language modeling, like GPT (used in ChatGPT), are examples of transformer architecture.
Attention is all you need
The transformer model works on a self-attention mechanism, where-in the importance of each element in an input sequence is weighed during processing of text, thus capturing the contextual information effectively.
For example, if you want to translate the English text “I love to write about artificial intelligence” into Spanish, the transformer model would pass this sequence of words (tokens) into the encoder (neural network). The input words are converted into a numeric vector representation (word embeddings), consisting of the query (the transformation needed), the key (input), and the value (output) vectors.
For example, for the word “‘love”’ in our sentence, we would have q_love, k_love, and v_love vectors. A matrix is created with the similarity score of each word to another. For example, the similarity of the word “‘love”’ with all the other words of the sentence would be generated—a higher score indicates more similarity.
The next step is to calculate the attention weights that determine how much importance should be given to each word in the sentence in relation to the main keyword (“love,” in our case). The next step is to add the positional encodings to the vector representations. Positional embeddings (similarity + positional encoding) help the decoder (another neural network) decide the order in which the output tokens (words) should be placed.
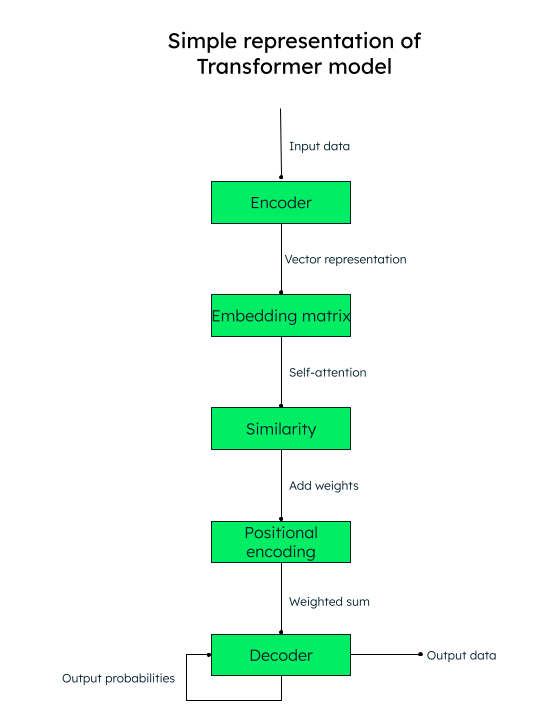
Representation of transformer model
Variational auto-encoders (VAEs)
VAEs are quite popular for image generation, data compression, and image denoising. In a VAE, the encoder neural network takes the input data points and maps them to a latent space representation. A latent space is the representation of data in a lower dimension by extracting the most important features of the data and discarding other features. The decoder neural network reconstructs the output data based on the latent representation.
Generative adversarial networks (GANs)
GANs are extensively used to create realistic images, art, deepfake videos, image-to-image translation, and super resolution images. A GAN consists of a generator (neural network) that takes random noise or seed as its input and creates synthetic data samples (like an image). The synthetic data samples are then fed to another neural network, Discriminator, that uses binary classification to determine if the samples are fake or real. Through adversarial training, the generator and discriminator are trained simultaneously until a Nash equilibrium is reached, where the generator is able to produce high-quality realistic data (like images) and the discriminator accurately categorizes them as real or fake.
Large language model (LLM)
LLMs are a foundation model that trains on huge datasets, and provide a near accurate and engaging experience for users. To be able to build such models, you need to capture huge amounts of data from multiple sources, store them correctly, and process and fetch them based on relevance, when required.
LLMs can be used for general problem solving, like answering questions, text generation, text classification and summarization, and fine-tuning using tuning and prompting to train on a minimal data set for solving specific problems.
How does an LLM work?
Foundation models learn from data patterns and produce a flexible, generalizable output, which can be then applied to different specific instances. One such instance is the LLM, which is applied for text-based inputs. LLMs consist of data, architecture, and training. The data is generally petabytes of large books, conversations, and text content. The architecture is a deep neural network, and in the case of GPT, it is the transformer. During training, the model learns to predict the next word of any given sentence.
However, there are three problems with the LLM:
If any information has been developed or changed after the model is completely trained, the model wouldn’t know about it and might give outdated results. For example, if you ask the model, “Give me a list of good comedy movies in the last 6 months,” the model would not be able to do that if it was trained six months back!
The model might have incorrect information inside of its internal representation.
The model cannot access your private data and could present biased or incomplete information based on limited knowledge.
Retrieval-augmented generation (RAG)
The RAG AI framework aims to solve the above problems and improve the quality of LLM responses by providing the model with grounding truth on an external knowledge-base that supplements the information internally presented in the LLM. This reduces the chances of the model incorrectly identifying a non-existent pattern or object (hallucinations), and incorrect, misleading, and outdated information.
The retrieval architecture uses a vector store and augments the capability of LLM through vector search.
MongoDB Atlas, the unified developer data platform, provides vector search within the platform—-which you can set up in a few simple steps—to enhance the output of your LLM and produce more accurate results.
Vector search
We learnt in the previous section about the transformer model and that vectors are numeric representations of text data. For example, the vector representation of our previous sentence, “I love to write about artificial intelligence,” could be similar to:
“I love to… ” = [0.33, 0.45, 0.72, -0.23…..]
The above vector representation includes the relationship between each word, like how the word “artificial” relates to the word “intelligence” or to the word “write,” or what the context of the word “‘love”’ is in this sentence.
These vectors are generated (as we saw in the transformer model) by sending the input data through a deep neural network (encoder).
In reality, the vector representations can have any number of dimensions. The more parameters data has, the more dimensions there are to it. To be able to make sense of these numbers and to understand what happens after these vectors are generated, let us plot a graph in two dimensions for ease of understanding.
All the vectors are plotted as per their numeric representation. Note that embeddings (vectors) that have similar meaning will be plotted close to one another, thus forming a cluster.
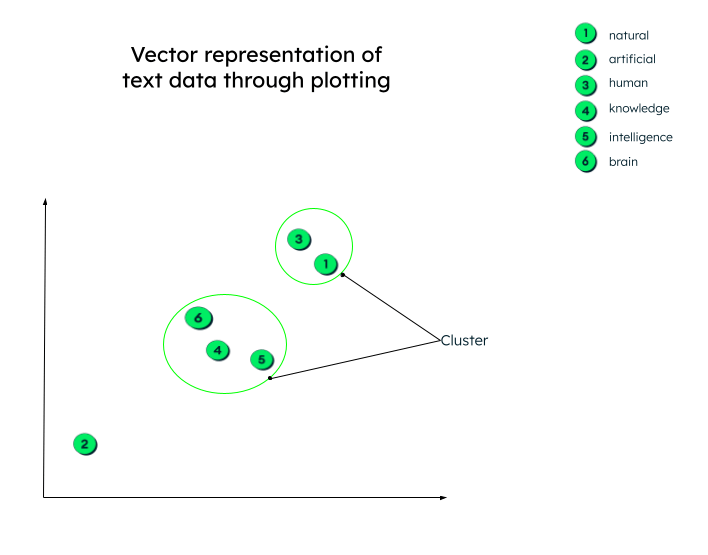 Graphical representation of vectors
Graphical representation of vectors
There might be many contexts in which the data can be clustered. The relationship depends on how the encoder embeds the source data and how the distance between the vectors is calculated. In the below example, two types of relationships can be established:
- Both cat and dog are domestic animals, while tiger and wolf are wild animals.
- Cat and tiger belong to the same family, whereas dog and wolf belong to the same family of animals.
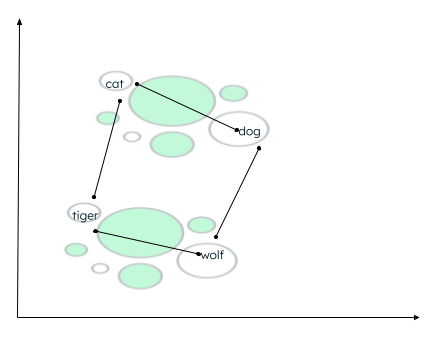
Calculation of distance of similar words
A similarity function determines which words are closer, and labels closely placed words as neighbors. This grouping/clustering is done using the k-nearest neighbor algorithm, where the value of k represents the number of neighbors to be identified. To find the similarity, vector search supports many methods, like finding the:
- Euclidean distance between the ends of the two vectors.
- Cosine (angle) between the two vectors.
- Dot (scalar) product of the vectors.
MongoDB Atlas provides the vector search features within the Atlas platform itself, through AI frameworks, and supports all the above similarity functions.
MongoDB Atlas Vector Search
MongoDB has always supported vector search in two dimensions. However, the new vector search enables powerful capabilities due to embedding and allows higher dimensions.
Applications can write the data as well as the vector embeddings into the database. The data vectors are generated using an encoder model. Atlas search uses the Approximate Nearest Neighbor (ANN) algorithm via the Hierarchical Navigable Small World (HNSW) graph. ANN is a variation of the k-nearest neighbor but with a higher speed of retrieval.
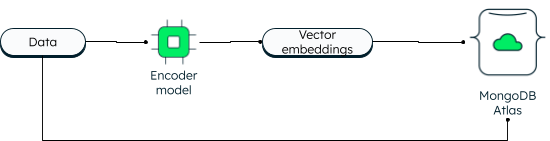
How vectors are stored in MongoDB Atlas
While reading, the query is encoded and submitted in the $search aggregation stage along with the target vector. If you want to learn the steps, follow the tutorial on building generative AI applications using MongoDB.
The advantage of having vectors alongside the operational data is that you can access all the information inside a single platform, even your private data, which would not be accessible otherwise.
Atlas vector search simplifies your application architecture. As Atlas is fully managed, everything from data synchronization, security, and privacy is taken care of by the MongoDB Atlas platform. Developers can work with the database and vector search using the unified MongoDB Query API. You can deploy Atlas to over 100 regions across three major cloud providers. Atlas provides you with continuous uptime with advanced automation that ensures high performance irrespective of the application scale.
Some prominent use cases of Atlas vector search are:
- Semantic search.
- Question-answer systems.
- Feature extraction.
- Recommendation and relevance scoring.
- Synonym generation.
- Image search.
How does Atlas Vector search work?
The client application sends the raw data. The vector embedding model creates vectors for each text in the initial query (raw data). Frameworks like LlamaIndex and LangChain integrate well with MongoDB Atlas to create embeddings and send data to MongoDB for adding contextual awareness. The context-aware query, known as the prompt, is then sent to an LLM, which generates an encoded response, to be processed by the vector embedding model (decoder) and sent to the client after decoding.
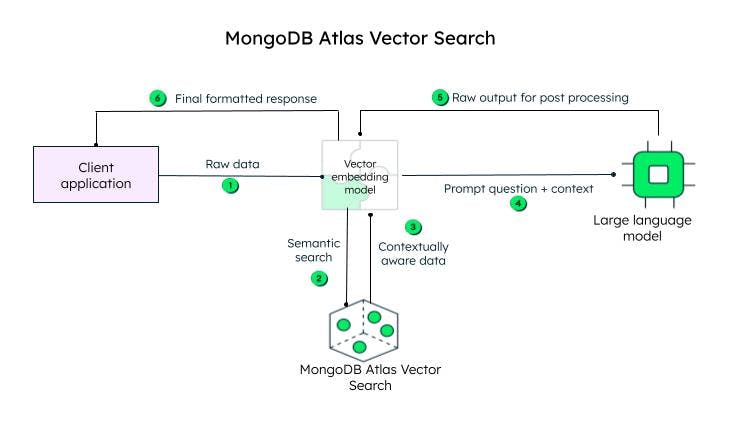 Steps to achieve vector search in MongoDB Atlas
Steps to achieve vector search in MongoDB Atlas
Vector embeddings can be stored in the MongoDB database document as an array of floats, along with the content, in the content_embeddings field.
_id: ObjectId('5091233df3f4925bd2f00371'),
name: "sample_data",
...... other fields......,
content: <unstructured data>,
content_embeddings: [0.9854344343432, 0.45255689075, -0.569745879343, ......]If the number of dimensions in the input data is higher, the number of floating points will be higher.
Next, you define the index definition by adding it to the definition builder:
{
"mappings": {
"fields": {
"content_embedding": {
{
"type": "knnVector",
"dimensions": 1536,
"similarity": "<euclidean | dotProduct | cosine>"
}
}
}
}
}The index definition includes the model that would find the similarity clusters, the dimensions, and the similarity function (out of the three methods supported by MongoDB) that would be used by the model.
That’s about it! Just two steps and you are done.
To be able to search, you can use the $search aggregation operator by specifying knnBeta operator and giving the vector embeddings of the query in the vector field. You should also specify the path of the content embeddings that should be looked upon for the vector search. MongoDB also provides additional filters to narrow down the search, and the number of nearest neighbors that the k-nearest neighbor algorithm should return.
[{
"$search": {
"knnBeta": {
//encoded query vectors
"vector": [0.983428349, -0,4234982300, 0.23023840922...............],
"path": "content_embedding",
"filters": {},
"k": <integer_value_of_num_of_nearest_neighbors>
}
}
}]Since both the vector embeddings and data reside in the same platform, you can access your operational workload and vectors using a single unified MongoDB Query API. To learn to use the functionality step by step, refer to our tutorial on building generative AI apps using vector search.
Important AI use cases
AI is being successfully applied in various domains, including retail, healthcare, and manufacturing. Some popular use cases of AI are:
Natural language processing (NLP): AI is actively used in sentiment analysis, virtual assistants, chatbots, speech recognition, and text translation. As we have seen above, using the power of LLM and vector search, AI systems can produce output in human language.
Computer vision: With modern neural networks in place, AI systems are able to accurately perform image classification, face and object recognition, and image generation.
Recommendation systems and content filtering: AI systems are able to recommend content to users using deep learning and machine learning models without any human intervention.
Healthcare: Artificial intelligence technology has taken healthcare to a new level by aiding doctors in early diagnosis of diseases, medical research and drug discovery, and securely storing the electronic health records of patients.
Self-driving cars: Self-driving cars are powered by AI algorithms, sensor data, and computer vision.
Robotics: Industrial robots are increasing productivity by performing complex tasks with accuracy. Similarly, service robots are able to perform their tasks efficiently in healthcare and hospitality domains.
Ethical use of AI, AI governance, and regulations
With rapid developments happening in the field of AI, it is important to set rules and regulations and address the ethical considerations, so that AI systems are used fairly, transparently, and for the right purpose.
AI ethics focuses on the moral and ethical implications of AI tools and technologies—i.e., fairness, privacy, transparency, and accountability.
The frameworks, structure, and compliance rules are set by the government to regulate AI and ensure the responsible use of AI.
The government also creates AI regulations—i.e., legal frameworks—to ensure data security, consumer protection, and safety standards are taken care of.
AI tools and services
Data is the core of all AI operations, and MongoDB is a platform you can rely on to build powerful AI apps. As a database with a flexible schema, MongoDB provides a centralized storage solution, with in-built data management capabilities, advanced data processing, real-time analytics, scalability, and much more. Some other popular tools and services are:
ChatGPT: ChatGPT has almost become part of everyday life for asking simple questions to planning vacations, coding, writing poetry, and summarizing texts.
Dall-E 2: Dall-E 2 is an OpenAI project, just like ChatGPT, and generates computer graphics like images, paintings, and drawings from text prompts.
Stable Diffusion 2: This is a text-to-image AI tool for generative AI applications. Unlike OpenAI tools, which are accessed through browser portals, Stable Diffusion 2 is available for download and installation, and users can access the source code and algorithms publicly.
FAQs
What is artificial intelligence (AI)?
The ability of machines to think, learn, and make decisions, like a human being, when faced with different scenarios, is known as artificial intelligence.
How does AI work?
Why is artificial intelligence important?
AI is important as it can enable automation of mundane and repetitive tasks, improve efficiency, reduce human errors, provide predictive analytics for faster and more accurate decision making, provide personalized recommendations for users, assist in diagnosis of diseases, accelerate research in medicine and science, and promote innovation.