Picture your city’s power grid. It supplies electricity to all of the homes and businesses in the area, making it essential for every single person. Now, imagine that a transformer in one neighborhood experiences a fault and temporarily goes offline. Ideally, the power grid can reroute electricity from other sources to compensate for the fault. This ensures that all homes and businesses continue to receive electricity without prolonged disruptions.
This analogy helps us understand the concept of high availability (HA) and why it's so important in keeping a system or application running smoothly.
Let's discuss what high availability is, why it's so important to have a backup operational mode, and how you can begin to measure the availability of your critical systems.
Table of contents
The definition of high availability
Let's start at the beginning: What is high availability? High availability means that we eliminate single points of failure so that should one of those components go down, the application or system can continue running as intended.
In other words, there will be minimal system downtime — or, in a perfect world, zero downtime — as a result of that failure.
In fact, this concept is often expressed using a standard known as "five nines," meaning that 99.999% of the time, systems work as expected. This is the (ambitious) desired availability standard that most of us are aiming for.
However, it’s worth noting some companies may have different availability targets, such as four nines (99.99%), three nines (99.9%), and two nines (99%). These tiers represent varying levels of availability commitment.
What you need to make it a reality
Two important aspects of high availability are (1) a data failover system and (2) data backup. To achieve high availability, the system has to have a way to maintain its functionality — by, for example, storing data — when things don't go according to plan.
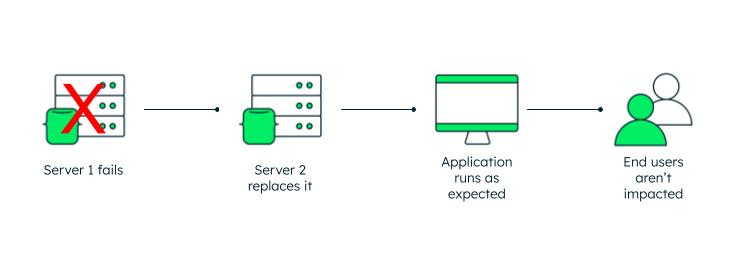
In the example we provided earlier, the single point of failure is the transformer that went down. The city (hopefully) prepared for this with another transformer that can seamlessly pick up the slack.
Other examples of single points of failure that you might be able to relate to include routine server maintenance, network failure, hardware failure, software failure, and even power outages caused by natural disasters.
All of these can lead to service disruption and hamper a system's performance, sometimes significantly.
What about high-availability clusters?
We can also speak more specifically about high-availability clusters, which are groups of servers that work together as one system. While these servers share storage, they're on different networks.
High-availability clusters have failover capabilities, which means that if one of the servers goes down, there's a backup component that can take its place.
Fault tolerance
When people talk about high availability, you might also hear "fault tolerance" used interchangeably. Essentially, they refer to the same concept.
Fault tolerance means that if one or more components within a system fail, there's a backup component ready to automatically take over, ensuring the system can maintain continuous availability, keeping users' access steady without interruption.
The backup components in a fault-tolerant system can include alternatives such as hardware, software, or power sources.
Why is high availability important?
Removing single points of failure and achieving high availability and fault tolerance is so important because this ensures that systems are able to operate continuously for the end user without disruption. It's part of a company's greater disaster recovery protocol, which defines exactly how they plan to minimize downtime and loss in the event of significant downtime.
In fact, having high availability should mean that you're able to avoid downtime almost completely and, thus, the need for disaster recovery.
"Well, all systems experience downtime at some point, right?" Maybe, but the point is that some companies simply can't allow this to happen.
High availability extends beyond providing a positive user experience, preventing productivity losses, and safeguarding a brand’s reputation. It is a critical safeguard against potential disasters.
Examples of high-availability systems
Imagine using the self-driving mode in an electric car, and due to a single point of failure, the entire system shuts down. In other words, the car — which was previously doing 80mph down the expressway — suddenly loses all control. Would you want to be sharing the road with that driver or be behind the wheel yourself?
This might seem like an extreme example (although it's completely feasible). However, some industries rely on high-availability systems to keep their data — and the people it belongs to — safe.
Think of electronic health records (EHRs) — real-time, digitized charts containing all of the information about a patient that their healthcare providers want to keep track of. We're talking about their diagnoses, medical history, prescriptions, vaccinations, you name it.
If those EHRs aren't built on high-availability architecture, and there's some sort of system failure, we might be looking at massive data loss at best, and at worst, the exposure of that very sensitive data.
This underscores the critical importance of working with high-availability infrastructure to maintain the integrity and security of vital data.
How high availability works
In reality, no system can achieve 100% availability at all times. However, to achieve the rule of five nines and build an HA system, there are four key pillars of high availability that we must make a priority.
1. Eliminating single points of failure
As we mentioned earlier, eliminating single points of failure is key in a high-availability system. Without this safeguard, if everything was running on one server, and that server failed, the whole system would go down.
2. Implementing reliable redundancy
“Redundancy" means having backup components within the HA system. That way, if the original component fails, its "twin" can take over for it, helping to minimize downtime caused by the failure and maintain high availability.
3. Facilitating system failure detection
In the event of a component failure within the primary system, there should be clear protocols in place so that (1) the failure is obvious and documented and (2) ideally, the component can resolve the issue on its own. This is an important part of disaster recovery.
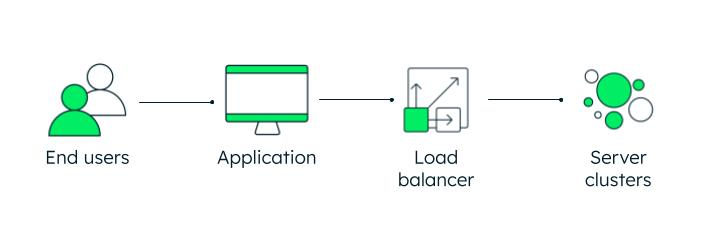
4. Achieving load balancing
Load balancing means that workloads — like network traffic — are distributed across multiple systems or servers in an efficient manner. The load balancer should be able to identify the most productive way to do this. With load balancing, no one resource or server will become overwhelmed with its workload, and high availability becomes more feasible.
The load balancer will accomplish this based on a number of algorithms.
All four of these elements are necessary for maintaining high availability.
How to measure high availability
If you can't track and measure it, then you can't know if it's working. So, how can you measure availability?
The answer isn't totally clear-cut, but the rule of five nines is a good place to start. With companies aiming to be up, running, and available 99.999% of the time, that has become the high availability industry standard against which many complex systems are compared.
However, when measuring high availability architecture, we have to be more specific than this. For example, do you expect to hit 99.999% service availability 24 hours a day, 365 days a year? Or, does high availability only really matter during your business hours?
A little math
If you intend to maintain high availability 99.999% of the time, 24/7/365, that would mean a maximum of 5.256 minutes of yearly downtime.
This is how we got here:
- There are 60 minutes/hour x 24 hours/day x 365 days/year = 525,600 minutes/year
- 99.999% = 0.99999
- 0.99999 x 525,600 minutes = 525,594.744 minutes
- 525,600 minutes - 525,594.744 minutes = 5.256 minutes
Now, if you cared more about maintaining high availability only during operating hours, the numbers for your desired maximum amount of downtime would look different!
Measuring availability can become incredibly complex, but it largely comes down to determining the maximum availability you're aiming for and when specifically it matters most that you have a high-availability solution.
When does high availability matter most?
We can take measuring high availability one step further. Even if your goal is to maintain peak operational performance 24/7/365, we're going to guess that like in most applications, you experience variations in user activity.
Maybe you see higher traffic during weekday mornings, and then it dips significantly on the weekends. Are you still going to shoot for high availability of 99.999% at all times, or for those low-traffic hours, will something around 99.95% suffice?
These numbers might not seem all that different but if you do the math, it can indeed change what your definition of "high availability" (HA) is and what your goals for operational performance are.
High availability in MongoDB
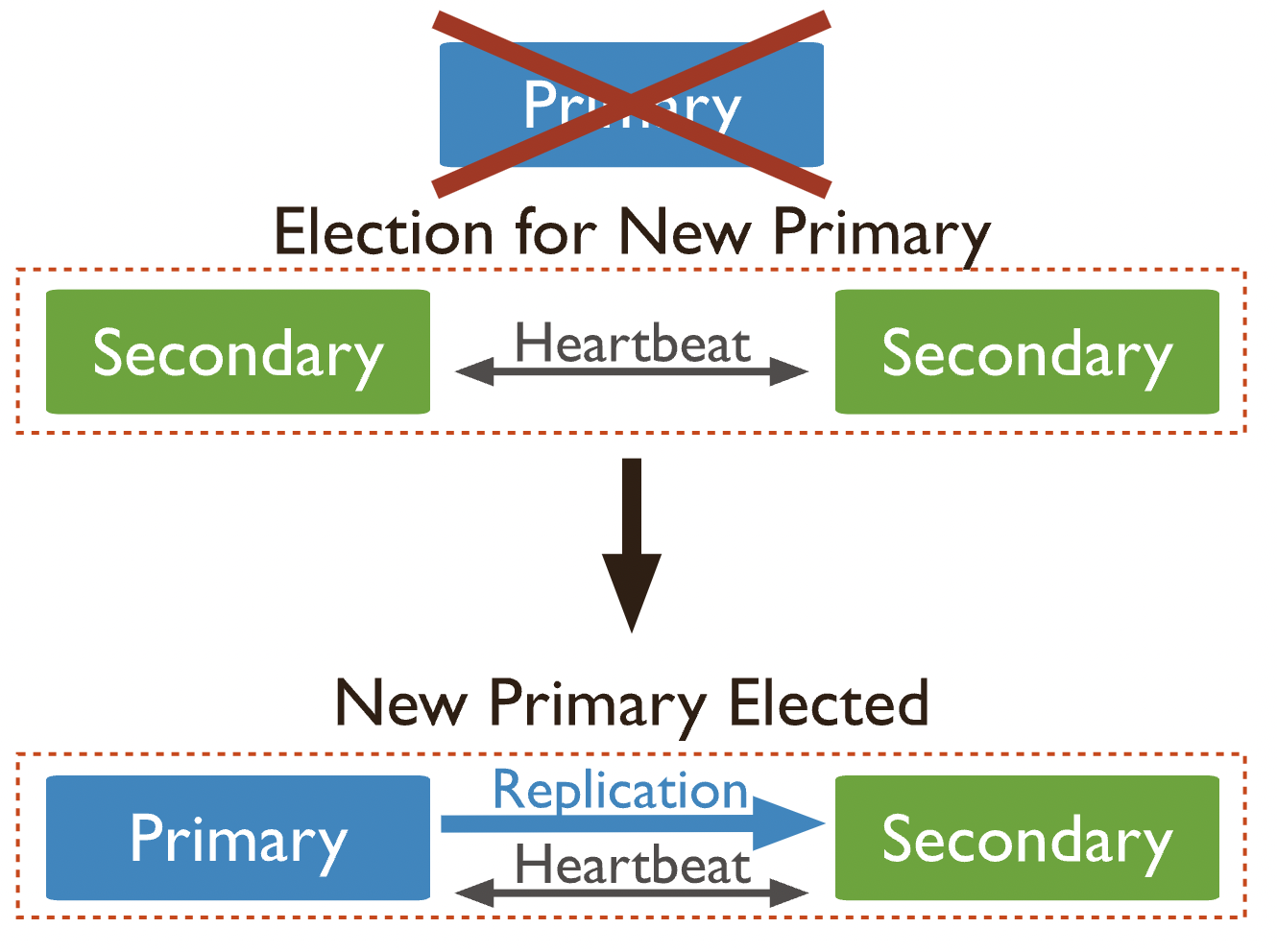
If you're developing an application with MongoDB, how can you achieve high-availability architecture? Replica sets use elections to achieve this.
Elections determine which set member will become the primary. For example, if the primary node becomes unavailable and triggers the automatic failure process, one of the remaining secondary nodes will call for an election to determine the new primary node, after which normal operational performance will automatically resume.
FAQs
What is high availability?
High availability means that points of failure are eliminated so that should one of those components go down, the application or system can continue running as intended.
What is a high-availability cluster?
High-availability clusters are groups of servers that work together as one system. While these servers share storage, they're on different networks.
How does high availability work?
High availability requires points of failure to be eliminated, the establishment of reliable redundancy through duplication of components, the implementation of mechanisms for easy detection and resolution of system failures, and the efficient routing of traffic across systems or servers using load balancers.